Bias-Variance Tradeoffs in Program Analysis
This paper explores the intricate relationship between bias and variance in program analysis, emphasizing the impact of increased precision on results. It highlights how program behaviors can be unbounded and the necessity for finite observations to generalize effectively. By employing a Probably Approximately Correct (PAC) learning model, the authors present a framework for understanding generalization in program analysis. Key contributions include strategies for tuning program analysis tools and the implications of overfitting, supported by empirical studies and case analyses.


Bias-Variance Tradeoffs in Program Analysis
E N D
Presentation Transcript
Rahul Sharma, Aditya V. Nori, Alex Aiken Stanford MSR India Stanford Bias-Variance Tradeoffs inProgram Analysis
Observation inti = 1, j = 0; while (i<=5) { j = j+i; i= i+1; } • Invariant inference • Intervals • Octagons • Polyhedra Increasing precision D. Monniaux and J. L. Guen. Stratified static analysis based on variable dependencies. Electr. Notes Theor. Comput. Sci. 2012
Another Example: Yogi A. V. Nori and S. K. Rajamani. An empirical study of optimizations in YOGI. ICSE (1) 2010
The Problem • Increased precision is causing worse results • Programs have unbounded behaviors • Program analysis • Analyze all behaviors • Run for a finite time • In finite time, observe only finite behaviors • Need to generalize
Generalization • Generalization is ubiquitous • Abstract interpretation: widening • CEGAR: interpolants • Parameter tuning of tools • Lot of folk knowledge, heuristics, …
Machine Learning • “It’s all about generalization” • Learn a function from observations • Hope that the function generalizes • Work on formalization of generalization
Our Contributions • Model the generalization process • Probably Approximately Correct (PAC) model • Explain known observations by this model • Use this model to obtain better tools http://politicalcalculations.blogspot.com/2010/02/how-science-is-supposed-to-work.html
Why Machine Learning? Interpolants classifiErs + - - - + + - + - + Rahul Sharma, Aditya V. Nori, Alex Aiken: Interpolants as Classifiers. CAV 2012
PAC Learning Framework c • Assume an arbitrary but fixed distribution • Given (iid) samples from • Each sample is example with a label (+/-) + - - - + + - + - +
PAC Learning Framework + - - - + + - + - + • Empirical error of a hypothesis
PAC Learning Framework c + - - - + + - + - + • Empirical risk minimization (ERM) • Given a set of possible hypotheses (precision) • Select that minimizes empirical error
PAC Learning Framework • Generalization error: for a new sample • Relate generalization error to empirical error and precision
Precision + + • Capture precision by VC dimension (VC-d) • Higher precision -> More possible hypotheses - - + + + + H For any arbitrary labeling
VC-d Example + + + + + + - - - - - - - - - - - - + + + + + + + + + - + - - -
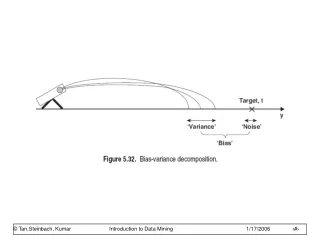
Regression Example Precision is low Underfitting Y X Precision is high Overfitting Good fit
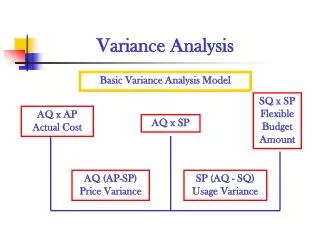
Main Result of PAC Framework • Generalization error is bounded by sum of • Bias: Empirical error of best available hypothesis • Variance: O(VC-d) Generalization error Variance Bias Possible hypotheses Increase precision
Example Revisited • Invariant inference • Intervals • Octagons • Polyhedra inti = 1, j = 0; while (i<=5) { j = j+i; i= i+1; }
Intuition • What goes wrong with excess precision? • Fit polyhedra to program behaviors • Transfer functions, join, widening • Too many polyhedra, make a wrong choice inti = 1, j = 0; while (i<=5) { j = j+i ; i = i+1; } Intervals: Polyhedra:
Abstract Interpretation J. Henry, D. Monniaux, and M. Moy. Pagai: A path sensitive static analyser. Electr. Notes Theor. Comput. Sci. 2012.
Yogi A. V. Nori and S. K. Rajamani. An empirical study of optimizations in YOGI. ICSE (1) 2010
Case Study • Parameter tuning of program analyses • Overfitting? Generalization on new tasks? Train Benchmark Set (2490 verification tasks) Tuned , test length =500, … P. Godefroid, A. V. Nori, S. K. Rajamani, and S. Tetali. Compositional may-must program analysis: unleashing the power of alternation. POPL 2010.
Cross Validation • How to set the test length in Yogi Benchmark Set (2490 verification tasks) Train Training Set (1743) Test Test Set (747)
Cross Validation on Yogi • Performance on test set of tuned ’s 350 500
Comparison • On 2106 new verification tasks • 40% performance improvement! • Yogi in production suffers from overfitting
Recommendations • Keep separate training and test sets • Design of the tools governed by training set • Test set as a check • SVCOMP: all benchmarks are public • Test tools on some new benchmarks too
Increase Precision Incrementally • Suggests incrementally increasing precision • Find a sweet spot where generalization error is low R. Jhala and K. L. McMillan. A practical and complete approach to predicate refinement. TACAS 2006.
More in the paper • VC-d of TCMs: intervals, octagons, etc. • Templates: • Arrays, separation logic • Expressive abstract domains -> higher VC-d • VC-d can help choose abstractions
Inapplicability • No generalization -> no bias-variance tradeoff • Certain classes of type inference • Abstract interpretation without widening • Loop-free and recursion-free programs • Verify a particular program (e.g., seL4) • Overfit on the one important program
Conclusion • A model to understand generalization • Bias-Variance tradeoffs • These tradeoffs do occur in program analysis • Understand these tradeoffs for better tools