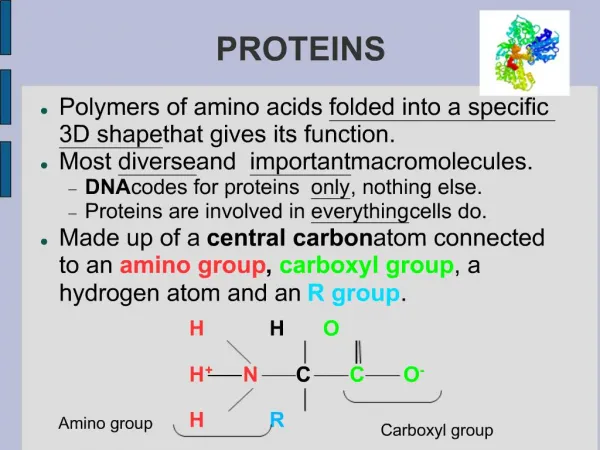
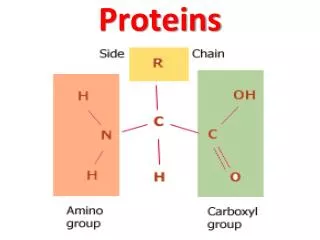
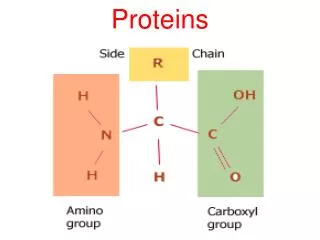
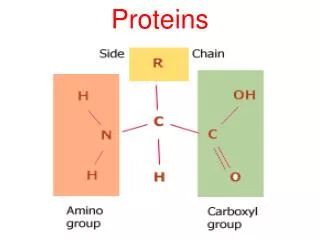
Proteins
Learn about myoglobin, the first high-resolution protein structure, and understand the relationship between protein sequences and their secondary structures such as alpha helices, beta strands, loops, and tertiary structures. Discover how different amino acid sequences can lead to similar protein structures. Explore the methods of protein structure prediction and the importance of structural bioinformatics in understanding protein functions and designing suitable drugs.


Proteins
E N D
Presentation Transcript
Structural Bioinformatics Proteins
Structure Prediction Motivation • Understand protein function • Locate binding sites • Broaden homology • Detect similar function where sequence differs (only ~50% remote homologies can be detected based on sequence) • Explain disease • See effect of amino acid changes • Design suitable compensatory drugs
Myoglobin – the first high resolution protein structure Solved in 1958 by Max Perutz John Kendrew of Cambridge University. Won the 1962 and Nobel Prize in Chemistry. “ Perhaps the most remarkable features of the molecule are its complexity and its lack of symmetry. The arrangement seems to be almost totally lacking in the kind of regularities which one instinctively anticipates.”
From the structure we can get information about the secondary and tertiary structure of the protein What are Secondary Structures ??
Secondary Structure Secondary structure is usually divided into three categories: Anything else – turn/loop Alpha helix Beta strand (sheet)
Alpha Helix: Pauling (1951) • A consecutive stretch of 5-40 amino acids (average 10). • A right-handed spiral conformation. • 3.6 amino acids per turn. • Stabilized by H-bonds 3.6 residues 5.6 Å
Beta Strand: Pauling and Corey (1951) • Different polypeptide chains run alongside each • other and are linked together by hydrogen bonds. • Each section is called β -strand, • and consists of 5-10 amino acids. β -strand
3.25Å 4.6Å 3.47Å 4.6Å Beta Sheet The strands become adjacent to each other, forming beta-sheet. Antiparallel Parallel
Loops • Connect the secondary structure elements. • Have various length and shapes. • Located at the surface of the folded protein and therefore may have important role in biological recognition processes.
Tertiary Structure Describes the packing of alpha-helices, beta-sheets and random coils with respect to each other on the level of one whole polypeptide chain
How does the structure relate to the primary protein sequence??
SEQUENCE • Each protein has a particular 3D structure that determines its function • Early experiments have shown that the sequence of the protein is sufficient to determine its structure • Protein structure is more conserved than protein sequence , and more closely related to function. • Homologous proteins are of the same evolutionary origin. Despite the differences which have been accumulated in their sequences, the structure and function of these proteins can be remarkably conserved. STRUCTURE FUNCTION
How (CAN) Different Amino Acid Sequence Determine Similar Protein Structure ?? Lesk and Chothia 1980
Different sequences can result in similar structures 1ecd 2hhd
We can learn about the important features which determine structure and function by comparing the sequences and structures ?
Where are the gaps?? The gaps in the pairwise alignment are mapped to the loop regions
retinol-binding protein odorant-binding protein apolipoprotein D How are remote homologs related in terms of their structure? RBD b-lactoglobulin
PSI-BLAST alignment of RBP and b-lactoglobulin: iteration 3 Score = 159 bits (404), Expect = 1e-38 Identities = 41/170 (24%), Positives = 69/170 (40%), Gaps = 19/170 (11%) Query: 3 WVWALLLLAAWAAAERD--------CRVSSFRVKENFDKARFSGTWYAMAKKDPEGLFLQ 54 V L+ LA A + S V+ENFD ++ G WY + K Sbjct: 1 MVTMLMFLATLAGLFTTAKGQNFHLGKCPSPPVQENFDVKKYLGRWYEIEKIPASFE-KG 59 Query: 55 DNIVAEFSVDETGQMSATAKGRVRLLNNWDVCADMVGTFTDTEDPAKFKMKYWGVASFLQ 114 + I A +S+ E G + K V + ++ +PAK +++++ + Sbjct: 60 NCIQANYSLMENGNIEVLNKELSPDGTMNQVKGE--AKQSNVSEPAKLEVQFFPL----- 112 Query: 115 KGNDDHWIVDTDYDTYAVQYSCRLLNLDGTCADSYSFVFSRDPNGLPPEA 164 +WI+ TDY+ YA+ YSC + ++ R+P LPPE Sbjct: 113 MPPAPYWILATDYENYALVYSCTTFFWL--FHVDFFWILGRNPY-LPPET 159
The Retinol Binding Protein b-lactoglobulin
PDB: Protein Data Bank • DataBase of molecular structures : Protein, Nucleic Acids (DNA and RNA), • Structures solved by X-ray crystallography NMR Electron microscopy
RCSB PDB – Protein Data Bank http://www.rcsb.org/pdb/
How Many Structures ? March 2008 – 49295 Structures
Structure Prediction: Motivation • Hundreds of thousands of gene sequences translated to proteins (genbanbk, SW, PIR) • Only about ~40000 solved protein structures • Experimental methods are time consuming and not always possible • Goal: Predict protein structure based on sequence information
Prediction Approaches • Primary (sequence) to secondary structure • Sequence characteristics • Secondary to tertiary structure • Fold recognition • Threading against known structures • Primary to tertiary structure • Ab initio modelling
Secondary Structure Prediction • Given a primary sequence ADSGHYRFASGFTYKKMNCTEAA what secondary structure will it adopt ?
RBP RBP (Retinol Binding Protein) Globin
According to the most simplified model: • In a first step, the secondary structure is predicted based on the sequence. • The secondary structure elements are then arranged to produce the tertiary structure, i.e. the structure of a protein chain. • For molecules which are composed of different subunits, the protein chains are arranged to form the quaternary structure.
Secondary Structure Prediction Methods • Chou-Fasman / GOR Method • Based on amino acid frequencies • Machine learning methods • PHDsec and PSIpred • HMM (Hidden Markov Model) • Best accuracy nowadays ~80%
Chou and Fasman (1974) Name P(a) P(b) P(turn) Alanine 142 83 66 Arginine 98 93 95 Aspartic Acid 101 54 146 Asparagine 67 89 156 Cysteine 70 119 119 Glutamic Acid 151 037 74 Glutamine 111 110 98 Glycine 57 75 156 Histidine 100 87 95 Isoleucine 108 160 47 Leucine 121 130 59 Lysine 114 74 101 Methionine 145 105 60 Phenylalanine 113 138 60 Proline 57 55 152 Serine 77 75 143 Threonine 83 119 96 Tryptophan 108 137 96 Tyrosine 69 147 114 Valine 106 170 50 The propensity of an amino acid to be part of a certain secondary structure (e.g. – Proline has a low propensity of being in an alpha helix or beta sheet breaker) Success rate of 50%
Secondary Structure Method Improvements ‘Sliding window’ approach • Most alpha helices are ~12 residues longMost beta strands are ~6 residues long • Look at all windows of size 6/12 • Calculate a score for each window. If >threshold predict this is an alpha helix/beta sheet TGTAGPOLKCHIQWMLPLKK
Improvements since 1980’s • Adding information from conservation in MSA • Smarter algorithms (e.g. HMM, neural networks). Success -> 75%-80%
PHDsec and PSIpred • PHDsec • Rost & Sander, 1993 • Based on sequence family alignments (MaxHom) • PSIpred • Jones, 1999 • Based on Position Specific Scoring Matrix Generated by PSI-BLAST • Both consider long-range interactions
How does secondary structure prediction work? Query Step 1: Generating a multiple sequence alignment SwissProt Query Subject Subject Subject Subject
Steps in secondary structure prediction: Query Step 2: Additional sequences are added using a profile: • A PSI-BLAST PSSM. • A conservation profile (MaxHom). We end up with a MSA which represents the protein family. seed MSA Query Subject Subject Subject Subject
Steps in secondary structure prediction: Query The sequence profile of the protein family is compared (by machine learning methods) to sequences with known secondary structure. seed Machine Learning Approach MSA Known structures Query Subject Subject Subject Subject
A C D E F G H I K L M N P Q R S T V W Y . SS prediction using Neural Network Sequence Profile
A C D E F G Output prediction H= helix E= strand C= Coil Confidence 0=low,9=high H I K L M N P Q R S T V W Y . PHDsec Neural Net Hidden layer (known ss)
HMM • HMM enables us to calculate the probability of assigning a sequence of hidden states to the observation observation TGTAGPOLKCHIQWML HHHHHHHLLLLBBBBB p = ? Hidden state (known ss)
Beginning with an α-helix The probability of observing Alanine as part of a β-sheet α-helix followed by α-helix The probability of observing a residue which belongs to an α-helix followed by a residue belonging to a turn = 0.15 Table built according to large database of known secondary structures
HMM • The above table enables us to calculate the probability of assigning secondary structure to a protein • Example TGQ HHH p = 0.45 x 0.041 x 0.8 x 0.028 x 0.8x 0.0635 = 0.0020995