Download
1 / 17
170 likes | 393 Views
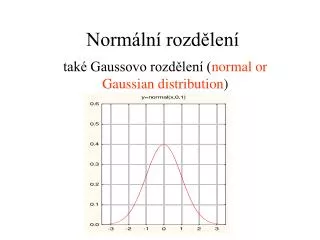
Normální rozdělení. také Gaussovo rozdělení ( nor m al or Gaussian distribution ). Hustota pravděpodobnosti . střední hodnota rozdělení je . platí -. variance rozdělení je 2.

E N D
Normální rozdělení také Gaussovo rozdělení (normal or Gaussian distribution)
Hustota pravděpodobnosti střední hodnota rozdělení je platí - variance rozdělení je 2
Je tu jistá nedůslednost - značí jak obecně střední hodnotu, tak specificky parametr normálního rozdělení (který je ovšem také střední hodnotou, podobně pro 2 Klíčové postavení normálního rozdělení ve statistice vyplývá z centrální limitní věty. Vyplývá z ní, že průměr “velmi velkého” náhodného výběru je náhodnou veličinou s přibližně normálním rozdělením, i když má základní soubor rozdělení jiné než normální.
přes 95% pozorování 97,5% kvantil N(0,1)=1,96 cca 68% pozorování
Z “definice” - proměnná s normálním rozdělením může s nenulovou pravděpodobností nabývat hodnot od - do + Biologické proměnné většinou normální rozdělení nemají, ale můžeme je často normálním rozdělením “rozumně” aproximovat.
Protože hodnoty hustoty pravděpodobnosti i distribuční funkce normálního rozdělení jsou známy, můžeme (jako určitý integrál) pro dané parametry (μ, σ2) spočítat pravděpodobnost, že se budenáhodná proměnná nacházet v daném intervalu.
Šikmost a špičatost i-tý obecný moment - průměrná hodnota Xi i-tý centrální moment, κi - průměrná hodnota (X- )i Střední hodnota je tedy první obecný moment První centrální moment je z definice 0 Variance je druhý centrální moment Šikmost je charakterizována třetím centrálním momentem Špičatost čtvrtým centrálním momentem
Šikmost Pozitivně šikmé - mnoho malých negativních odchylek od průměru je kompenzováno menším množstvím velkých pozitivních odchylek: 3, 3, 3, 4, 7 μ=4 3={(3-4)3+ (3-4)3+ (3-4)3+ (4-4)3+ (7-4)3}/5={(-1)+(-1)+(-1)+0+27}/5=24/5=4.8 3 - je ve třetích mocninách jednotky měření - je bezrozměrné a udává pouze tvar
Šikmost Negativně šikmé rozdělení - mnoho malých pozitivních odchylek od střední hodnoty kompenzováno malým množstvím velkých negativních odchylek 5, 5, 5, 1, 4 μ=4 3={(5-4)3+ (5-4)3+ (5-4)3+ (4-4)3+ (1-4)3}/5 ={1+1+1+0+(-27)}/5=-24/5=-4.8
Špičatost - 4. centrální moment Normální rozdělení je mesokurtické, normální - mesokurtické leptokurtické 2 > 0 platykutické 2 < 0
“Ověřování“ normality - grafické Vynést kumulativní histogram četností na pravděpodobnostní stupnici
Ověřování normality - spočtu šikmost a špičatost a porovnám s očekávanými hodnotami pro normální distribuci. Věršina biologických dat má pozitivně šikmé rozdělení - proto spočtení šikmosti dává často dost silný test, a zároveň nám říká, jak se data liší od normality.
Ověřování normality - test dobré shody χ2 Spočtu průměr a varianci z dat, a porovnám získaná data s daty s normálním rozdělením, které má stejný průměr a stejnou varianci, jako moje data. Pak pomocí χ2 testu porovnám počty případů velikostních třídách vytvořených z pozorovaných dat, a očekávané frekvence v normálním rozdělení - klasické problém, musím rozhodnout o šíři kategorií (šíři sloupečků v histogramu) - počet stupňů volnosti = k-1-2 2 parametry z dat
Očekávané četnosti jsou příliš nízké, obvykle se sousední sloupečky spojují (default ve Statistice je, když E<5) – to může občas vést k problémům
Editoři časopisů občas takový test vyžadují, ale • (skoro) žádná biologická data nemají normální rozdělení, takže • když mám hodně dat, test je silný, a nulovou hypotézu o normalitě zamítnu (i v případě, že odchylka od normality je malá) • když mám málo dat, test je zoufale slabý, a i pro data s velkou odchylkou od normality nemohu zamítnout nulovou hypotézu