Download

1 / 18
180 likes | 427 Views
Generalized Inverted Index for Keyword Search Authors: Hao Wu, Guoliang Li, Lizhu Zhou. P resentation B y Manoj Raj Devalla. Introduction. A keyword search is most common type of search.

E N D
Generalized Inverted Index for Keyword SearchAuthors: Hao Wu, GuoliangLi,LizhuZhou Presentation By Manoj Raj Devalla
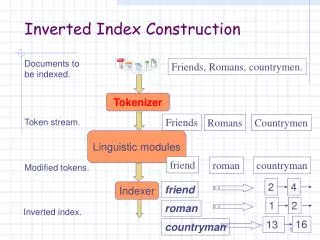
Introduction • A keyword search is most common type of search. • Each time a user queries a search engine it has to search billions of web pages and has to return most among them that matches the criteria. • For example, Google Search. • The most common mechanism used to access text data from keyword based search is Inverted Index.
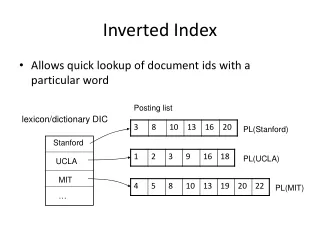
Introduction(Contd.) • An inverted index is an index data structure that stores a mapping of contents to its location within a document. • The fastness of the search is achieved at a cost of increased processing of the document when it is newly added.
Motivation • Inverted file may be large at times. • We need some efficient techniques to reduce the storage space consumed. • Also we need to reduce disk I/O time. • Solution???
Motivation(Contd.) • A new index structure Ginix (Generalized INvertedIndeX) has been proposed to overcome the problems. • It Merges consecutive Doc IDs in inverted file into intervals. • It is also compatible with other techniques such as Variable-Byte Coding, PForDelta etc.
Basic Concepts • Depending upon the algorithm implemented, the inverted lists consist of Document ID’s, number of occurrences and location inside the document. • For example, if Id contains {12, 3, 12, 23, 32} then that keyword has 3 occurrences at location 12, 23, 32 in the document 12.
Related Work • Various compression techniques have been proposed such as Variable-Byte Coding, PForDelta etc. • Variable-Byte Codingis simple to implement but does not achieve a better compression ratio. • In this method, an integer n is compressed as a sequence of bytes.
Variable-Byte Coding • Each byte consists of a status bit that is used to indicate if another byte follows the current byte or not, and 7 data bits. • The status bit will be the most significant bit. • For example, if inverted list contains (12, 25, 39, 279) it will be encoded as follows, 279 = 10000010 00010111
Ginix • Merges document IDs that are consecutive into interval list. • Lists are sorted by ascending order. • An advantage in this scheme is that, the interval list needs only two numbers to identify an interval - a lower boundary lb(r) and upper boundary ub(r). • Unlike other approaches, in Ginix we do not require to decompress the interval list.
Ginix(Contd.) • Sometimes we may end up having same lower boundary and upper boundary number. • In such cases, that list is further divided into three lists. • S, L, U where, • S - Single element intervals. • L - Lower bound multi-element intervals. • U - Upper bound multi-element intervals.
Ginix(Contd.) Table 1 A sample dataset of 7 paper titles.
Ginix(Contd.) Table 2: Traditional Inverted file vs Ginix
Conclusion • Ginix proved to reduce the storage consumption. • Using Ginix, disk I/O time is also reduced. • Ginixis also compatible with other compression techniques. • Overall performance of Ginix is much higher than that of traditional Inverted Index.
Reference [1] Wu Hao, Guoliang Li, Lizhu Zhou. “Ginix: Generalized inverted index for keyword search”. Tsinghua Science and Technology, Vol. 8, Issue 1, pages 77-87, Feb. 2013. [2] HaoYan, Shuai Ding, TorstenSuel. “Inverted index compression and query processing with optimized document ordering”. WWW ’09 Proceeding of the 18th international conference on world wide web, pages 401-410, ACM New York, 2009. [3]http://www.1and1.com/domain-name-search [4]Wikipedia, http://en.wikipedia.org/wiki/Inverted_index. [5]Gavin Powell (2006). "Chapter 8: Building Fast-Performing Database Models". Beginning Database Design ISBN 978-0-7645-7490-0. Wrox Publishing. [6]A. Moffat, J. Zobel. “Inverted files for text search engines”. ACM Computing Surveys, vol. 38, Issue 2, pp. 6, 2006.