Cutting-Edge Text Mining Research at BITEM Research Group
40 likes | 122 Views
Join us at BITEM Research Group for innovative projects in Digital Libraries, Web technologies, Personalized medicine, and more. Specializing in semi-structured data, we excel in text mining on the noisy Web. Our technological expertise includes SolrCloud, CouchDB replication, Hadoop, and more. With a focus on Big Data, we handle tasks like Patent analytics, Pharmacovigilance, and Clinical trials. Explore our work on analyzing Big Social Media Data, Novelty Detection, and Proteins annotation. Let's conquer the data deluge together!

Cutting-Edge Text Mining Research at BITEM Research Group
E N D
Presentation Transcript
Big Data atBITEM Research Group • (Text|Web) Mining Research Group • patrick.ruch@hesge.ch, http://bitem.hesge.ch • Research projects: Digital Libraries, Web, Personalized medicine, Patent analytics, Consumer Analytics, Pharmacovigilance, Clinical trials… • Specialised in (semi|un)structured data • We like text, text and more text • Especially on the noisy/dirty Web • Technological expertise: CouchDB replication, SolrCloud (distributed indexing and search), indexing/searching in SSD/HDFS/Hadoop, SPARQL endpoints…
Web Sources NoSQL Replication Forum CouchDB CouchDB RSS CouchDB CouchDB Twitter API Cleaning Normalisation Solr Cloud 26’000 per day Drugbank 19’000 drugnames checkedeach 10 mn 7 M of docs in 9 months Pharmacovigilance on Big Social Media Data Dynamic and Real Time Data Analysis Correlation Analysis NoveltyDetection Trends Analysis
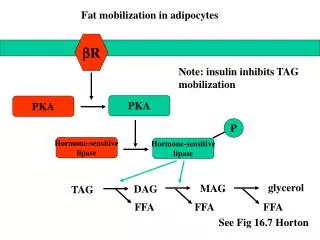
Proteins annotation based on litterature by curators 23 000 000 articles 40’000 concepts [Big-scaleMulticlass Multilabel Classifier] Lazylearning ! annotated articles Manual annotation planned for 2045 ! (Baumgartner et al) GOA Machine Learning based on Information Retrievalmethods Assisting curators Macro reading of litterature Profilinganytextual content Managing the data deluge for proteins annotation
Patent retrieval The real situation (0.5-1 TB) Experiments Database 13 millions of patents Database A sample of 1 million of patents Extraction 33 days Extraction 2.5 days XML patents 17 Gb XML patents 0.221 Tb Normalization 33 days Normalization 2.5 days XML patents + metadata 0.234 Tb XML patents + metadata 18 Gb Indexing 5 days Indexing 10 hours Index 0.1 Tb Index 3 Gb