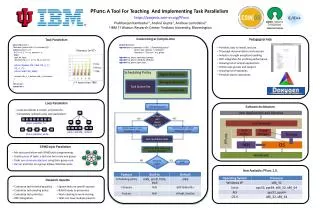
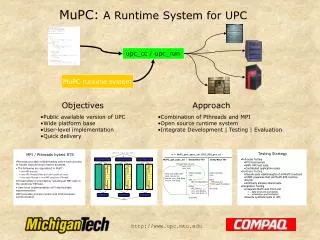
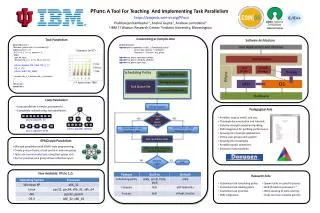
Dynamic Task Parallelism with a GPU Work-Stealing Runtime System
Dynamic Task Parallelism with a GPU Work-Stealing Runtime System. Max Grossman Advisor: Dr. Vivek Sarkar Rice University. Background. GPU is a promising example of heterogeneous hardware Hundreds of simultaneous threads High m emory bandwidth


Dynamic Task Parallelism with a GPU Work-Stealing Runtime System
E N D
Presentation Transcript
Dynamic Task Parallelism with a GPU Work-Stealing Runtime System Max Grossman Advisor: Dr. VivekSarkar Rice University
Background • GPU is a promising example of heterogeneous hardware • Hundreds of simultaneous threads • High memory bandwidth • NVIDIA’s CUDA makes general purpose programming on GPUs possible, but not easy for the average programmer
Co Ca Control ALU ALU ALU ALU DRAM Cache A A A A A A A A A A A A A A A A Streaming Multiprocessor DRAM CPUs and GPUs have fundamentally different design philosophies Single CPU core Multiple GPU processors • Figure source: David B. Kirk and Wen-meiW. Hwu. Programming Massively Parallel Processors: A Hands-on Approach. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 1st edition, 2010.
Motivation & Approach • CUDA programming model launches a batch of data-parallel threads • Can we do better with dynamic task parallelism? • Our approach • Manage task execution across multiple streaming multiprocessors (SMs) in a GPU device by introducing a hybrid work-stealing/work-sharing runtime system • Manage multiple CUDA devices for the user • Hide device memory allocation and communication from user
Load Balance Results • NQueens(14) • Worst case load imbalance for static subtree assignment vs. dynamic work-stealing are 9.8x vs. 1.17x
Conclusions • GPU work stealing runtime which supports dynamic task parallelism, on hardware intended for data parallelism • Showed effectiveness of work stealing queues in dynamically distributing work between SMs • Future work: • Fully integrate this runtime with the CnC-HC data flow coordination language being developed at Rice University