Calculating Discrete Logarithms
Calculating Discrete Logarithms. John Hawley Nicolette Nicolosi Ryan Rivard. Discrete Logarithms. We want to find a unique integer x such that α x = β (mod n) . We can find x by solving: x = log α β (mod n) . But…. Logarithms are easy!.


Calculating Discrete Logarithms
E N D
Presentation Transcript
Calculating Discrete Logarithms John Hawley Nicolette Nicolosi Ryan Rivard
Discrete Logarithms • We want to find a unique integer x such that αx = β (mod n). • We can find x by solving:x = logαβ (mod n). • But…
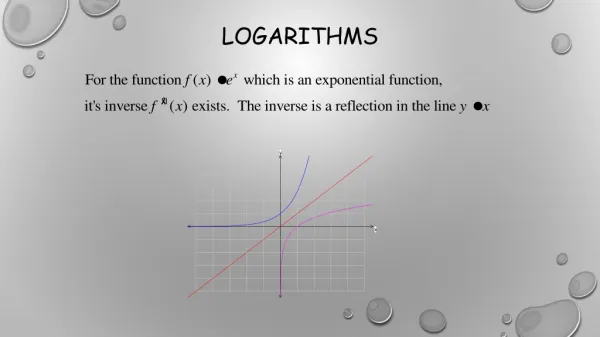
Logarithms are easy! • Logarithms in real numbers are easy to calculate, partially because the log function is continuous and monotonically increasing. • Discrete Logarithms don’t have either of these properties. For example, in a (mod 5) system, the powers of 2 are 1, 2, 4, 3. • This wraparound makes the discrete log function significantly harder to compute than the ordinary log function.
Definitions • Multiplicative Group • A set of congruence classes that are relatively prime to the modulus. We used the group Zp, where the modulus is a prime number and the group is cyclic (the values repeat).
Definitions • Order of a Group • The number of elements in a group, which can be found using Euler’s totient function • For Zp, this is p − 1 • For Zpk, it is (p − 1) pk − 1 • Generators and Primitive Elements • An element that produces the other elements of the group when raised to various powers. Primitive elements are also generators.
The Problem • We have a multiplicative group (G, *), α is a generator of G having order n, and β is an element generated by α. • Remember, we want to find a unique integer x such that αx = β (mod n), by solving x = logαβ (mod n).
The Problem • Computing αx = β for a given x is simple and efficient using the square-and-multiply algorithm for exponentiation. • Computing a = logαβ is difficult and can consume a large amount of time and memory for large values, such as those used in cryptography.
The Problem • This property makes discrete logs ideal for cryptographic applications because one function is easy, but the inverse function is difficult. • There is a class of public-key cryptosystems that use the discrete logarithm problem for key generation and encryption/decryption.
The El Gamal Cryptosystem • p is a prime number chosen so that the Discrete Logarithm problem is infeasible in (Zp*, *). • α is a generator in Zp*. • β is computed as follows: β = αxmod p • The public key consists of p, α, and β. • The private key is x.
Attacking El Gamal • An attacker wants to obtain the private key x so that they can encrypt and decrypt messages as the user. • An attack using the Discrete Logarithm problem would attempt to compute x = logαβ (mod p). • Given that α, β, and p are part of the public key, this attack does not require intercepting any data other than the public key.
The Algorithm • By rewriting αx = β in the form β(α−m)i = αj, where x = im + j, we can precompute values of αj for several values of j, storing them in a hash table. • The highest j computed can be used for m and values of i can be iteratively tried on the left-hand side of the equation.
The Algorithm • The running time is O(m + n/m), where m is the number of entries in the hash table. • Optimal running time when m = sqrt(n), but this might not be feasible based on the amount of available memory. • For example, a 512-bit n would require 2256 hash table entries for optimal performance, but even at a single byte per entry (a significant underestimate), this is over 1065Terabytes of data.
Pseudocode BABY-STEP-GIANT-STEP(α, β, m, n) FOR j IN [0, m] HASH-TABLE-PUT(αj (mod n), j) Compute α−m (mod n) γ←β FOR i IN [0, ceil(n/m)] IF HASH-TABLE-CONTAINS-KEY(γ) j ← HASH-TABLE-GET(γ) RETURN (i * m) + j ELSE γ←γ∗α−m (mod n)
Benefits of Parallelization • Being able to compute Discrete Logarithms faster for large values could make cryptosystems that use this problem vulnerable to attack. • Discovering this could result in more secure encryption of confidential data using systems that are not vulnerable to this attack.
Implementation • The hash table can be distributed in order to take advantage of total memory capacity of a cluster. • Each node can independently build a portion of the hash table. A barrier can be used to ensure that all nodes have completed this first stage before continuing. • Once the hash table has been generated, each node can perform a subset of the collision checks independently. Thus, the only communication ever required between nodes is to handle the distributed hash table inserts/lookups.
Implementation Drawbacks • Whenever a node needs to look up a hash table key that is stored on another node, network latency becomes a factor. • While hash tables for very large numbers will quickly exhaust available memory, numbers that are reasonably sized for running tests on the Paranoia cluster do not even come close to this limit. • Better performance may be seen on SMP machines, but the number of processors available is limited. Hybrid SMP/Cluster parallel systems might be an effective compromise.
Alternative Ideas • Since the hash tables for the problems we are solving are small enough to fit on a single node, we could fill the table in a distributed manner, and all-gather the resulting hash table. Each node would then have a local copy of the table and network latency would be eliminated for hash table lookups. • Each node could perform only hash-put and hash-get requests on its local table, and could simply ignore requests for other nodes. In this way, the nodes would all be testing the same values, but would still benefit from the increased memory of a cluster over a single machine.
Results • Initial increase of processors from 1 to 2 showed a large slowdown. • Large number of sends / receives • Decent speedup from 2 to 32 processors
Results • Limited time for testing does not allow us to use the algorithm’s full potential • Algorithm is based on a trade off of memory and time • Optimal size for hash table is sqrt(n) entries • On small 32 bit numbers, memory usage is only around 256kb
Results • Any recent cryptosystem will use at least 128bit numbers. • To use the optimal sqrt(n) entries, this would require approximately 268,435,456 Terabytes of memory • Clearly an infeasible amount to use the optimally sized hash table on a single (or multiple) machines.
Results • Distributed memory allows us to use a larger hash map, thus reducing the runtime of the algorithm • Results expected to surpass linear speedup, due to an improvement in the asymptotic running time.
Conclusions • The speedup observed from 2 to 32 processors points towards MPI overhead as major cause for initial slowdown. • On small data, shared memory would have been a better choice • Still can use optimally sized hash map • Small overhead, little synchronization needed