DBMS support of the Data Mining
540 likes | 811 Views
DBMS support of the Data Mining. Advisor : S.-Y. Hwang Ph.D D954020005 Tsung-Hsien Yang D954020006 Shi-Hwao Wang 1/22/2008. Agenda. Introduction to Data Mining The Promise of Data Mining KDD Process Data Mining Algorithms Data Mining Modeling and Language Conclusion.

DBMS support of the Data Mining
E N D
Presentation Transcript
DBMS support of the Data Mining Advisor : S.-Y. Hwang Ph.D D954020005 Tsung-Hsien Yang D954020006 Shi-Hwao Wang 1/22/2008
Agenda • Introduction to Data Mining • The Promise of Data Mining • KDD Process • Data Mining Algorithms • Data Mining Modeling and Language • Conclusion
Introduction to Data Mining • The Explosive Growth of Data: from terabytes to petabytes • Major sources of abundant data • Business: Web, e-commerce, transactions, stocks, … • Science: Remote sensing, bioinformatics, scientific simulation, … • Society and everyone: news, digital cameras, YouTube • Data collection and data availability • Automated data collection tools, database systems, Web, computerized society
What Is Data Mining? • Data mining: Discovering interesting patterns from large amounts of data • Data mining (knowledge discovery from data) • Extraction of interesting (non-trivial,implicit, previously unknown and potentially useful) patterns or knowledge from huge amount of data • Alternative names • Knowledge discovery (mining) in databases (KDD), knowledge extraction, data/pattern analysis, data archeology, data dredging, information harvesting, business intelligence, etc. • Watch out: Is everything “data mining”? • Simple search and query processing • (Deductive) expert systems
The Promise of Data Mining • Database analysis and decision support • Market analysis and management • target marketing, customer relation management, market basket analysis, cross selling, market segmentation • Risk analysis and management • Forecasting, customer retention, improved underwriting, quality control, competitive analysis • Fraud detection and management • Other Applications • Text mining (news group, email, documents) and Web analysis.
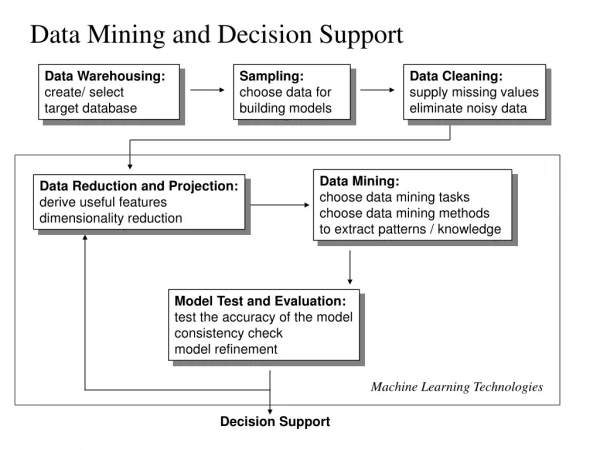
Knowledge Discovery (KDD) Process Knowledge Pattern Evaluation • Data mining—core of knowledge discovery process Data Mining Task-relevant Data Selection Data Warehouse Data Cleaning Data Integration Databases
Train the model Training Data Test the model Prediction using the model Test Data Prediction Input Data Data preprocessing Define a model Data Mining Management System (DMMS) Mining Model
Data Mining Algorithms • Decision Trees • Naïve Bayesian • Clustering • Sequence Clustering • Association Rules • Neural Network • Time Series • Support Vector Machines • ….
Data Mining Function • Classification (attribute) • Estimation (regression) • Prediction (time series) • Association (cross selling) • Clustering (segmentation)
Data Mining Algorithms √ - first choice √ - second choice Association rules Seq. Clustering Neural Network Decision Trees Naïve Bayes Time Series Clustering Classification Regression Segmentaion Assoc. Analysis Anomaly Detect. Seq. Analysis Time series
Data Mining Language • New challenges in data mining API • Large spectrum of applications: embedded to interactive BI • Interoperability between different DM providers (engine) and DM consumers (tools) • Data independence between content representation (trees, attributes, networks, etc) and data mining task (prediction, scoring, etc) • Requirements: • Algorithm-neutral • Task-oriented (specification of what we need, rather than how to) • Vendor-neutral • Flexible, extensible, declarative/self-contained • Sound familiar? • Yes, SQL
DMX Approach • Data Mining Extensions (DMX) to SQL • Table vs. Mining Model
Train a model: INSERT INTO dmm …. Training Data Prediction using a model: SELECT … FROM dmm PREDICTION JOIN … Mining Model Prediction Input Data Typical DM Process Using DMX Define a model: CREATE MINING MODEL …. Data Mining Management System (DMMS)
Defining a DM Model • Defines • Shape of “training cases” (top-level entity being modeled) • Input/output attributes (variables): type, distribution • Algorithms and parameters • Example CREATE MINING MODEL CollegePlanModel ( StudentID LONG KEY, Gender TEXT DISCRETE, ParentIncome LONG NORMAL CONTINUOUS, Encouragement TEXT DISCRETE, CollegePlans TEXT DISCRETE PREDICT ) USING Microsoft_Decision_Trees (complexity_penalty = 0.5)
Training a DM Model: Simple INSERT INTO CollegePlanModel (StudentID, Gender, ParentIncome, Encouragement, CollegePlans) OPENROWSET(‘<provider>’, ‘<connection>’, ‘SELECT StudentID, Gender, ParentIncome, Encouragement, CollegePlans FROM CollegePlansTrainData’)
Prediction Using a DM Model • PREDICTION JOIN SELECT t.ID, CPModel.Plan FROM CPModel PREDICTION JOIN OPENQUERY(…,‘SELECT * FROM NewStudents’) AS t ON CPModel.Gender = t.Gender AND CPModel.IQ = t.IQ CPModel NewStudents
Classification • Model Definition CREATE MINING MODEL CPClass ( StudentID LONG KEY, Gender TEXT DISCRETE, ParentIncome LONG CONTINUOUS, Encouragement TEXT DISCRETE, CollegePlans TEXT DISCRETE PREDICT ) USING Microsoft_Decision_Trees
Classification (cont) • Find the new students whose predicted class (CollegePlan) is ‘Yes’ with confidence > 0.8 SELECT StudentID, PredictProbability(CPClass.CollegePlan) FROM CPClass PREDICTION JOIN OPENROWSET (’<provider>’,’<connection>’, ’SELECT * FROM NewStudents’) AS t ON t.Gender = CPClass.Gender AND t.ParentIncome = CPClass.ParentIncome AND t.Encouragement = CPClass.Encouragement WHERE CPClass.CollegePlan = ‘Yes’ AND PredictProbability(CPClass.CollegePlan) > 0.8
Regression • Model Definition CREATE MINING MODEL CustCredit ( CustID LONG KEY, Gender TEXT DISCRETE, Age TEXT CONTINUOUS REGRESSOR, Income LONG CONTINUOUS REGRESSOR, Credit DOUBLE CONTINUOUS PREDICT ) USING Microsoft_Decision_Trees
Regression (cont) • Predict Credit score (and stdev) for the new customer data entered from the web form. SELECT CustCredit.Credit, PredictStdev(CustCredit.Credit) FROM CustCredit PREDICTION JOIN (SELECT ’Female’ AS Gender, 30 AS Age, 50000 AS Income) AS t ON t.Gender = CustCredit.Gender AND t.Age = CustCredit.Age AND t.Income = CustCredit.Income
Segmentation • Model Definition CREATE MINING MODEL CPCluster ( StudentID LONG KEY, Gender TEXT DISCRETE, ParentIncome LONG CONTINUOUS, Encouragement TEXT DISCRETE, CollegePlans TEXT DISCRETE ) USING Microsoft_Clustering
Segmentation (cont.) • Find cluster and its probability for each student SELECT StudentID, $Cluster, ClusterProbability() FROM CPCluster PREDICTION JOIN OPENROWSET (’<provider>’,’<connection>’, ’SELECT * FROM NewStudents’) AS t ON t.Gender = CPCluster.Gender AND t.ParentIncome = CPCluster.ParentIncome AND t.Encouragement = CPCluster.Encouragement AND t.CollegePlans = CPCluster.CollegePlans
Association Prediction • Model Definition CREATE MINING MODEL FavMovieModel ( ID LONG KEY, MaritalStatus TEXT DISCRETE, FavMovies TABLE PREDICT ( Title TEXT KEY ) ) USING Microsoft_Decision_Trees
Association Prediction (cont) • As a web application, find 5 best recommendations for a customer whose shopping cart contains ‘Star Wars’ and ‘Matrix’. SELECT FLATTENED PredictAssociation(FavMovieModel.FavMovies, INCLUDE_STATISTICS, 5) FROM FavMovieModel NATURAL PREDICTION JOIN (SELECT ’Single’ AS MaritalStatus, (SELECT ’Star Wars’ AS Title UNION SELECT ’Matrix’ AS Title) AS FavMovies) AS t
Sequence Prediction • Model Definition CREATE MINING MODEL WebSeqModel ( Session LONG KEY, PageSeq TABLE PREDICT ( SeqID LONG KEY SEQUENCE, Page TEXT DISCRETE ) ) USING Microsoft_Sequence_Clustering
Sequence Prediction (cont) • Show the next 2 steps that a web visitor who visited ‘home’ ‘news’ is going to take. For each step, it has to show top 5 candidate pages with the highest probability. SELECT FLATTENED ( SELECT $Sequence, TopCount(PredictHistogram(Page), $Probability, 5) FROM PredictSequence(WebSeqModel.PageSeq, 2) ) FROM WebSeqModel NATURAL PREDICTION JOIN (SELECT (SELECT 1 AS SeqID, ’home’ AS Page UNION SELECT 2 AS SeqID, ’news’ AS Page) AS PageSeq ) AS t
Time-Series Prediction • Model Definition CREATE MINING MODEL StockModel ( Symbol LONG KEY, DateRecorded DATE KEY TIME, OpeningQuote DOUBLE CONTINUOUS, ClosingQuote DOUBLE CONTINUOUS ) USING Microsoft_Time_Series
Time-Series Prediction (cont) • Predict next five days of MSFT stock closing quotes. SELECT FLATTENED PredictTimeSeries(StockModel.ClosingQuote, 5) FROM FavMovieModel WHERE StockModel.Symbol = ’MSFT’
Major Issues in Data Mining • Mining methodology • Mining different kinds of knowledge from diverse data types, e.g., bio, stream, Web • Performance: efficiency, effectiveness, and scalability • Pattern evaluation: the interestingness problem • Incorporation of background knowledge • Handling noise and incomplete data • Parallel, distributed and incremental mining methods • Integration of the discovered knowledge with existing one: knowledge fusion • User interaction • Data mining query languages and ad-hoc mining • Expression and visualization of data mining results • Interactive mining ofknowledge at multiple levels of abstraction • Applications and social impacts • Domain-specific data mining & invisible data mining • Protection of data security, integrity, and privacy
Data Mining Vendors • SAS (Enterprise Miner) • IBM (DB2 Intelligent Miner) • Oracle (ODM option to Oracle 10g) • SPSS (Clementine) • Insightsful (Insightful Miner) • KXEN (Analytic Framework) • Prudsys (Discoverer and its family) • Microsoft (SQL Server 2005) • Angoss (KnowledgeServer and its family) • DBMiner (DBMiner) • Many others
Increasing potential to support business decisions End User Making Decisions Business Analyst Data Presentation Visualization Techniques Data Mining Data Analyst Information Discovery Data Exploration Statistical Analysis, Querying and Reporting Data Warehouses / Data Marts OLAP, MDA DBA Data Sources Paper, Files, Information Providers, Database Systems, OLTP Data Mining and Business Intelligence
Data Mining Modeling and Language • Problem Description • two powerful tools • Database management systems • Efficient and effective data mining algorithms and frameworks • Generally, this work asks: • “How can we merge the two?” • “How can we integrate data mining more closely with traditional database systems, particularly querying?”
Three Different Answers • MSQL: A Query Language for Database Mining (Imielinski & Virmani, Rutgers University) • DMQL: A Data Mining Query Language for Relational Databases (Han et al, Simon Fraser University) • Integrating Data Mining with SQL Databases: OLE DB for Data Mining (Netz et al, Microsoft)
MSQL • Focus on Association Rules • Seeks to provide a language both to selectively generate rules, and separately to query the rule base • Expressive rule generation language, and techniques for optimizing some commands
MSQL • Get-Rules and Select-Rules Queries • Get-Rules operator generates rules over elements of argument class C, which satisfy conditions described in the “where” clause [Project Body, Consequent, confidence, support] GetRules(C) [as R1] [into <rulebase_name>] [where <conds>] [sql-group-by clause] [using-clause]
MSQL • <conds> may contain a number of conditions, including: • restrictions on the attributes in the body or consequent • “rule.body HAS {(Job = ‘Doctor’}” • “rule1.consequent IN rule2.body” • “rule.consequent IS {Age = *}” • pruning conditions (restrict by support, confidence, or size) • Stratified or correlated subqueries in, has, and is are rule subset, superset, and equality respectively
MSQL GetRules(Patients) where Body has {Age = *} and Support > .05 and Confidence > .7 and not exists ( GetRules(Patients) Support > .05 and Confidence > .7 and R2.Body HAS R1.Body) Retrieve all rules with descriptors of the form “Age = *” in the body, except when there is a rule with equal or greater support and confidence with a rule containing a superset of the descriptors in the body
MSQL GetRules(C) R1 where <pruning-conds> and not exists ( GetRules(C) R2 where <same pruning-conds> and R2.Body HAS R1.Body) correlated GetRules(C) R1 where <pruning-conds> and consequent is {(X=*)} and consequent in (SelectRules(R2) where consequent is {(X=*)} stratified
MSQL • Nested Get-Rules Queries and their optimization • Stratified (non-corrolated) queries are evaluated “bottom-up.” The subquery is evaluated first, and replaced with its results in the outer query. • Correlated queries are evaluated either top-down or bottom-up (like “loop-unfolding”), and there are rules for choosing between the two options
MSQL Top-Down Evaluation GetRules(Patients) where Body has {Age = *} and Support > .05 and Confidence > .7 For each rule produced by the outer, evaluate the inner not exists ( GetRules(Patients) Support > .05 and Confidence > .7 and R2.Body HAS R1.Body)
MSQL Bottom-Up Evaluation not exists ( GetRules(Patients) Support > .05 and Confidence > .7 and R2.Body HAS R1.Body) For each rule produced by the inner, evaluate the outer GetRules(Patients) where Body has {Age = *} and Support > .05 and Confidence > .7
DMQL • Commands specify the following: • The set of data relevant to the data mining task (the training set) • The kinds of knowledge to be discovered • Generalized relation • Characteristic rules • Discriminant rules • Classification rules • Association rules
DMQL • Commands Specify the following: • Background knowledge • Concept hierarchies based on attribute relationships, etc. • Various thresholds • Minimum support, confidence, etc.
Specify background knowledge Specify rules to be discovered Collect the set of relevant data to mine Specify threshold parameters Relevant attributes or aggregations DMQL • Syntax use database <database_name> {use hierarchy <hierarchy_name> for <attribute>} <rule_spec> related to <attr_or_agg_list> from <relation(s)> [where <conditions>] [order by <order list>] {with [<kinds of>] threshold = <threshold_value> [for <attribute(s)>]}
DMQL use database Hospital find association rules as Heart_Health related to Salary, Age, Smoker, Heart_Disease from Patient_Financial f, Patient_Medical m where f.ID = m.ID and m.age >= 18 with support threshold = .05 with confidence threshold = .7
DMQL • DMQL provides a display in command to view resulting rules, but no advanced way to query them • Suggests that a GUI interface might aid in the presentation of these results in different forms (charts, graphs, etc.)
OLE DB for DM • An extension to the OLE DB interface for Microsoft SQL Server • Seeks to support the following ideas: • Define a model by specifying the set of attributes to be predicted, the attributes used for the prediction, and the algorithm • Populate the model using the training data • Predict attributes for new data using the populated model • Browse the mining model (not fully addressed because it varies a lot by model type)
OLE DB for DM • Defining a Mining Model • Identify the set of data attributes to be predicted, the set of attributes to be used for prediction, and the algorithm to be used for building the model • Populating the Model • Pull the information into a single rowset using views, and train the model using the data and algorithm specified
OLE DB for DM • Using the mining model to predict • Defines a new operator prediction join. A model may be used to make predictions on datasets by taking the prediction join of the mining model and the data set.
OLE DB for DM CREATE MINING MODEL Heart_Health Prediction ( ID Int Key, Age Int, Smoker Int, Salary Double discretized, HeartAttack Int PREDICT, %Prediction column ) USING Microsoft_Decision_Trees Identifies the source columns for the training data, the column to be predicted, and the data mining algorithm.