Faster!
420 likes | 638 Views
Faster!. Vidhyashankar Venkataraman CS614 Presentation. U-Net : A User-Level Network Interface for Parallel and Distributed Computing. Background – Fast Computing. Emergence of MPP – Massively Parallel Processors in the early 90’s

Faster!
E N D
Presentation Transcript
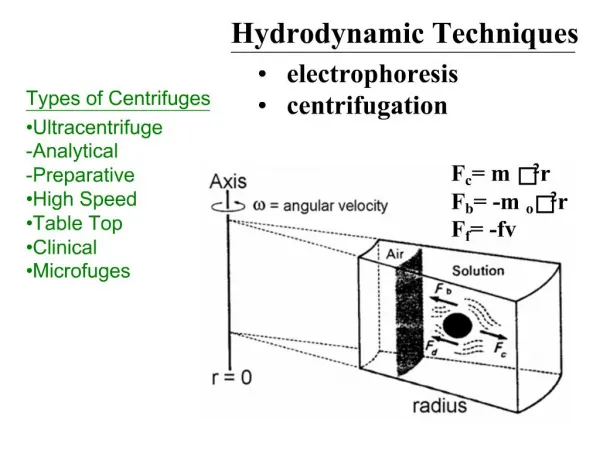
Faster! Vidhyashankar Venkataraman CS614 Presentation
U-Net : A User-Level Network Interface for Parallel and Distributed Computing
Background – Fast Computing • Emergence of MPP – Massively Parallel Processors in the early 90’s • Repackage hardware components to form a dense configuration of very large parallel computing systems • But require custom software • Alternative : NOW (Berkeley) – Network Of Workstations • Formed by inexpensive, low latency, high bandwidth, scalable, interconnect networks of workstations • Interconnected through fast switches • Challenge: To build a scalable system that is able to use the aggregate resources in the network to execute parallel programs efficiently
Issues • Problem with traditional networking architectures • Software path through kernel involves several copies - processing overhead • In faster networks, may not get application speed-up commensurate with network performance • Observations: • Small messages : Processing overhead is more dominant than network latency • Most applications use small messages • Eg.. UCB NFS Trace : 50% of bits sent were messages of size 200 bytes or less
Issues (contd.) • Flexibility concerns: • Protocol processing in kernel • Greater flexibility if application specific information is integrated into protocol processing • Can tune protocol to application’s needs • Eg.. Customized retransmission of video frames
U-Net Philosophy • Achieve flexibility and performance by • Removing kernel from the critical path • Placing entire protocol stack at user level • Allowing protected user-level access to network • Supplying full bandwidth to small messages • Supporting both novel and legacy protocols
Do MPPs do this? • Parallel machines like Meiko CS-2, Thinking Machines CM-5 • Have tried to solve the problem of providing user-level access to network • Use of custom network and network interface – No flexibility • U-Net targets applications on standard workstations • Using off-the-shelf components
Virtualize N/W device so that each process has illusion of owning NI Mux/ Demuxing device virtualizes the NI Offers protection! Kernel removed from critical path Kernel involved only in setup Basic U-Net architecture
Building Blocks Application End-points Communication Segment(CS) Message Queues Sending Assemble message in CS EnQ Message Descriptor Receiving Poll-driven/ Event-driven DeQ Message Descriptor Consume message EnQ buffer in free Q The U-Net Architecture A region of memory An application endpoint
More on event-handling (upcalls) Can be UNIX signal handler or user-level interrupt handler Amortize cost of upcalls by batching receptions Mux/ Demux : Each endpoint uniquely identified by a tag (eg.. VCI in ATM) OS performs initial route setup and security tests and registers a tag in U-Net for that application The message tag mapped to a communication channel U-Net Architecture (contd.)
Observations • Have to preallocate buffers – memory overhead! • Protected User-level access to NI : Ensured by demarcating into protection boundaries • Defined by endpoints and communication channels • Applications cannot interfere with each other because • Endpoints, CS and message queues user-owned • Outgoing messages tagged with originating endpoint address • Incoming messages demuxed by U-Net and sent to correct endpoint
Zero-copy and True zero-copy • Two levels of sophistication depending on whether copy is made at CS • Base-Level Architecture • Zero-copy : Copied in an intermediate buffer in the CS • CS’es are allocated, aligned, pinned to physical memory • Optimization for small messages • Direct-access Architecture • True zero copy : Data sent directly out of data structure • Also specify offset where data has to be deposited • CS spans the entire process address space • Limitations in I/O Addressing force one to resort to Zero-copy
Communication segments and message queues are scarce resources Optimization: Provide a single kernel emulated endpoint Cost : Performance overhead Kernel emulated end-point
U-Net Implementation • U-Net architectures implemented in two systems • Using Fore Systems SBA 100 and 200 ATM network interfaces • But why ATM? • Setup : SPARCStations 10 and 20 on SunOS 4.1.3 with ASX-200 ATM switch with 140 Mbps fiber links • SBA-200 firmware • 25 MHz On-board i960 processor, 256 KB RAM, DMA capabilities • Complete redesign of firmware • Device Driver • Protection offered through VM system (CS’es) • Also through <VCI, communication channel> mappings
U-Net Performance • RTT and bandwidth measurements • Small messages 65 μs RTT (optimization for single cells) • Fiber saturated at 800 B
U-Net Active Messages Layer • An RPC that can be implemented efficiently on a wide range of hardware • A basic communication primitive in NOW • Allow overlapping of communication with computation • Message contains data & ptr to handler • Reliable Message delivery • Handler moves data into data structures for some (ongoing) operation
AM – Micro-benchmarks • Single-cell RTT • RTT ~ 71 μs for a 0-32 B message • Overhead of 6 μs over raw U-Net – Why? • Block store BW • 80% of the maximum limit with blocks of 2KB size • Almost saturated at 4KB • Good performance!
Split-C application benchmarks • Parallel Extension to C • Implemented on top of UAM • Tested on 8 processors • ATM cluster performs close to CS-2
TCP/IP and UDP/IP over U-Net • Good performance necessary to show flexibility • Traditional IP-over-ATM shows very poor performance • eg.. TCP : Only 55% of max BW • TCP and UDP over U-Net show improved performance • Primarily because of tighter application-network coupling • IP-over-U-Net: • IP-over-ATM does not exactly correspond to IP-over-UNet • Demultiplexing for the same VCI is not possible
Performance Graphs UDP Performance Saw-tooth behavior for Fore UDP TCP Performance
U-Net provides virtual view of network interface to enable user-level access to high-speed communication devices The two main goals were to achieve performance and flexibility By avoiding kernel in critical path Achieved? Look at the table below… Conclusion
Motivation • Small kernel OSes have most services implemented as separate user-level processes • Have separate, communicating user processes • Improve modular structure • More protection • Ease of system design and maintenance • Cross-domain & cross-machine communication treated equal - Problems? • Fails to isolate the common case • Performance and Simplicity considerations
Measurements • Measurements show cross-domain predominance • V System – 97% • Taos Firefly – 94% • Sun UNIX+NFS Diskless – 99.4% • But how about RPCs these days? • Taos takes 109 μs for a Null() local call and 464 μs for RPC – 3.5x overhead • Most interactions are simple with small numbers of arguments • This could be used to make optimizations
Overheads in Cross-domain Calls • Stub Overhead – Additional execution path • Message buffer overhead – Cross-domain calls can involve four copy operations for any RPC • Context switch – VM context switch from client’s domain to the server’s and vice versa on return • Scheduling – Abstract and Concrete threads
Available solutions? • Eliminating kernel copies (DASH system) • Handoff scheduling (Mach and Taos) • In SRC RPC : • Message buffers globally shared! • Trades safety for performance
Solution proposed : LRPCs • Written for the Firefly system • Mechanism for communication between protection domains in the same system • Motto : Strive for performance without foregoing safety • Basic Idea : Similar to RPCs but, • Do not context switch to server thread • Change the context of the client thread instead, to reduce overhead
Overview of LRPCs • Design • Client calls server through kernel trap • Kernel validates caller • Kernel dispatches client thread directly to server’s domain • Client provides server with a shared argument stack and its own thread • Return through the kernel to the caller
Implementation - Binding Server Client Kernel Export interface Register with name server Trap for import Notify Clerk Wait Client Thread Server thread Clerk Send BO A-stack list Send PDL Processing: Allocates A-stacks Linkage Records Binding Object (BO)
Data Structures used and created • Kernel receives Procedure Descriptor List (PDL) from Clerk • Contains a PD for each procedure • Entry Address apart from other information • Kernel allocates Argument stacks (A-stacks) shared by client-server domains for each PD • Allocates linkage record for each A-Stack to record caller’s address • Allocates Binding Object - the client’s key to access the server’s interface
Calling • Client stub traps kernel for call after • Pushing arguments in A-stack • Storing BO, procedure identifier, address of A-stack in registers • Kernel • Validates client, verifies A-stack and locates PD & linkage • Stores Return address in linkage and pushes on stack • Switches client thread’s context to server by running a new stack E-stack from server’s domain • Calls the server’s stub corresponding to PD • Server • Client thread runs in server’s domain using E-stack • Can access parameters of A-stack • Return values in A-stack • Calls back kernel through stub
Stub Generation • LRPC stub automatically generated in assembly language for simple execution paths • Sacrifices portability for performance • Maintains local and remote stubs • First instruction in local stub is branch stmt
What are optimized here? • Using the same thread in different domains reduces overhead • Avoids scheduling decisions • Saves on cost of saving and restoring thread state • Pairwise A-stack allocation guarantees protection from third party domain • Within? Asynchronous updates? • Validate client using BO – To provide security • Elimination of redundant copies through use of A-stack! • 1 against 4 in traditional cross-domain RPCs • Sometimes two? Optimizations apply
But… Is it really good enough? • Trades off memory management costs for the reduction of overhead • A-stacks have to be allocated at bind time • But size generally small • Will LRPC work even if a server migrates from a remote machine to the local machine?
Other Issues – Domain Termination • Domain Termination • LRPC from terminated server domain should be returned back to the client • LRPC should not be sent back to the caller if latter has terminated • Use binding objects • Revoke binding objects • For threads running LRPCs in domain restart new threads in corresponding caller • Invalidate active linkage records – thread returned back to first domain with active linkage • Otherwise destroyed
Multiprocessor Issues • LRPC minimizes use of shared data structures on the critical path • Guaranteed by pairwise allocation of A-stacks • Cache contexts on idle processors • Idling threads in server’s context in idle processors • When client thread does RPC to server swap processors • Reduces context-switch overhead
Evaluation of LRPC Performance of four test programs (time in μs) (run on CVAX-Firefly averaged over 100000 calls)
Minimum refers to the inherent minimum overhead 18 μs spent in client stub and 3 μs in the server stub 25% time spent in TLB misses Cost Breakdown for the Null LRPC
Tested with Firefly on four C-VAX and one MicroVaxII I/O processors Speedup of 3.7 with 4 processors as against 1 processor Speedup of 4.3 with 5 processors SRC RPCs : inferior performance due to a global lock held during critical transfer path Throughput on a multiprocessor
Conclusion • LRPC Combines • Control Transfer and communication model of capability systems • Programming semantics and large-grained protection model of RPCs • Enhances performance by isolating the common case
NOW We will see ‘NOW’ later in one of the subsequent 614 presentations