Download

1 / 43
1.19k likes | 5.68k Views
Lecture – 14. Factors affecting validity and reliability. RMPM. Contents. 1. Reliability. 2. Validity. 3. Job Analysis. Validity and Reliability.

E N D
Lecture – 14 Factors affecting validity and reliability RMPM SZABIST
Contents 1. Reliability 2. Validity 3. Job Analysis SZABIST
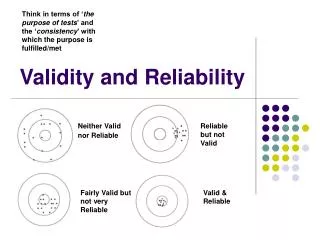
Validity and Reliability SZABIST
Reliable instruments introduce less error into the statistical measurement and resulting analysis. Still, the significant results may well be meaningless if the instrument is faulty (DeVellis, 1991). SZABIST
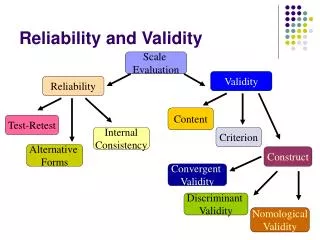
Reliability Reliability – consistency or stability of a measure • Does the instrument provide the same measurement every time or does it fluctuate due to instrument error? • Example: Reliability is the extent to which a score from a selection measure is stable or free from error SZABIST
Reliability is synonymous with consistency. • It is the degree to which test scores for a an individual test taker or group of test takers are consistent over repeated applications. • The consistency of test scores is critically important in determining whether a test can provide good measurement.
Xobtained = Xtrue – Xerror • IDEAL DOES NOT EXIST • USEFUL CONCEPTION
Possible Sources of threats to reliability • Conditions of testing • Unreliability or bias in grading or rating • The Instrument Taker • Motivation of interviewer / interviewees • Emotional Strain • Administrator Factors • Length of Time between Test and Retest • Temporary individual characteristics • Lack of standardization • Chance SZABIST
Number of Items on the instrument • Poorly written instrument • Low internal consistency estimates are often the result of poorly written items or an excessively broad content area of measure (Crocker & Algina, 1986) • Other factors include homogeneity of the testing sample, imposed time limits in the testing situation, item difficulty and the length of the testing instrument (Crocker & Algina, 1986; Mehrens & Lehman, 1991; DeVellis, 1991; Gregory, 1992). SZABIST
Measures of Reliability Test-Retest 1. Test-Retest 2. Alternate forms reliability 3. Internal reliability / Consistency 4. Scorer Reliability SZABIST
1. Test-Retest– use same measurement device twice. Same people take test twice • if stable trait is being measured, should get similar results each time. • If similar results are achieved then phenomenon is called temporal stability • Coefficient of Stability– • Correlation between first set of measurements and second (look for r > .70) • Test-retest reliability (TRR) coefficient for tests used in industry is 0.86 (Hood, 2001) • Longer interval b/w two tests lowers reliability coefficient (Anastasi & Urbina, 1997) SZABIST
TRR is not appropriate for all kinds of tests. • E.g. Anxiety is of two types: • Trait Anxiety and State Anxiety. TRR may not hold true in case of measurement of state anxiety SZABIST
2. Alternate forms reliability: Equivalent Forms– two forms of the same test given to the same people • Coefficient of Equivalence– Correlation between the 2 forms • Two forms of tests should have the same mean and SD (Clause, Mullins, Nee, Pulakos, & Schmitt, 1998) • Often difficult to develop 2 truly equivalent forms of a test • Example: 1) Examination question papers are repeated in every test • 2) Give 2 forms of IQ test to group of people to see whether the 2 forms assess the same construct. SZABIST
3. Internal reliability / Consistency– how well do items in test relate to other items in the test (homogeneity of test). • Extent to which similar items are answered in similar ways • Split-Half– • Correlate odd numbered items with the even numbered items. • Odds is one group and evens in other • Scores of 2 groups correlated • B/c number are reduced so to adjust correlation, Spearman-Brown prophecy is used SZABIST
b. Cronbach’s Alpha– (Cronbach, 1951): Conceptually, the average correlation of each item on test with every other item Cronbach is most commonly used test for testing the internal reliability (Hogan, Benjamin & Brezinski, 2003) SZABIST
c. K-R-20 (Kunder-Richardson formula 20) – Kunder-Richardson (1937): Similar to Cronbach Alpha. But K-R-20 can be used for only dichotomous items (yes/no, true/false…), while alpha can be used for all situations SZABIST
General rule: In general, longer the test, the higher its internal consistency • E.g. • If a test consists of only 2 MCQs, if you wrongly attempt one your score will diminish by 50%. • On the other hand, if test consists of 100 MCQs, then if you do one question wrong, it will not impact much SZABIST
4. Scorer Reliability– If the scorer makes mistake, results would become non-reliable. • Allard, Butler, Faust, and Shea (1995) found that • 53% personality tests contained at least one scoring error, 19% contained enough errors to alter a clinical diagnosis SZABIST
Inter-rater – Used when test scores are based on subjective ratings • Correlation among scores given by 2 or more different raters • Examples: • Interview assessment • Olympic skating judges SZABIST
Measurement Error is Reduced By Writing items clearly Making instructions easily understood Adhering to proper test administration Providing consistent scoring SZABIST
Validity SZABIST
Validity • Reliability is a necessary but insufficient condition for validity. • A valid instrument must be reliable, but • a reliable instrument may not necessarily be valid. • Validity has been defined by “the extent to which [a test] measures what it claims to measure” (Gregory, 1992, p.117) • Does the test measure what it is supposed to (accuracy)? • Is the test appropriate for its intended use? SZABIST
Validity Coefficient • The validity coefficient is calculated as a correlation between the two items being compared, very typically success in the test as compared with success in the job. • Validity coefficient (r) greater than .4 considered good • A validity of 0.6 and above is considered high, which suggests that very few tests give strong indications of job performance. Example: Is typing speed a valid measure of secretary performance? SZABIST
Types of validity Content validity Criterion validity Construct validity Face validity SZABIST
1. Content Validity • Extent to which • test items sample the content that they are supposed to measure • Does the content of the test represent aspects of the job? • Content under-representation occurs when important areas are missed. SZABIST
According to several studies (Crocker & Algina, 1986; DeVellis, 1991; Gregory, 1992). • Content validity considers whether or not the items on a given test accurately reflect the theoretical domain of the latent construct it claims to measure. Items need to effectively act as a representative sample of all the possible questions that could have been derived from the construct SZABIST
2. Criterion Validity • How well does a predictor relate to the criterion? • Criterion validity refers to the extent to which a test score is related to some measure of job performance • Criterion Validity has two types: • Concurrent validity • Predictive Validity: SZABIST
Concurrent – both predictor and criterion data collected at the same time • : test is given to employees who are working on job. Then we correlate test scores with performance • Example: give test to incumbent and correlate with existing performance records SZABIST
Predictive– predictor test given at one point, then correlated with criterion measure taken at some later time • Test is administered to individuals who are going to be hired. • Example: employees tested prior to training, then scores are correlated with measure of performance taken 6 months later SZABIST
According to Cronbach and Meehl (1955) • If the criterion is obtained some time after the test is given, predictive validity is being studied. However, if the test scores and criterion are “determined at essentially the same time”, then concurrent validity is being examined SZABIST
3. Construct Validity Most theoretical of the validity types Extent to which a test actually measures the construct that it purports to measure (Kaplan & Saccuzzo, 2005) Construct validity is more concerned with inferences about test scores while content validity is more concerned with inferences about the test construction Construct validity is determined by correlating scores of the test with scores from other tests Construct-irrelevant variation occurs when irrelevant factors contaminate the test Example: Do items on a calculus test appear appropriate as a predictor for selecting bus drivers? SZABIST
DeVellis (1991) describes the construct validity of a measure as it: • “is directly concerned with the theoretical relationship of a variable (e.g. a score on some scale) to other variables. It is the extent to which a measure ‘behaves’ the way that the construct it purports to measure should behave with regard to established measures of other constructs” SZABIST
– The extent to which the test is an accurate representation of the theoretical construct • Correlation between scores on tests believed to assess similar constructs • Use to develop new, improved, or shorter tests • Convergent Validity– the correlations should be high for tests of similar constructs • Divergent Validity– Correlations should be low for test of unrelated concepts • Example: Test used for assessing pilots’ flying skill should be highly related to test of spatial ability (convergent), but unrelated to schizophrenia (divergent) SZABIST
Steps for construct validatiom • Crocker and Algina (1986) provide a series of steps to follow when pursuing a construct validation study: • 1) generate hypotheses of how the construct should relate to both other constructs of interest and relevant group differences, • 2) choose a measure that adequately represents the construct of interest, • 3) pursue empirical study to examine the relationships hypothesized, SZABIST
and 4) analyze gathered data to check hypothesized relationships and to assess whether or not alternative hypotheses could explain the relationships found between the variables SZABIST
4. Face Validity Face Validity – Does the test appear to be appropriate by the average person taking the test? Extent to which a test appears to be job related If job applicants do not think a test is job related, their perceptions of its fairness decrease, as does their motivation to do well on the test (Hausknecht, Day & Thomas, 2004) Chan, Schmitt, Deshon, Clause, and elbridge (1997): face validity resulted in high levels of test-taking motivation, which in turn resulted in higher levels of test performance Just b/c a test has face validity does not mean it is valid (Jackson, O’Dell, & Olson, 1982) SZABIST
Thank You! Let us work for the betterment of humanity SZABIST