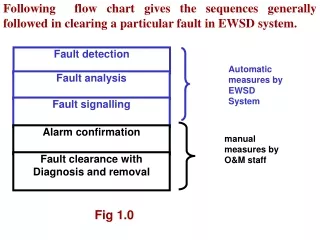
Fault Detection
Fault Detection. Sathish S. Vadhiyar Source/Credits: From Referenced Papers. Introduction. Fine Grain Cycle Sharing (FGCS) Host computers allow guest jobs to utilize CPU cycles Availability of host computers vary Guest jobs may incur resource failures


Fault Detection
E N D
Presentation Transcript
Fault Detection Sathish S. Vadhiyar Source/Credits: From Referenced Papers
Introduction • Fine Grain Cycle Sharing (FGCS) • Host computers allow guest jobs to utilize CPU cycles • Availability of host computers vary • Guest jobs may incur resource failures • Need to predict availability of host computers • A scheduling system can allocate guest jobs based on the availability of host computers
Kinds of Non Availabilities • FRC (Failures Caused by Resource Contention) • A guest job may significantly impact host processes • Hence a guest job can be removed • FRR (Failures Caused by Resource Revocation) • A machine owner suspends resource contribution without notice • Hardware-software failures occur
Resource Failure Prediction • A multi-state failure model and application of a semi-Markov Process (SMP) to predict the temporal reliability • Predicting probability that no resource failure will occur on a machine in a future time window • Observing host resource usage values in a time window; calculating parameters of SMP based on host resource usage values
Multi-state resource failure model • FRR – 2 states • A machine is either available or unavailable • FRC • Failures when host processes incur noticeable slowdown due to contention from guest processes • A host processor can first decrease the priority of guest processes; If this does not help, the guest process is terminated • Measured host resource usage as indicators of noticeable slowdown
Initial Experiments • To study relations between host resource usage and FRC - Experiments conducted to simulate resource contentions between a guest process and host processes • Host-group – an aggregated set of host processes with various resource usages • Slowdown of host group – reduction of its CPU utilization due to contending guest process • Host programs are run with their isolated CPU usage between 10% and 100% • Guest process – a CPU bound program
Experiments on CPU contention • Also measured reduction rate of host CPU usage for a host-group • Experiments repeated with different host groups with host priority 0, and guest priority 0 and 19 (renice) • Measured reduction rate plotted as function of isolated host CPU usage, LH • Found 2 thresholds for LH • Th1 – highest value of LH when guest process needs to be reniced to keep reduction rate below 5% • Th2 – highest value of LH when guest process needs to be suspended to keep reduction rate below 5%
State model for LRC • 3 states • S1 - When LH < Th1; ignore resource contention due to guest processes; slowdown already less than 5% • S2 - When Th1 < LH < Th2; renice guest processes for slowdown to be < 5% • S3 - When LH > Th2; terminate guest process
Experiments on CPU and Memory Contention • When memory trashing occurs • Total memory of guest and host processes exceed available memory size • Experiments were conducted to verify memory trashing does not depend on guest priority • S4 – for failure due to memory trashing
Multi-State Failure Model • Proposed prediction algorithm is to predict the probability that a machine will never transfer to S3, S4, or S5 within a future time window • Transitions • Between S1, S2, S3 – decided by measured host CPU usage • To S4 – when memory is limited
Semi-Markov Process Model (SMP) • Applicable when next transition depends only on • Current state • How long the system at the current state • Transition probabilities depend on amount of time elapsed since last change in state • SMP is defined by a 3-tuple • S – finite set of states • Q – state transition matrix • H – holding time mass function matrix
SMP (Contd…) • The most important statistics of SMP - Interval transition probabilities, P • To calculate P • Continuous time SMP is expensive • Hence the work develops a discrete time SMP model
SMP for Resource Availability • TR – probability of never transferring to S3, S4 or S5 within an arbitrary time window, W • Sinit – initial system state • W – Winit + T • Q and H calculated based on statistics from history logs due to monitoring host resource usage
SMP for Resource Availability • Pi,j(m) = Pi,j(Winit, Winit+m) • P1i,k(l) – interval transition probabilities for a one-step transition • d – time unit of a discretization interval • Q and H calculated based on statistics from history logs due to monitoring host resource usage
System Design and Implementation • Client requests job submission • Client’s job scheduler queries the gateways on available machines for temporal availabilities • Chooses a machine and spawns a guest job • During job execution, monitor detects state transition and notifies gateway • Gateway renices or kills the guest processes accordingly • Resource monitor uses simple cpu commands like `top’ to calculate cpu usages
Computation in Solving SMP • Matrix sparsity in SMP is exploited to reduce computations • The sparse matrix is constructed based on 2 facts: • It takes a finite amount of time to transition from one state to another • S3, S4, S5 are unrecoverable failure states
Prediction Accuracy TR gets close to 0 for large time windows
References • Resource Failure Prediction in Fine-Grained Cycle Sharing Systems. X. Ren, S. Lee, R. Eigenmann, S. Bagchi. HPDC 2006.