Burr Settles
Closing the Loop: Fast, Interactive Semi-Supervised Annotation With Queries on Features and Instances. Burr Settles. Overview. DUALIST – active learning annotation framework which allows annotators to label features and instances


Burr Settles
E N D
Presentation Transcript
Closing the Loop: Fast, Interactive Semi-Supervised AnnotationWith Queries on Features and Instances Burr Settles
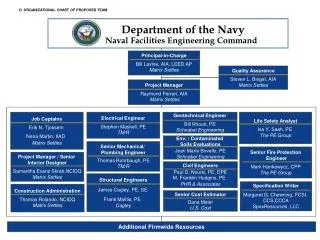
Overview DUALIST – active learning annotation framework which allows annotators to label features and instances Data is a set of Usenet messages on the topic of baseball or hockey The annotation tools lets users annotate features (words) or instances (documents)
Active learning – the classifier queries an oracle on selected instances • The goal is to learn efficiently so that fewer labeled instances are needed • This approach has the classifier in an active role and the oracle in a passive role Introduction The active learning paradigm
Studies often don’t consider human annotation costs • Many algorithms are too slow for human wait-time • Overlooked what additional information the human could offer rather than waiting to be asked Problems with Active Learning Shortcomings and points frequently overlooked in the literature
The DUALIST framework lets the human annotator classify an instance (label the document hockey or baseball), or choose X if ambiguous, which removes it from pool • Also allows feature annotation in word columns. Also user can impart knowledge in text box. • Submit button reclassifies in real-time and offers new set of queries. DUALIST Offers two ways humans can impart information: instances or features
Underlying model MNB (multinomial naïve Bayes) • The likelihood of document x being generated by class yj, where fk(x) is the frequency of word fk in document x. • Since the document length |x| is independent of class, for classification purposes it is dropped, and the posterior probability is calculated using Bayes’ rule, where Z(x) is for normalization: Generative Model Generative models seek underlying distribution while discriminative methods directly estimate probabilities without attempting to model underlying distributions.
Training: • - estimate parameters in θ based on labeled data • Using a Dirichlet prior, count occurrences of fk in documents of class yj, and the prior adds mjk occurrences for a smoothed MLE. • MLE – maximum likelihood estimate – the value(s) of parameters which make the known likelihood distribution a maximum Estimating priors Dirichlet distribution: distribution over probability distribution
Additionally, added a new parameter, α, to represent the annotated feature labels. • Assumes that labeling word fk with class yj increases the probability of the word appearing in docs of that class
Also used Expectation-Maximization to exploit large set of unlabeled data • E step: estimate initial parameters and apply to unlabeled pool U • M step: re-estimate feature multinomials using both L and U • For speed, stopped training after one iteration of EM. EM algorithm lets us estimate parameters in models with incomplete data
Selecting instances to annotate: • entropy based: • Advantage: fast calculation • Selecting features to annotate: • IG information gain • Where I indicates presence/absence of a feature. Query selection Entropy: 0 <= H(X) <= log(N) The higher the entropy, the more uncertain we are about classification.
4 experiments • 2 offline to test algorithm • 2 live to test human interaction • Benchmark data: • Reuters: 9000 articles • WebKB: 4000+ web pages • 20 Newsgroups: 18,000+ usenetmsg • Movie Reviews: 2000 reviews • Data processed: lc, del punct, stop Experiments
MNB/Priors compared against: • MaxEnt/GE (a maximum entropy classifier/ general expectation MALLET toolkit) • MNB/Pool (naïve Bayes, pooling multinomials approach) • Limiting MNB methods to features • Results table 1 (next) • One iteration of EM for SS training improved the accuracy of MNB Algorithm comparison
Tuning α • Accuracy stable alpha < 100 so tuning not significant • Chose 50 for other experiments How sensitive the accuracty of MNB/Priors is to parameter α
5 annotators • Data 90% train, 10% test • Results: • Dual config better learning curve • Feature queries were less costly than instances • Active users made fewer mistakes • And faster User experiments Many studies use simulated oracles which don’t take into consideration actual human costs.
Word sense disambiguation – hard, line, serve; avg 80%, 10 minutes • Information extraction – classifying noun phrases: person, location, organization, date/time, other • Sentiment analysis – tested DUALIST framework on twitter messages, first classifying English/non, then classifying sentiment positive/negative/neutral with 65.9% accuracy Other applications
DUALIST is an active-learning annotation system that combines and complements the strengths of machine learner and human annotator • The dual-query interface is supported by an SSL learning algorithm that takes advantage of the additional labeling • Human annotation time: • 2 – 4 seconds for feature • 10 – 40 seconds for an instance • A feature may describe 1000s instances Summary
Machine Learning Dictionary: http://www.cse.unsw.edu.au/~billw/mldict.html • Naïve Bayes:http://nlp.stanford.edu/IR-book/html/htmledition/naive-bayes-text-classification-1.html • Dirichlet process: www.cs.cmu.edu/~kbe/dp_tutorial.pdfhttp://www.youtube.com/watch?v=nfBNOWv1pgE • MLE – maximum likelihood estimation:http://www.youtube.com/watch?v=aHwsEXCk4HA • Logistic Regressionwww.cs.cmu.edu/~tom/mlbook/NBayesLogReg.pdf • Expectation Maximalizationai.stanford.edu/~chuongdo/papers/em-tutorial.pdf • Information Gain:www.autonlab.org/tutorials/infogain11.pdf • Mallethttp://mallet.cs.umass.edu/ • Youtube presentation of 2012 iDash NLP Annotation Workshop: http://youtu.be/Et7h1A1j4ns Additional Resources
The data in the unlabeled pool U is weighted by a factor of 0.1. How is this weighting value decided? • How does the prior help when there are no labeled documents present in the initial stage? • Is DUALIST the only tool that anyone has developed in machine learning area? • If not, then how efficient is DUALIST compared to other tools for annotation the instances and features. Questions
1. How do they deal with words/features with are equally frequent in classes?For example, in a two-class classification: Basketball & Baseball. Let's assume that the learner have same number of examples of word 'score' related to each class. If we measure the entropy of this word, the result would be .50; so, will the learner request it for labeling?2. According to "We also saw surprising trends in annotation quality. In active settings, users made an average of one instance-labeling error per trial (relative to the gold standard labels), but in the passive case this rose to 1.6, suggesting they are more accurate on the activequeries.", annotating in active setting provokes less errors than in passive setting, but I don't understand how they could assure that. I know that authors are claiming this, but I only would like to know your opinion about it. More Questions