Download

1 / 62
620 likes | 653 Views
This talk delves into the concept of minimax pathology, its past research, a real-valued minimax model, and the benefits of minimax in game theory. Discover the intricacies behind minimax and why it isn't always pathological.

E N D
Minimax Pathology Mitja Luštrek 1, Ivan Bratko 2 and Matjaž Gams 1 1 Jožef Stefan Institute, Department of Intelligent Systems 2 University of Ljubljana, Faculty of Computer and Information Science
Plan of the talk • What is the minimax pathology • Past work on the pathology • A real-valued minimax model • Why is minimax not pathological • Why is minimax beneficial Mitja Luštrek
What is the minimax pathology • Past work on the pathology • A real-valued minimax model • Why is minimax not pathological • Why is minimax beneficial Mitja Luštrek
What is the minimax pathology • Conventional wisdom: • the deeper one searches a game tree, the better he plays; • no shortage of practical confirmation. • Theoretical analyses: • minimaxing amplifies the error of the heuristic evaluation function; • therefore the deeper one searches, the worse he plays; • Pathology! Mitja Luštrek
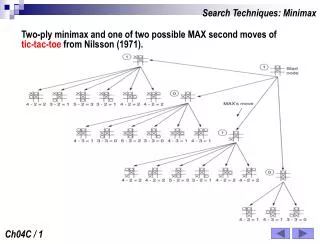
The pathology illustrated Current position Game tree Final values (true) Mitja Luštrek
The pathology illustrated Current position Static heuristic values (with error) Final values (true) Mitja Luštrek
The pathology illustrated Current position Backed-up heuristic values (should be more trustworthy, but have larger error instead!) Minimax Static heuristic values (with error) Final values (true) Mitja Luštrek
The pathology illustrated Current position Static heuristic values (with smaller error) Final values (true) Mitja Luštrek
What is the minimax pathology • Past work on the pathology • A real-valued minimax model • Why is minimax not pathological • Why is minimax beneficial Mitja Luštrek
The discovery • First discovered by Nau [1979]. • A year later discovered independently by Beal [1980]. • Beal’s minimax model: • uniform branching factor; • position values are losses or wins; • the proportion of losses for the side to move is constant; • position values within a level are independent of each other; • the error is the probability of mistaking a loss for a win or vice versa and is independent of the level of a position. • None of the assumptions look terribly unrealistic, yet the pathology is there. Mitja Luštrek
Attempts at an explanation • Researchers tried to find a flaw in Beal’s model by attacking its assumptions. • Uniform branching factor: • geometrically distributed branching factor prevents the pathology [Michon, 1983]; • in chess endgames asymmetrical branching factor causes the pathology [Sadikov, 2005]. • Node values are losses or wins: • multiple values do not help [Bratko & Gams, 1982; Pearl, 1983]; • multiple values used in a game, which is pathological [Nau, 1982, 1983]; • multiple/real values used to construct a realistic model, which is not pathological [Scheucher & Kaindl, 1998; Luštrek, 2004]. Mitja Luštrek
Attempts at an explanation • The proportion of losses for the side to move is constant: • in models where it is applicable, it was agreed to be necessary [Beal, 1982; Bratko & Gams, 1982; Nau, 1982, 1983]. • Node values within a level are independent of each other: • nearby positions are similar and thus have similar values; • most researchers agreed that this is the answer or at least a part of it [Beal, 1982; Bratko & Gams, 1982; Pearl, 1983; Nau, 1982, 1983; Schrüfer, 1986; Scheucher & Kaindl, 1998; Luštrek, 2004]. Mitja Luštrek
Attempts at an explanation • The error is independent of the level of a position: • varying error cannot account for the absence of the pathology [Pearl, 1983]; • used varying error in a game and it did not help [Nau, 1982, 1983]; • varying error is a part of the answer (with the other part being node-value dependence) [Scheucher & Kaindl, 1998]. • Despite some disagreement, node-value dependence seems to be the most widely supported explanation. • But is it really necessary? Is there no simpler, more fundamental explanation?We believe there is! Mitja Luštrek
What is the minimax pathology • Past work on the pathology • A real-valued minimax model • Why is minimax not pathological • Why is minimax beneficial Mitja Luštrek
Why multiple/real values? • Necessary in games where the final outcome is multivalued (Othello, tarok). • Used by humans and game-playing programs. • Seem unnecessary in games where the outcome is a loss, a win or perhaps a draw (chess, checkers). • But: • in a losing position against a fallible and unknown opponent, the outcome is uncertain; • in a winning position, a perfect two-valued evaluation function will not lose, but it may never win, either. • Multiple values are required to model uncertainty and to maintain a direction of play towards an eventual win. Mitja Luštrek
A real-valued minimax model • Aims to be a real-valued version of Beal’s model: • uniform branching factor; • position values are real numbers; • if the real values are converted to losses and wins, the proportion of losses for the side to move is constant; • position values within a level are independent of each other; • the error is normally distributed noise and is independent of the level of a position. • The crucial difference is the assumption 5. Mitja Luštrek
Assumption 5 • Two-value error: • Real-value error: - + Loss Win 0.31 0.74 Mitja Luštrek
Assumption 5 Beal’s assumption 5: Static P (loss ↔ win) constant with the depth of search. Our assumption 5: The magnitude of static real-value noise constant with the depth of search. P (loss ↔ win) Real-value noise Depth Depth Note: static = applied at the lowest level of search. Mitja Luštrek
Building of a game tree Mitja Luštrek
Building of a game tree True values distributed uniformly in [0, 1] Mitja Luštrek
Building of a game tree True values backed up Mitja Luštrek
Building of a game tree True values backed up Mitja Luštrek
Building of a game tree True values backed up Mitja Luštrek
Building of a game tree True values backed up Mitja Luštrek
Building of a game tree Search to this depth Mitja Luštrek
Building of a game tree Heuristic values = true values + normally distributed noise Mitja Luštrek
Building of a game tree Heuristic values backed up Mitja Luštrek
Building of a game tree Heuristic values backed up Mitja Luštrek
Building of a game tree Heuristic values backed up Mitja Luštrek
What we do with our model • Monte Carlo experiments: • generate 10,000 sets of true values; • generate 10 sets of heuristic values per set of true values per depth of search. • Measure the error at the root: • real-value error = the average difference between the true value and the heuristic value; • two-value error = the frequency of mistaking a loss for a win or vice versa. • Compare the error at the root when searching to different depths. Mitja Luštrek
Conversion of real values to losses and wins • To measure two-value error, real values must be converted to losses and wins. • Value above a threshold means win, below the threshold loss. • At the leaves: • the proportion of losses for the side to move = cb (because it must be the same at all levels); • real values distributed uniformly in [0, 1]; • therefore threshold = cb. • At higher levels: • minimaxing on real values is equivalent to minimaxing on two values; • therefore also threshold = cb. Mitja Luštrek
Conversion of real values to losses and wins Real values Two values Mitja Luštrek
Conversion of real values to losses and wins Real values Two values Minimaxing Mitja Luštrek
Conversion of real values to losses and wins Real values Two values Minimaxing Mitja Luštrek
Conversion of real values to losses and wins Real values Two values Apply threshold Mitja Luštrek
Conversion of real values to losses and wins Real values Two values Mitja Luštrek
Conversion of real values to losses and wins Real values Two values Mitja Luštrek
Conversion of real values to losses and wins Real values Two values Apply threshold Mitja Luštrek
Conversion of real values to losses and wins Real values Two values Minimaxing Mitja Luštrek
Conversion of real values to losses and wins Real values Two values Minimaxing Mitja Luštrek
Conversion of real values to losses and wins Real values Two values Mitja Luštrek
What is the minimax pathology • Past work on the pathology • A real-valued minimax model • Why is minimax not pathological • Why is minimax beneficial Mitja Luštrek
Error at the root / constant static real-value error • Plotted: real-value and two-value error at the root. • Static real-value error: normally distributed noise with standard deviation 0.1. Mitja Luštrek
Static two-value error / constant static real-value error • Plotted: static two-value error. • Static real-value error: normally distributed noise with standard deviation 0.1. Mitja Luštrek
Static real-value error / constant static two-value error • Plotted: static real-value error. • Static two-value error: 0.1. Mitja Luštrek
Error at the root / constant static two-value error • Plotted: two-value error at the root in our real-value model and in Beal’s model. • Two-value error at the lowest level of search: 0.1. • After a small tweak of Beal’s model, we get a perfect match. Mitja Luštrek
Conclusions from the graphs • Static real-value is constant: • static two-value error decreases with the depth of search; • no pathology. • Static two-value error is constant: • static real-value error increases with the depth of search; • pathology. • Which static error should be constant? Mitja Luštrek
Should real- or two-value static error be constant? • Already explained why real values are necessary. • Real-value error most naturally represent the fallibility of the heuristic evaluation function. • Game playing programs do not use two-valued evaluation functions, but if they did: • they would more often make a mistake in uncertain positions close to the threshold; • they would rarely make a mistake in certain positions far from the threshold. Mitja Luštrek
Should real- or two-value static error be constant? Mitja Luštrek
Two-value error larger at higher levels • Some simplifications: • branching factor = 2; • node values in [0, 1]; • consider only one type of error: wins mistaken for losses; • consider two levels at a time to avoid even/odd level differences. • X ... true real value of a nodeF (x) = P (X < x) ... distribution function of the true real valuee ... real-value errorX – e ... heuristic real valuet ... threshold • Two-value error:P (X > t X – e < t) = P (t < X < t + e) = F (t + e) – F (t) Mitja Luštrek