Algorithms for variable length Markov chain modeling
190 likes | 344 Views
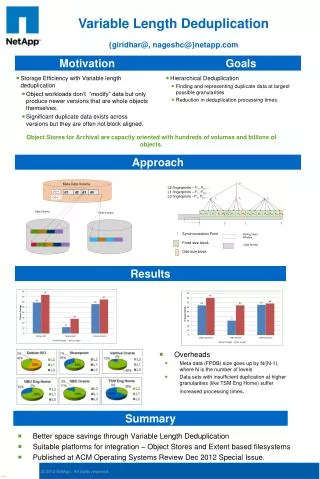
Algorithms for variable length Markov chain modeling. Author: Gill Bejerano Presented by Xiangbin Qiu. Review of Markov Chain Model. Often used in bioinformatics to capture relatively simple sequence patterns, such as genomic CpG islands. Problem.

Algorithms for variable length Markov chain modeling
E N D
Presentation Transcript
Algorithms for variable length Markov chain modeling Author: Gill Bejerano Presented by Xiangbin Qiu
Review of Markov Chain Model • Often used in bioinformatics to capture relatively simple sequence patterns, such as genomic CpG islands.
Problem • The low order Markov chains are poor classifiers • Higher order chains are often impractical to implement or train. • The memory and training set size requirements of an order-k Markov chain grow exponentially with k!
Variable length Markov Model (VMM) • The models are not restricted to a predefined uniform depth (e.g. order-k). • The model is constructed that fits higher order Markov dependencies where such contexts exist, while using lower order Markov dependencies elsewhere. • The order is determined by examining the training data.
Description of Author’s Work • Four main modules are implemented: • Train • Predict • Emit • 2pfa
Probabilistic Suffix Tree (PST) • A special tree data structure
PST-Definitions • Σ the alphabet, string set: i= 1, 2 ..m • Empirical probability: • Conditional empirical probability:
Parameters • Minimum probability: • Smoothing factors: • Memory length: L • Difference measure parameter: r
Incremental Model Refinement • ↑ • L ↑ • r → 1
Results and Discussion • When averaged over all 170 families, the PST detected 90.7% of the true positives. • Much better than a typical BLAST search, and comparable to an HMM trained from a multiple alignment of the input sequences in a global search mode.
Why Significant? • While performance comparable to HMM models • Built in a fully automated manner • Without multiple alignment • Without scoring matrices • Less demanding than HMMs in terms of data abundance and quality
Future Work • An additional improvement is expected if a larger sample set is used to train the PST. Currently the PST is built from the training set alone. • Obviously, training the PST on all strings of a family should improve its prediction as well.