
隨機樣本
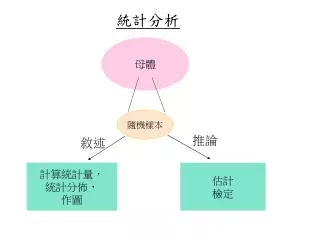
統計分析. 母體. 隨機樣本. 推論. 敘述. 計算統計量, 統計分佈, 作圖. 估計 檢定. 統計 敘 述. 一、 統計值 中心位置 -- 平均數( mean), 中位數( median) 參考位置 --上四分位數,下四分位數 分散度 -- 標準差( std) , 變異係數 ( CV) ( CV= 標準差 / 平均數 ). 資料中心位置的指標. 分散度的指標. 二、常態分配的重要性 : 許多資料呈現常態分配。 大樣本之平均數接近常態分配 ( 中央極限定理 )

隨機樣本
E N D
Presentation Transcript
統計分析 母體 隨機樣本 推論 敘述 計算統計量, 統計分佈, 作圖 估計 檢定
統計敘述 一、統計值 中心位置 -- 平均數(mean),中位數(median) 參考位置 --上四分位數,下四分位數 分散度-- 標準差(std) ,變異係數 (CV) ( CV= 標準差 / 平均數 ) 資料中心位置的指標 分散度的指標
二、常態分配的重要性: • 許多資料呈現常態分配。 • 大樣本之平均數接近常態分配(中央極限定理) • 可以常態機率值概算二項分配之機率值。 • 許多其它分配之機率值也可以常態機率值概算。
統計推論 一、抽樣誤差 實際母體 樣 本 推論 估計之母體 統計推論必產生差異,稱為抽樣誤差;抽樣誤差的大小與樣本數、推論方法等有關,依據抽樣分配來估計。 例: 在 95%的信心水準下,抽樣錯誤差為正負3.1個百分點。 在α=0.05,支持率 22% 與 24% 在統計上差異不顯著。
二、抽樣分配 樣本得到的統計量是一隨機變數,統計量的分稱為抽樣分配。 理論上,資料是常態分配,則樣本變異數屬於 χ2分配。 由此推導出 t-分配與 F-分配,它們是統計推論上常用之分配。 用於平均數檢定或 兩組資料比較 用於兩組變異數比較 或 變異數分析
三、估計 • 點估計 • 質性資料或類別資料 比例 • 量性資料 平均數、標準差 • 區間估計 • 以一區間估計參數最可能落入的範圍。 例: 1. 在 95% 的信心水準下,抽樣錯誤差為正負3.1個 百分點; 資料支持的比例 = 24%,則估計支持率 在 20.9% 到 27.1% 之間。 2. 在 95%的信心水準下,平均起薪資為 3.23 ± 0.15萬。
四、檢定 對一研究主題作成假說,根據資料來判斷是否接受此假說。 p-值 資料顯示 H0 為真的可能性 p-值 < α,結論為 H1,即研究主題顯著 (significant)。 p-值大時,結論為資料不足以証實研究的主題。 主題不顯著。 檢定法選擇適當的檢定量,依據檢定量的分配計算出p-值, 最後做出結論。
正式的檢定步驟 • 敘述假設。 • 訂定顯著水準。 • 找出統計量及抽樣分配。 • 選定統計量的分界值以及決策法則。 • 計算統計量的值。 • 決定統計決策。 • 針對研究主題作決策。 ( 或,選擇適當的方法,利用統計軟體得到 p-值,做出結論。)
信賴區間與檢定顯著性之關係 The C.I. with (1-α) confidence level does not cover the null hyp. → The alternative hyp. is significant with sign. level α 例 1:在 90%的信心水準下,平均起薪資為 3.23 ± 0.51萬, 當檢定 H0:μ= 3 萬,μ≠3 萬是不顯著的,α= 0.10。 例 2:在 95%的信心水準下,兩組平均差異為 1.23 ± 0.75, 則兩組差異是顯著的,α= 0.05 。
二變數的相關性 x,y 皆為隨機變數時,二者之線性關係強度以 ρ代表,稱為母體的相關係數。 若ρ= 0,則 x與y無關;若ρ= ±1,則 x與y有完全直線關係。 樣本相關係數: • -1≦r≦+1, r >0,x、y是正相關,r < 0,x、y是負相關 • r 值度量 x、y 線性關係之強度, • | r | 愈接近 1,表示 x、y 線性關係愈強。 • | r | 愈接近 0,x、y 線性關係愈弱 。 (但可能有二次關係)
相關顯著性之檢定 Q:X 與 Y 是否有線性關係 ? H0: ρ= 0 vs. H1:ρ≠0 若 |t| > tα/2; n-2 , 則拒絕 H0, X 與 Y 線性關係顯著。
直線迴歸 Data : (x1, y1), ... , (xn, yn) 二變數 --- 依變數 y (dependent variable) 獨立變數 x (independent variable) 。 模式:yi = β0+ β1 xi + εi , i =1,2,…,n εi ~ NID( 0, σ2 ) 說明:1、 y 與 x 表現直線關係之趨勢,其分散程度 = σ。 2、x=0 時,期望觀察值 yi 落在 β0,是為截距。 3、斜率β又稱為迴歸係數,表示 x 改變 1 單位時,y 改變之量。
迴歸式之估計 • 最小平方法 ( Method of Least Square): • 估計β0 , β1 ,使得估計之誤差平方和最小 • 以 b1 = Sxy / Sxx估計β ,b0 = y – b1 x 估計β0 • y = b0 + b1 x 是為直線迴歸式。 • ei= yi - (b0 + b1 xi) 稱為第 i 個殘差。
迴歸之ANOVA表 • MSE 為變異數。 • p-value 檢定迴歸式的顯著性。
迴歸線顯著性檢定 H0: β1 = 0 H1: β1≠ 0 f = MSR/ MSE 若 f > Fα , 則 Y與X有顯著直線相關。 (p-value < α) 判定係數 (Coef. Of determination) R2 = SSR/SST 稱為判定係數,量測迴歸式變異量佔總變量之 比例,用以度量迴歸線所能解釋 Y 變化之比例。 註:1、0≦ R2≦ 1 。 2、R2 = 1 - SSE/SST, R2=1,完全估計, R2=0,x,y無關。 3、 R2 之大 小說明迴歸式估計的程度。