Download

1 / 66
660 likes | 1.05k Views
Lecture #3: Modeling spatial autocorrelation in normal, binomial/logistic, and Poisson variables: autoregressive and spatial filter specifications. Spatial statistics in practice Center for Tropical Ecology and Biodiversity, Tunghai University & Fushan Botanical Garden.

E N D
Lecture #3:Modeling spatial autocorrelation in normal, binomial/logistic, and Poisson variables: autoregressive and spatial filter specifications Spatial statistics in practice Center for Tropical Ecology and Biodiversity, Tunghai University & Fushan Botanical Garden
Topics for today’s lecture • Autoregressive specifications and normal curve theory (PROC NLIN). • Auto-binomial and auto-Poisson models: the need for MCMC. • Relationships between spatial autoregressive and geostatistical models • Spatial filtering specifications and linear and generalized linear models (PROC GENMOD). • Autoregressive specifications and linear mixed models (PROC MIXED). • Implications for space-time datasets (PROC NLMIXED)
What is an auto- model? Y is on both sides of the = sign
Popular autoregressive equations for the normal probability model 2nd-order models 1st-order model M is diagonal, and often is I A normality assumption usually is added to the error term.
spatial autoregressionThe workhorse of classical statistics is linear regression; the workhorse of spatial statistics is nonlinear regression. The simultaneous autoregressive (SAR) model where denotes the spatial autocorrelation parameter
Georeference data preparation • Concern #1: the normalizing factor • Rule: probabilities must integrate/sum to 1 • Both a spatially autocorrelated and unautocorrelated mathematical space must satisfy this rule • Jacobian term for Gaussian RVs – a function of the eigenvalues of matrix W (or C) non- symmetric set of eigenvalues symmetric set of eigenvalues
Calculation of the Jacobian term Step 1 extract the eigenvalues from n-by-n matrix W (or C) - eigenvalues are the n solutions to the equation det(W – I) = 0 - eigenvectors are the n solutions to the equation (W - I)E = 0. Step 2 (from matrix determinant) compute ; J2 is
Minimizing SSE MINOLS: 1.1486 MIN with Jacobian, which is a weight: 1.8959 worst case scenario 0.9795 Relative plots (in z scores) 1.0542
Gaussian approximations allow an evaluation of redundant information effective sample size
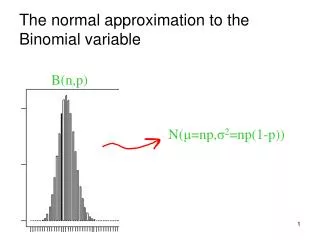
The auto-binomial/logistic model NOTE: a data transformation does not exist that enables binary 0-1 responses to conform closely to a bell-shaped curve
Primary sources of overdispersion: binomial extra variation [Var(Y) = np(1-p) , and >1] • misspecification of the mean function • nonlinear relationships & covariate interactions • presence of outliers • heterogeneity or intra-unit correlation in group data • inter-unit spatial autocorrelation • choosing an inappropriate probability model to represent the variation in data • excessive counts (especially 0s)
The auto-binomial/logistic model • By definition, a percentage/binary response variable is on the left-hand side of the equation, and some spatial lagged version of this response variable also is on the right-hand side of the equation. • Unlike the auto-Gaussian model, whose normalizing constant (i.e., its Jacobian term) is numerically tractable, here the normalizing constant is intractable. • A specific relationship tends to hold between the logistic model’s intercept and autoregressive parameters.
Pseudo-likelihood estimation Maximum pseudo-likelihood treats areal unit values as though they are conditionally independent, and is equivalent to maximum likelihood estimation when they are independent. Each areal unit value is regressed on a function of its surrounding areal unit values. Statistical efficiency is lost when dependent values are assumed to be independent.
Quasi-likelihood estimation Maximum quasi-likelihood treats the variation of Y values as though it is inflated, and estimates of the variance term np(1-p) for the purpose of rescaling when testing hypotheses. This approach is equivalent to maximum likelihood estimation when = 1, and most log-likelihood function asymptotic theory transfers to the results.
Preliminary estimation (pseudo- and quasi-likelihood) results: F/P (%)
What is the alternative to pseudo-likelihood? MCMC maximum likelihood estimation! exploits the sufficient statistics based upon Markov chain transition matrices converging to an equilibrium exploits marginal probabilities, and hence can begin with pseudo-likelihood results based upon simulation theory
Properties of estimators: a review • Unbiasedness • Efficiency • Consistency • Robustness • BLUE • BLUP • Sufficiency
MCMC maximum likelihood estimation • MCMC denotes Markov chain Monte Carlo • Pseudo-likelihood works with the conditional marginal models • MCMC is needed to compute the simultaneous likelihood result • MCMC exploits the conditional models
The theory of Markov chains was developed by Andrei Markov at the beginning of the 20th century. A Markov chain is a process consisting of a finite number of states and known probabilities, pij, of moving from state i to state j. Markov chain theory is based on the Ergodicity Thm: irreducible, recurrent non-null, and aperiodic. If a Markov chain is ergodic, then a unique steady state distribution exists, independent of the initial state: for transition matrix M, ; P(Xt+1 = j| X0=i0, …, Xt=it) = P(Xt+1 = j| Xt=it) = tpij
Monte Carlo simulation is named after the city in the Monaco principality, because of a roulette, a simple random number generator. The name and the systematic development of Monte Carlo methods date from about 1944. The Monte Carlo method provides approximate solutions to a variety of mathematical problems by performing statistical sampling experiments with a computer using pseudo-random numbers.
MCMC has been around for about 50 years. MCMC provides a mechanism for taking dependent samples in situations where regular sampling is difficult, if not completely impossible. The standard situation is where the normalizing constant for a joint or a posterior probability distribution is either too difficult to calculate or analytically intractable.
What is MCMC? A definition MCMC is used to simulate from some distribution p known only up to a constant factor, C: pi = Cqi where qi is known but C is unknown and too horrible to calculate. MCMC begins with conditional (marginal) distributions, and MCMC sampling outputs a sample of parameters drawn from their joint (posterior) distribution.
Starting with any Markov chain having transition matrix M over the set of states i on which p is defined, and given Xt = i, the idea is to simulate a random variable X* with distribution qi: qij = P(X* = j| Xt = i). The distribution qi is called the proposal distribution. po = 0.5 After a burn-in set of simulations, a chain converges to an equilibrium p=0.2
Gibbs sampling is a MCMC scheme for simulation from pwhere a transition kernel is formed by the full conditional distributions of p. • a stochastic process that returns a different result with each execution; a method for generating a joint empirical distribution of several variables from a set of modelled conditional distributions for each variable when the structure of data is too complex to implement mathematical formulae or directly simulate. • a recipe for producing a Markov chain that yields simulated data that have the correct unconditional model properties, given the conditional distributions of those variables under study. • its principal idea is to convert a multivariate problem into a sequence of univariate problems, which then are iteratively solved to produce a Markov chain.
(1) t = 0; set initial values 0x = (0x1, …, 0xn)’ (2) obtain new values tx = (tx1, …, txn)’ from t-1x:tx1 ~ p(x1|{t-1x2, …, t-1xn)tx2 ~ p(x2|{tx1, t-1x3, …, t-1xn) …txn ~ p(x1|{tx1, …, txn-1) (3) t = t+1; repeat step (2) until convergence. A Gibbs sampling algorithm
Monitoring convergence After removing burn-in iteration results, a chain should be weeded (i.e., only every kth output is retained). These weeded values should be independent; this property can be checked by constructing a correlogram. MCMC exploits the sufficient statistics, which should be monitored with a time-series plot for randomness. Convergence of m chains can be assessed using ANOVA: within-chain variance pooling is legitimate when chains have converged.
Sufficient statistics for normal, binomial, and Poisson models A sufficient statistic (established with the Rao-Blackwell factorization theorem) is a statistic that captures all of the information contained in a sample that is relevant to the estimation of a population parameter.
Implementation of MCMC for the autologistic model drawings from the binomial distribution is the Monte Carlo part MCMC-MLEs are extracted from the generated chains
25,000 + 225,000/100 burn-in + weeded MCMC results
The (modified) auto-Poisson model NOTE: the auto-Poisson model can only capture negative spatial autocorrelation NOTE: excessive zeroes is a serious problem with empirical Poisson RVs
Spatial autoregression: the auto-Poisson modelThe workhorse of spatial statistical generalized linear models is MCMC For counts, y, in the set of integers {0, 1, 2, 3, … }
MCMC is initiated with pseudo-likelihood estimates c-1 is an intractable normalizing factor positive spatial autocorrelation can be handled with Winsorizing, or binomial approximation
When VAR(Y) >overdispersion (extra Poisson variation) is encountered Detected when deviance/df > 1 Often described as VAR(Y) = Leads to the Negative Binomial model Conceptualized as the number of times some phenomenon occurs before a fixed number of times (r) that it does not occur.
Preliminary estimation (pseudo- and quasi-likelihood) results: B/D
25,000 + 500,000/100 burn-in + weeded MCMC results typical correlogram
Geographic covariation:n-by-n matrix V autoregression works with the inverse covariance matrix & geostatistics works with the covariance matrix itself
Relationships between the range parameter and rho for an ideal infinite surface modified Bessel function for CAR Bessel function for SAR
Constructing eigenfunctions for filtering spatial autocorrelation out of georeferenced variables: MC = (n/1T C1)x YT(I – 11T/n)C (I – 11T/n)Y/ YT(I – 11T/n)Y the eigenfunctions come from (I – 11T/n)C (I – 11T/n)
Eigenvectors of MCM • (I – 11T/n) = M ensures that theeigenvector means are 0 • symmetry ensures that the eigenvectors are orthogonal • M ensures that the eigenvectors are uncorrelated • replacing the 1st eigenvalue with 0 inserts the intercept vector 1 into the set of eigenvectors • thus, the eigenvectors represent all possible distinct (i.e., orthogonal and uncorrelated) spatial autocorrelation map patterns for a given surface partitioning • Legendre and his colleagues are developing analogous eigenfunction spatial filters based upon the truncated distance matrix used in geostatistics
Expectations for the Moran Coefficient for linear regression with normal residuals
A spatial filtering counterpart to the auto-normal model specification. • Y = Ekß + ε • b = EkTY • Only a single regression is needed to implement the stepwise procedure. MAX: R2; eigenvectors selected in order of their bivariate correlations residual spatial autocorrelation =
Overdispersion: binomial extra variation • E(Y) = np and Var(Y) = np(1-p) , and >1 • tends to have little impact on regression parameter point estimates (maximum likelihood estimator typically is consistent, although small sample bias might occur); but, regression parameter standard error estimates (variances/covariances) are underestimated • may be reflected in the size of the deviance statistic • difficult to detect in binary 0-1 data
Spatial structure and generalized linear modeling: “Poisson” regression CBR: the spatial filter is constructed with 199 of 561 candidate eigenvectors. SF results in green SF
Spatial structure and generalized linear modeling: “binomial” regression % population 100+ years old: the spatial filter is constructed with 92 of 561 candidate eigenvectors. SF