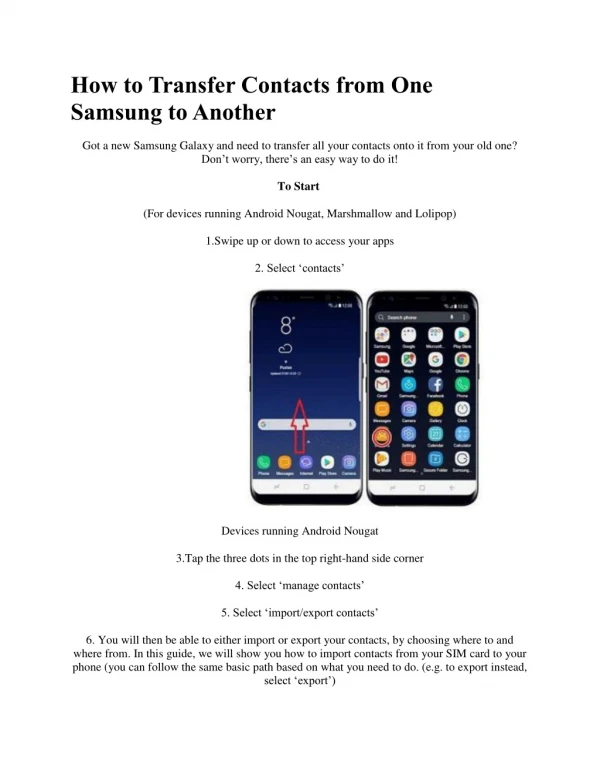
Download

1 / 29
290 likes | 400 Views
Using Advice to Transfer Knowledge Acquired in One Reinforcement Learning Task to Another. Lisa Torrey, Trevor Walker, Jude Shavlik University of Wisconsin-Madison, USA Richard Maclin University of Minnesota-Duluth, USA. Our Goal. Transfer knowledge… … between reinforcement learning tasks

E N D
Using Advice to Transfer Knowledge Acquired in One Reinforcement Learning Task to Another Lisa Torrey, Trevor Walker, Jude Shavlik University of Wisconsin-Madison, USA Richard Maclin University of Minnesota-Duluth, USA
Our Goal Transfer knowledge… … between reinforcement learning tasks … employing SVM function approximators … using advice
Transfer • Exploit previously learned models Learn first task Learn related task knowledge acquired • Improve learning of new tasks with transfer without transfer performance experience
Reinforcement Learning • Q-function: value of taking action from state • Policy: take action with max Qaction(state) +2 0 -1 state…action…reward…new state
Advice for Transfer Based on what worked in Task A, I suggest… • Advice improves RL performance • Advice can be refined or even discarded Task B Learner I’ll try it, but if it doesn’t work I’ll do something else. Task A Solution
Task A experience Task B experience Transfer Process Task A experience Advice from user (optional) Task A Q-functions Mapping from user Task A Task B Transfer Advice Task B experience Advice from user (optional) Task B Q-functions
RoboCup Soccer Tasks KeepAway BreakAway Keep ball from opponents [Stone & Sutton, ICML 2001] Score a goal [Maclin et al., AAAI 2005]
RL in RoboCup Tasks KeepAway BreakAway Features (time left) Actions Rewards
Transfer Process Task A experience Task A Q-functions Mapping from user Task A Task B Transfer Advice Task B experience Task B Q-functions
Approximating Q-Functions • Given examples State features Si= <f1 , … , fn> Estimated values y Qaction(Si) • Learn linear coefficients y = w1f1 + … + wnfn + b • Non-linearity from Boolean tile features tilei,lower,upper = 1 if lower ≤ fi < upper
Support Vector Regression Q-estimate y state S Linear Program minimize ||w||1 + |b| + C||k||1 such that y -k Sw + b y + k
Transfer Process Task A experience Task A Q-functions Mapping from user Task A Task B Transfer Advice Task B experience Task B Q-functions
Advice Example • Need only follow advice approximately • Add soft constraints to linear program if distance_to_goal 10 and shot_angle 30 then prefer shoot over all other actions
Incorporating AdviceMaclin et al., AAAI 2005 • Advice and Q-functions have same language • Linear expressions of features if v11 f1 + … + v1n fn d1 … and vm1 f1 + … + vmn fn dn then Qshoot > Qother for all other
Transfer Process Task A experience Task A Q-functions Mapping from user Task A Task B Transfer Advice Task B experience Task B Q-functions
Expressing Policy with Advice Qhold_ball(s) Qpass_near(s) Qpass_far(s) Old Q-functions Advice expressing policy ifQhold_ball(s)>Qpass_near(s) and Qhold_ball(s)>Qpass_far(s) then prefer hold_ball over all other actions
Mapping Actions Qhold_ball(s) Qpass_near(s) Qpass_far(s) hold_ball move pass_near pass_near pass_far Old Q-functions Mapping from user Mapped policy ifQhold_ball(s) >Qpass_near(s) and Qhold_ball(s) >Qpass_far(s) then prefer move over all other actions
Mapping Features Mapping from user Q-function mapping Qhold_ball(s) = w1 (dist_keeper1)+ w2 (dist_taker2)+ … Q´hold_ball(s) = w1 (dist_attacker1)+ w2 (MAX_DIST)+ …
Old model Mapped model Qx = wx1f1 + wx2f2 + bx Qy = wy1f1+by Qz = wz2f2 + bz Q´x = wx1f´1 + wx2f´2 + bx Q´y = wy1f´1+ by Q´z = wz2f´2 + bz Advice Advice (expanded) ifwx1f´1 + wx2f´2 + bx > wy1f´1 + by andwx1f´1 + wx2f´2 + bx > wz2 f´2 + bz then prefer x´ to all other actions ifQ´x>Q´y andQ´x>Q´z then prefer x´ Transfer Example
Transfer Experiment • Between RoboCup subtasks • From 3-on-2 KeepAway • To 2-on-1 BreakAway • Two simultaneous mappings • Transfer passing skills • Map passing skills to shooting
Experiment Mappings • Play a moving KeepAway game • Pass Pass, Hold Move • Pretend teammate is standing in the goal • Pass Shoot imaginary teammate
Experimental Methodology • Averaged over 10 BreakAway runs • Transfer: advice from one KeepAway model • Control: runs without advice
Analysis • Transfer advice helps BreakAway learners • 7% more likely to score a goal after learning • Improvement is delayed • Advantage begins after 2500 games • Some advice rules apply rarely • Preconditions for shoot advice not often met
Related Work: Transfer • Remember action subsequences [Singh, ML 1992] • Restrict action choices [Sherstov & Stone, AAAI 2005] • Transfer Q-values directly in KeepAway [Taylor & Stone, AAMAS 2005]
Related Work: Advice • “Take action A now” [Clouse & Utgoff, ICML 1992] • “In situations S, action A has value X ”[Maclin & Shavlik, ML 1996] • “In situations S, prefer action A over B”[Maclin et al., AAAI 2005]
Future Work • Increase speed of linear-program solving • Decrease sensitivity to imperfect advice • Extract advice from kernel-based models • Help user map actions and features
Conclusions • Transfer exploits previously learned models to improve learning of new tasks • Advice is an appealing way to transfer • Linear regression approach incorporates advice straightforwardly • Transferring a policy accommodates different reward structures
Acknowledgements • DARPA grant HR0011-04-1-0007 • United States Naval Research Laboratory grant N00173-04-1-G026 • Michael Ferris • Olvi Mangasarian • Ted Wild