
LL(1) 分析法
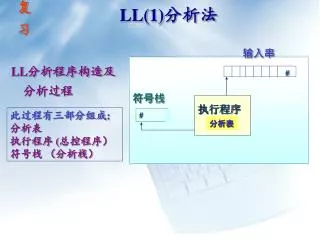
复 习. LL(1) 分析法. 输入串. #. LL 分析程序构造及分析过程. 符号栈. 执行程序. 此过程有三部分组成 : 分析表 执行程序 ( 总控程序) 符号栈 (分析栈). #. 分析表. E→TE’ E’→+TE’|ε T→FT’ T’→*FT’|ε F→(E)|i. FIRST(F)={(,i} FIRST(T’)={*,ε} FIRST(T)={(,i} FIRST(E’)={+,ε} FIRST(E)={(,i}. FOLLOW(F)={*,+,),#}

LL(1) 分析法
E N D
Presentation Transcript
复 习 LL(1)分析法 输入串 # LL分析程序构造及分析过程 符号栈 执行程序 此过程有三部分组成: 分析表 执行程序 (总控程序) 符号栈 (分析栈) # 分析表
E→TE’ E’→+TE’|ε T→FT’ T’→*FT’|ε F→(E)|i FIRST(F)={(,i} FIRST(T’)={*,ε} FIRST(T)={(,i} FIRST(E’)={+,ε} FIRST(E)={(,i} FOLLOW(F)={*,+,),#} FOLLOW(T’)={+,),#} FOLLOW(T)={+,),#} FOLLOW(E’)={#,)} FOLLOW(E)={#,)} 求SELECT SELECT(E→TE’)={ (,i } SELECT(E’→+TE’)={ + } SELECT(E’→ ε)={ ),# } SELECT(T→FT’)={ (,i } SELECT(T*FT)={*} SELECT(T’→ε)={ +,),# } SELECT (F→(E)={ ( } SELECT (F→i)={ i }
例:文法G[E] E::= E +T | T T::= T * F | F F::=(E)|i 请用自顶向下的方法分析是否字符串i+i*i∈L(G[E])。 E::=TE’ E’::=+TE’|ε T ::=FT’ T’::=*FT’|ε F::=(E)|i 消除左递归 分析表 3 3 注:矩阵元素空白表示Error
输入串为: i+i*i# 步骤 符号栈 读入符号 剩余符号串 使用规则 1. #E E# i +i*i# 2. #E’T TE’# i +i*i# E::=TE’ 3. #E’T’F FT’E’# i +i*i# T::=FT’ 4. #E’T’ i iT’E’# i +i*i# F::= i 5. #E’T’ T’E’# + i*i# (出栈,读下一个符号) 6. #E’ E’#+ i*i# T::= ε 7. #E’T+ +TE’#+ i*i# E::=+TE’
步骤 符号栈 读入符号 剩余符号串 使用规则 8. #E’T i *i# 9. #E’T’F i *i# T::=FT’ 10. #E’T’ i i *i# F::= i 11. #E’T’ * i# 12. #E’T’F* * i# T’::=*FT’ 13. #E’T’F i # 14. #E’T’ i i # F::= i 15. #E’T’ # 16. #E’ # T’::= ε 17. # # E’::= ε 输入串为: i+i*i# 5 5
4.2 自底向上分析 4.2.1 移进-归约分析 (自底向上分析的一般过程) 4.2.2 优先分析法 4.2.3 LR分析法
若Z S 则 S L(G[Z]) 否则 S L(G[Z]) + G[Z] 若Z S 则 S L(G[Z]) 否则 S L(G[Z]) + G[Z] 自顶向下分析算法的基本思想为: 存在主要问题: • 左递归问题 • 回溯问题 • 主要方法: • 递归子程序法 • LL分析法 自底向上分析算法的基本思想为: • 存在主要问题: • 句柄的识别问题 • 主要方法: • 算符优先分析法 • LR分析法
自底向上分析 基本算法: 若采用自左向右的描述和分析输入串,那么自 底向上的基本算法是: 从输入符号串开始,通过重复查找当前句型的 句柄(最左直接短语),并利用有关规则进行规约, 若能规约为文法的开始符号,则表示分析成功,输 入符号串是文法的合法句子,否则有语法错误。
输入串 # 符号栈 L.R.P # 4.2.1 移进—归约分析(Shift-reduce parsing) 要点:建立符号栈,用来纪录分析的历史和现状,并根据所面临的状态,确定下一步动作是移进还是归约。
例:G[S]: S→AcBe A→b A→Ab B→d 输入串为bbcde,检查是否是该文法的合法句子。 若采用自底向上分析,即能否一步步归约当前句型的句柄,最终规约到开始符号S。先设立一个符号栈,我们统一符号“#”作为待分析的符号串的左右分界符。 作为初始状态,先将符号串的分界符推进符号栈,作为栈底符号。 分析过程如下表:
例:G[S]: S→AcBe A→b A→Ab B→d 1 # bbcde# 移进 2 #b bcde# 归约(Ab) 3 #A bcde# 移进 4 #Ab cde# 归约(AAb) 5 #A cde# 移进 6 #Ac de# 移进 7 #Acd e# 归约(Bd) 8 #AcB e# 移进 9 #AcBe # 归约(SAcBe) 10 #S # 接受
这一方法简单明了,不断地进行移进归约, 关键是确定当前句型的句柄. S A A A B B A A A A b b b b b b c d c d e b a) b) c) d) 说明:例子的分析过程是一步步地归约当前句型的句柄 该句子输入串为bbcde的 语法树的构造过程为: 例:G[S]: S→AcBe A→b A→Ab B→d
基本问题 • 检查是否为句柄—归约条件 • 选用哪一条规则进行归约—归约原则
4.2.2 算符优先分析法概述 • 算符优先文法 • 算符优先分析是一种分析过程比较迅速的自底向上的分析方法,特别有利于表达式的分析,便于手工实现。它不是一种严格的最左归约,即不是一种规范归约方法。在算符优先分析方法中,可归约串就是最左素短语。 • 所谓算符优先就是借鉴了程序语言中,表达式运算的不同优先顺序,在算符,即非终结符之间定义某种优先归约的关系,从而在句型中寻找可归约串。由于非终结符关系的定义和普通算术表达式的算符(如加减乘除)运算的优先关系一致,所以得名算符优先分析方法。 14
优先关系 • a≐b 表示a的优先级等于b的优先级 • a⋖b 表示a的优先级小于b的优先级 • a⋗b 表示a的优先级大于b的优先级 • 说明 • 为了方便,假设文法中不含形如P的规则 15
算符文法 • 如果某文法G中没有形如ABC的产生式,这里A, B, CVN,则成文法G为算符文法,也称OG文法。 16
优先关系定义 • 设文法G是不含产生式的算符文法,a, b是任意两个终结符,而A, B, CVN,则优先关系定义如下: • a≐b 当且仅当G中存在产生式Aab或 • AaBb • a⋖b 当且仅当G中存在产生式AaB,且 • Bb或BCb • a⋗b 当且仅当G中存在产生式ABb,且 • Ba或BaC + + + + 17
算符优先文法 • 如果一个算符文法G中的任何两个终结符a, b至多只满足下述三种关系之一: a≐b a⋖b a⋗b • 则称文法G是一个算符优先文法,也称OPG文法。 18
例 • 考虑文法G[E]: EE+T|T TT*F|F F(E)|i 找出终结符间的优先关系矩阵。 19
FIRSTVT() • P是文法G的任意一个非终结符号 • FIRSTVT(P) • = { a | P=+>a…或 P=+>Qa… } • FIRSTVT(P)的构造算法 • 若P->a…或P->Qa…,则a属于FIRSTVT(P) • 若a属于FIRSTVT(Q),且P->Q…,则a属于FIRSTVT(P) 20
LASTVT() • LASTVT(P) • = { a | P=+>…a 或 P=+>…aQ } • LASTVT(P)的构造算法 • 若P->…a或P->…aQ,则a属于LASTVT(P) • 若a属于LASTVT(Q),且P->…Q,则a属于LASTVT(P) 21
算符优先关系表构造算法 • P->..ab…或P->…aQb… • a=b • P->…aR…,且b属于FIRSTVT(R) • a<b • P->…Rb…,且a属于LASTVT(R) • a>b 22
关于#的特别说明 • 文法开始符号S • #S# • #=# • #<FIRSTVT(S) • LASTVT(S)># • 对于算符优先文法,#的优先级小于任何终结符;任何终结符的优先级大于#;#的优先级等于#。 • 由于仅对终结符定义优先关系,未对非终结符号定义算符优先关系,不能使用这些关系查找右单个非终结符号组成的句柄。 23
构造FIRSTVT() • F->(E)|k • FIRSTVT(F) = { (, k } • T->T*F|F • FIRSTVT(T) = { * } U FIRSTVT(F) • = { *, (, k } • E->E+T|T • FIRSTVT(E) = { + } U FIRSTVT(T) • = { +, *, (, k } 24
构造LASTVT() • F->(E)|k • LASTVT(F) = { ), k } • T->T*F|F • LASTVT(T) = { * } U LASTVT(F) • = { *, ), k } • E->E+T|T • LASTVT(E) = { + } U LASTVT(T) • = { +, *, ), k } 25
计算优先关系1 • E -> E+T | T • + < any of FIRSTVT(T) • any of LASTVT(E) > + • T -> T*F | F • * < any of FIRSTVT(F) • any of LASTVT(T) > * 26
计算优先关系2 • F -> (E) | k • ( = ) • ( < any of FIRSTVT(E) • any of LASTVT(E) > ) • #E# • # = # • # < any of FIRSTVT(E) • any of LASTVT(E) > # 27
算符优先关系表 28
最左素短语 • 短语——回忆 • 若文法的开始符号为S,S=*>αAβ,A=+> γ • 则称γ为句型αAβ的一个短语 • 素短语 • 至少含有一个终结符,并且不再含有更小的素短语 • 最左素短语 • 处于句型最左面的素短语 29
Z E E + T F E + T T i T * F 素短语举例 • 句型T+T*F+i的短语有哪些?直接短语有哪些?素短语是什么? • 短语为:T+T*F+i、T+T*F、T*F,以及最左边的T和最右边的i • 直接短语是:T、T*F、i • 素短语为:T*F和 i。 • T+T*F+i,T+T*F不是素短语,因为其中包含了素短语T*F。 • T不是素短语,因为其中没有终结符号。 30
自底向上分析过程的每一步就是寻找句型的最左直接短语(句柄)或者最左素短语,把它们作为可归约串进行归约的。自底向上分析过程的每一步就是寻找句型的最左直接短语(句柄)或者最左素短语,把它们作为可归约串进行归约的。 • 算符优先分析是自底向上的语法分析方法,它在当前的句型中不断地寻找最左素短语并进行归约,直至把输入串扫描完毕并把分析栈归约成文法的开始符号。 • 那么,如何利用算符优先关系和分析栈来识别最左素短语并进行归约呢? 短语 是一个产生式的右部 至少包含一个终结符 直接短语 素短语 最左 LR分析 句柄 最左素短语 算符优先分析 31
算符优先算法 • “归约”素短语 • 最左子串法 • 由于算符优先文法不含两个连续的非终结符,故可以把括在两个#之间的句型的一般性是写成: #N1a1N2a2NnanNn+1an+1# • 其中,ai都是终结符,Nj是非终结符(可有可无)。此时归约的是满足下列条件的最左子串: NjajNj+1aj+1NiaiNi+1 • 满足: • aj-1⋖aj aj≐aj+1≐≐ai ai⋗ai+1 32
算符优先分析法的例子 • 对于上面的算符优先文法,句型i+(i+i)*i的识别过程如下: • #i+(i+i)*i# #⋖i⋗+ i F • #F+(i+i)*i# #⋖+⋖(⋖i⋗+ i F • #F+(F+i)*i# #⋖+⋖(⋖+⋖i⋗) i F • #F+(F+F)*i# #⋖+⋖(⋖+⋗) F+F E • #F+(E)*i# #⋖+⋖(≐) (E) F • #F+F*i# #⋖+⋖*⋖i⋗#i F • #F+F*F# #⋖+⋖*⋗# F*F T • #F+T# #⋖+⋗#F+T E • #E# 接受 33
Z E Z + T F + T E T i T * F F * F F F ( E ) i i ( E ) i F + F E + T i i T F F i i 识别句型i+(i+i)*i得到的语法树 (a) 算符优先分析技术得到得到的语法树 (b) 一般分析技术得到得到的语法树 34
4.2.3 LR分析法的概念 LR(k)分析的基本过程是一种移进-归约的过程。 • LR(K)分析法的含义 • L—自左向右扫描输入串(源程序) • R—分析过程构成最右推导的逆序 • K—每次根据当前的输入符号最多向前(右)查看K个符号就可以唯一地确定下一步动作是移进还是归约以及用哪条规则进行归约,因而也能唯一地确定句柄 35
LR(k)技术包含一组方法:LR(0)、SLR(1)、LR(1)和LALR(1)。LR(k)技术包含一组方法:LR(0)、SLR(1)、LR(1)和LALR(1)。 • LR(0)无需预测输入符号,实现最简单,局限性最大,基本上无法实用,但是它是LR分析的基础。 • 简单的LR,即SLR(1),是一种比较容易实现而且具有使用价值的方法,但是却不能分析一些常见程序语言的结构。 • 规范的LR分析,能够适用于很大一类文法,分析能力最强,构造方法因而也最复杂。 • 对LR(1)的一种改进叫做向前LR分析(简称LALR(1),其中LA是向前look ahead的缩写),它在分析能力和构造工作方面都介于SLR(1)和LR(1),即LALR(1)的使用范围比SLR(1)广泛,实现的工作量也相应地多。 36
LR分析器的逻辑结构 LR分析器组成: • 分析表 • 总控程序 • 下推分析栈 a1a2an# 输入串(源程序) 分 析 栈 输出分 析结果 总控程序 37
分析栈 • 符号栈 • 符号栈内存放分析过程中移进或归约的符号。 • 状态栈 • 状态栈存放的是状态(标记),状态Si概括了栈中位于Si下面的全部信息,也就是记录分析过程从开始的某一归约阶段的整个分析历史或预测扫描可能遇到的分析符号。分析开始时,分析栈压入初始状态S0和输入符号#,分析器处于初始状态S0。S0刻画了当前栈内仅有一个符号#的事实并预示将扫描的输入字符应刚好是可作为句子首符号的那些符号。 38
分析表 • 动作表(ACTION) • 状态转换表(GOTO) 39
ACTION表 • ACTION表的结构如下: 40
分析动作 • ACTION表中的元素ACTION[Sm, ai]是一个动作,表示当前状态Sm面临输入符号ai时所完成的分析动作。分析动作可分四类: • 移进 • 归约 • 接受 • 出错 41
移进 • 此时ACTION[Sm, ai]=‘Sj’。分析动作为移进时,表示句柄尚未在分析栈的栈顶形成,正期待继续移进符号,以形成句柄。 ACTION[Sm, ai]=‘Sj’表示当前栈顶状态为Sm,输入符号为ai,应将输入符号ai移进分析栈的符号栈栈顶,同时将Sj移进分析栈的状态栈栈顶。 42
归约 • 此时ACTION[Sm, ai]=‘rj’。其中rj表示按文法的第j条规则(产生式)进行归约。设第j条规则为: AXm-r+1Xm-r+2 Xm • 分析动作为归约时,表明当前分析栈顶部的符号串Xm-r+1Xm-r+2 Xm已是当前句型的句柄,需要立即进行归约。具体是将分析栈自顶向下的r个符号(包括状态栈内相应的状态)弹出,将A压入符号栈内,此时分析栈格局为: • 下图所示 再以(Sm-r,A)查GOTO表,若GOTO[Sm-r, A]=Sk,把Sk压入状态栈。 43
输入串 a1a2ai an# 当符号栈顶形成句柄β时,把它规约成产生式A→β的左部A:设句柄β的长度为r,归约动作就是①把符号栈顶的r个符号删除,移进符号A;②把状态栈顶的r个状态删除,移进新的状态sj=GOTO[si-m, A]。 44
接受 • 此时ACTION[Sm, ai]=‘acc’。分析动作接受表示当前输入的符号串分析成功,终止分析器工作。 45
出错 • 此时ACTION[Sm, ai]=‘error’(error表示出错,在此用空白来表示)。分析动作为出错,表示当前输入的符号串中有语法错误,调用相应的出错处理程序。 46
GOTO表 • GOTO表的结构如下: 47
状态转换 • GOTO表中的元素GOTO[Sm, Xi]是一个状态,表示当前状态Sm面临输入符号Xi时需转移的下一个状态。 48
总控程序 • 总控程序是LR分析的实现算法。描述如下: • 初始化,将初始状态S0及输入符号串的左界符#推入分析栈; • 从输入串中读入当前的输入符号ai,根据当前状态栈栈顶状态Sm与输入符号ai查ACTION表: • 若ACTION[Sm, ai]=‘Sj’,完成移进动作; • 若ACTION[Sm, ai]=‘rj’,以文法的第j条规则完成归约动作; • 若ACTION[Sm, ai]=‘acc’,分析成功,结束; • 若ACTION[Sm, ai]=‘error’,出错处理。 • 重复2)直到出错或接受为止。 49
接受时分析栈的格局 输入串 a1a2ai an# 50