Download
1 / 34
340 likes | 565 Views
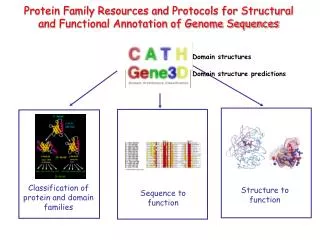
Protein Family Resources and Protocols for Structural and Functional Annotation of Genome Sequences. Domain structures. Domain structure predictions. Classification of protein and domain families. Structure to function. Sequence to function. H. A. T. C. Fold Group (1100).

E N D
Protein Family Resources and Protocols for Structural and Functional Annotation of Genome Sequences Domain structures Domain structure predictions Classification of protein and domain families Structure to function Sequence to function
H A T C Fold Group (1100) 40,000 domain entries Homologous Superfamily (2100) Gene3D Sequence Family ~100,000 domains of known structure in CATH ~2 million sequences from genomes assigned to CATH superfamilies in Gene3D and functionally annotated
Gene3D:Domain structure annotations in genome sequences ~5 million protein sequences from 560 completed genomes and UniProt ~ 2 million domain sequences assigned to CATH superfamilies scan against library of HMM models and sequences for CATH Pfam NewFam superfamilies
Gene3D (1) Cluster ~5 million sequences into protein superfamilies (2) Map domains onto the sequences using HMM technology (CATH & Pfam domains) >200,000 protein superfamilies ~10,000 domain superfamilies (2100 of known structure)
Proportion of genome sequences which can be assigned to domain families of known structure in CATH or SCOP HMM prediction threading prediction
Annotation levels for an average genome 100% many belonging to small species specific families many predicted to be transmembrane 50% predicted to belong to structural superfamilies using HMM or threading techniques 0
100 80 60 Percentage of domain sequences 40 20 0 0 1000 2000 3000 4000 5000 6000 Families ordered by size Target selection strategy for PSI-2 Adam Godzik JCSG, Andras Fiser – NYSGC, Burkhard Rost - NESG unknown structure (BIG -Pfam) known structure (CATH - MEGA)
Correlation of sequence and structural variability of CATH families with the number of different functional groups Structural Diversity Population in genomes (x 1000)
Structural diversity in the CATH Domain Superfamily P-loop hydrolases Cutinase Cocaine esterase Acetylcholinesterase
Protein Family Resources and Protocols for Structural and Functional Annotation of Genome Sequences Domain structures Domain structure predictions Sequence to function
Sequence identity thresholds for 90% conservation of enzyme function (to 3 EC Levels) highly variable families Number of sequences Number of families Sequence identity threshold for 90% conservation
N-Fold Increase in Functional Annotation for Sequences in Gene3D N-fold increase in coverage family specific thresholds general thresholds
Gene3D Get an XML version of this page Link to UniProt Links to different levels in the Gene3D protein family Link to InterPro Links to GO Links to KEGG Links to CATH/Pfam “S” - indicates you can search the term against Gene3D Functional information from GO, COGS, KEGG, EC, FunCat, MINT, IntAct, ComplexDB
Functional annotation of structures using EC, GO, KEGG, FunCat resources Non-PSI PDBs PSI PDBs 0 terms 1 term 2 terms 3 terms 4 terms
Phylogenetic trees derived from multiple sequence alignments can be used to infer functionally related proteins Tree Determinants - Valencia Evolutionary Trace - Lichtarge Funshift – Sonnhammer SCI-PHY – Sjolander
Methods exploiting information on sequence conserved residue positions multiple sequence alignment of relatives from functional group 1 = highly conserved Structural model Score conservation for each position in the alignment using an entropy measure 0 = unconserved Putative functional site Scorecons –Thornton Protein Keys – Sander
GEMMA: Compares sequence profiles (HMMs) between subfamilies sequence subfamily 80% seq. id) Superfamily of known structure (CATH) putative structure-function group clusters sequence relatives predicted to have similar structures/functions even at low levels of sequence identity
GeMMA v SCI-PHY using gold annotated sequences in Babbitt benchmark Purity (high is best) Edit distance (low) VI distance (low is best) Deviation from no. singletons (low)
Coverage of superfamily (%) experimental annotations inherit functions at 60% seq. id. inherit functions by GEMMA Functional annotation coverage using different strategies
Protein interactions and gene networks • Gene3D Biominer Methods • Phylotuner: Correlation of domain occurrence profiles • GOSS:Semantic Similarity calculation between protein pairs. • CODA: Domain fusion analysis. • HiPPI: homology inheritance of protein-protein physical interaction data. • GECO: Correlation of gene expression data
Protein Family Resources and Protocols for Structural and Functional Annotation of Genome Sequences Domain structures Domain structure predictions Structure to function
Methods for Assessing Structural Novelty CATHEDRAL – structure comparison Redfern et al. PLOS comp. biol. 2007
Aminoacyl tRNA synthetases Gln-hydrolyzing synthases DNA-binding, stress-related Nucleotidyl-transferases Argininosuccinate lyases Structural clusters in the Aminoacyl tRNA synthetases – like family structure similarity score
Galectin binding superfamily 2.60.120.200 1bkzA00 1dypA00
Aminoacyl tRNA synthetases – like Identifying functional groups in domain superfamilies Deoxyribodi- pyrimidine photo-lyases Electron transfer flavoprotein Nucleotidylyl- transferases AA tRNA synthetase, Class I 1n3lA01 1dnpA00 1ej2A00 1o97D01
Exploiting 3D Templates to Represent Functional Relatives JESS – Thornton GASP - Babbitt SPASM – Kleywegt PINTS – Russell DRESPAT - Sarawagi pvSOAR – Joachimiak
SITESEER: Match 3-residue templates and assess relevance of hits by looking at residues within the local environment Laskowski and Thornton green and purple – identical residues; orange and white – similar residues
FLORA:3D templates for functional groups From multiple structure alignments of functional subgroups in the superfamily, identify vectors between amino acids that are highly conserved and distinctive for the functional subgroup.
FLORA:3D templates for functional groups localFLORA globalFLORA multiple sites single site
FLORA:Performance in recognising functionally related homologues Benchmark of 36 diverse enzyme groups (from 12 families)
Performance of FLORA Benchmarked on 36 large enzyme families
FLORA: 3D Templates for Structure-Function Groups in Domain Families 1q77A00 Unknown function MCSG 1o97D01 Electron transfer flavoprotein 1dnpA01 Deoxyribo- dipyrimidine photo-lyases 1n3lA01 AA tRNA synthetases 1ej2A00 Nucleotidylyl- transferases
Fold and structural motifs n-residue templates Sequence scans Sequence search vs PDB Enzyme active sites SSM fold search Sequence search vs Uniprot Ligand binding sites Surface clefts Sequence motifs (PROSITE, BLOCKS, SMART, Pfam, etc) Residue conservation DNA binding sites DNA-binding HTH motifs Superfamily HMM library Reverse templates Nest analysis Gene neighbours http://www.ebi.ac.uk/thornton-srv/databases/ProFunc/
Function Prediction for Proteins of ‘Putative’ or Unknown Function * Numbers refer to results where the top hit is classed as ‘Strong’ or ‘Moderate’ structural data provides relatively more information for proteins about which there is less knowledge these predictions need to be experimentally validated