Download
1 / 1
10 likes | 129 Views
1-Q-26 LSA に基づく One-Class SVM を用いた音声認識仮説の検証. 松本 智彦, 佐古 淳, 滝口 哲也, 有木 康雄 ( 神戸大 ). 研究背景・目的. アプローチ. ・音声認識器による不適切な文書の湧き出し ・現在の音声認識は音響モデルと言語モデルのみに基づく ・自動的に不適切な文書を検出し,訂正する手法を提案. ・書き起こし文書を適切な文書とし,その特徴ベクトルを One-Class SVM により学習 ・仮説文が学習で求まったクラスに含まれるかどうかで 適切な文書か識別. 検証. 音声.

E N D
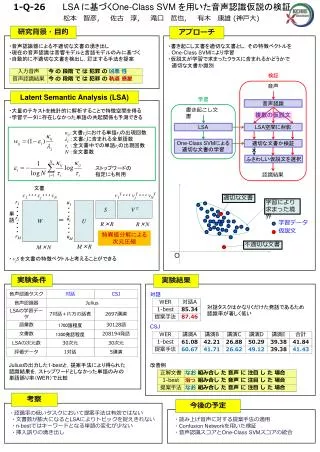
1-Q-26LSA に基づくOne-Class SVM を用いた音声認識仮説の検証 松本 智彦, 佐古 淳, 滝口 哲也, 有木 康雄 (神戸大) 研究背景・目的 アプローチ ・音声認識器による不適切な文書の湧き出し ・現在の音声認識は音響モデルと言語モデルのみに基づく ・自動的に不適切な文書を検出し,訂正する手法を提案 ・書き起こし文書を適切な文書とし,その特徴ベクトルを One-Class SVMにより学習 ・仮説文が学習で求まったクラスに含まれるかどうかで 適切な文書か識別 検証 音声 Latent Semantic Analysis (LSA) 学習 音声認識 ・大量のテキストを統計的に解析することで特徴空間を得る ・学習データに存在しなかった単語の共起関係も予測できる 文書 単 語 ・ vjSを文書の特徴ベクトルと考えることができる 書き起こし文書 複数の仮説文 LSA LSA空間に射影 κij:文書cjにおける単語riの出現回数 λj :文書cjに含まれる全単語数 τi :全文書中での単語riの出現回数 N :全文書数 One-Class SVMによる適切な文書の学習 適切な文書か検証 × ふさわしい仮説文を選択 ストップワードの指定にも利用 認識結果 c1・・・ cj・・・ cN v1T・・・ vjT・・・ vNT 適切な文書 学習により 求まった境界 W U S VT r1 ・ ・ ・ ri ・ ・ ・ rM u1 ・ ・ ・ ui ・ ・ ・ uM = 学習データ R×R R×N 仮説文 特異値分解による次元圧縮 不適切な文書 M×R M×N O 実験条件 実験結果 Juliusの出力した1-bestと,提案手法により得られた 認識結果を,ストップワードとしなかった単語のみの 単語誤り率(WER)で比較 対話 対話タスクはかなりくだけた発話であるため 認識率が著しく低い CSJ 改善例 考察 今後の予定 ・認識率の低いタスクにおいて提案手法は有効ではない ・文書数が膨大になるとLSAによりトピックを捉えきれない ・n-bestではキーワードとなる単語の変化が少ない ・挿入誤りの湧き出し ・読み上げ音声に対する提案手法の適用 ・Confusion Networkを用いた検証 ・音声認識スコアとOne-Class SVMスコアの統合