The IBM 2006 Spoken Term Detection System
The IBM 2006 Spoken Term Detection System Jonathan Mamou IBM Haifa Research Labs Olivier Siohan Bhuvana Ramabhadran IBM T. J. Watson Research Center Outline System description Indexing


The IBM 2006 Spoken Term Detection System
E N D
Presentation Transcript
The IBM 2006 Spoken Term Detection System Jonathan Mamou IBM Haifa Research Labs Olivier Siohan Bhuvana Ramabhadran IBM T. J. Watson Research Center
Outline • System description • Indexing • Audio processing for each source type: generation of CTM, word confusion networks (WCN) and phone transcripts • Index generation and storage • Search • Experiments/Results
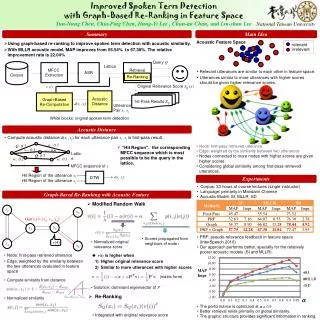
Term List System Overview term Phone Transcript Phone Index OOV Posting list extracting Merging INDEXER ASR Systems In Voc Scoring Deciding Word Transcript Word Index SEARCHER result OFFLINE INDEXING STD List
Conversational Telephone Speech Transcription System (CTS) D. Povey, B. Kingsbury, L. Mangu, G. Saon, H. Soltau, G. Zweig, "fMPE: Discriminatively Trained Features for Speech Recognition", in Proceedings International Conference on Acoustics Speech and Signal Processing, Philadelphia, PA, 2005.
Meeting Transcription System (confmtg) Huang, J. et al, “The IBM RT06S Speech-To-Text Evaluation System", NIST TR06S Workshop, May 3-4, 2006.
Phonetic Lattice Generation O. Siohan, M. Bacchiani, "Fast vocabulary independent audio search using path based graph indexing", Proceedings of Interspeech 2005, Lisbon, pp. 53-56. Two-step algorithm: • Generate sub-word lattices using word fragments as decoding units • Convert word-fragment lattices into phonetic lattices Required resources: • A word-fragment inventory • A word-fragment lexicon • A word-fragment language model Main Issue: designing a fragment inventory
Fragment based system design • Use a word-based system to convert the training material to phone strings • Train a phone n-gram with “large n” (say 5) • Prune the phone n-gram using entropy based pruning A. Stolcke, "Entropy-based pruning of backoff languge models", in Proceedings DARPA Broadcast News Transcription and Understanding Workshop, pp. 270-274, Lansdowne, VA, Feb. 1998. • Use the retained n-grams as the selected fragments (n-gram structure ensures coverage of all strings) • Phonetic pronunciations for word fragments are trivial • Train a fragment-based n-gram model for use in the fragment-based ASR system
Indexing Indices are stored using Juru storage • Juru is a full-text search library written in Java, developed at IBM • D. Carmel, E. Amitay, M. Herscovici, Y. S. Maarek, Y. Petruschka, and A. Soffer, "Juru at TREC 10 - Experiments with Index Pruning", Proceedings of TREC-10, NIST 2001. • We have adapted the Juru storage model in order to store speech related data (e.g. begin time, duration) • The posting lists are compressed using classical index compression techniques (d-gap) • Gerard Salton and Michael J. McGill, Introduction to modern information retrieval, 1983.
Indexing Algorithm Input: a corpus of word/sub-word transcripts Process: 1. Extract units of indexing from the transcript 2. For each unit of indexing (word or sub-word), store in the index its posting - transcript/speaker identifier (tid) - begin time (bt) - duration - For WCN - posterior probability - rank relative to the other hypotheses Output: an index on the corpus of transcripts
In-Vocabulary Search • Miss probability can be reduced by expanding the 1-best transcript with extra words, taken from the other alternatives provided by WCN transcript. • Such an expansion will probably reduce miss probability while increasing FA probability! • We need an appropriate scoring model in order to decrease the FA probability by punishing “bad” results J. Mamou, D. Carmel and R. Hoory, "Spoken Document Retrieval from Call-center conversations", Proceedings of SIGIR, 2006
Improving Retrieval Effectiveness for In Voc search Our scoring model is based on two pieces of information provided by WCN: • the posterior probability of the hypothesis given the signal: it reflects the confidence level of the ASR in the hypothesis. • the rank of the hypothesis among the other alternatives: it reflects the relative importance of the occurrence.
Improving Retrieval Effectiveness with OOV search • BN model: 39 OOV queries • CTS model: 117 OOV queries • CONFMTG model: 89 OOV queries • Since the accuracy of phone transcript is worse than the accuracy of the word transcript, we use phone transcript only for OOV keywords • It tends to reduce miss probability without affecting FA probability too much
Grapheme-to-phoneme conversion • OOV keywords are converted to phone sequence using a joint Maximum Entropy N-gram model • Given a letter sequence L, find the phone sequence P* that maximizes Pr(L,P) with • Details in • Stanley Chen, “Conditional and Joint Models for Grapheme-to-Phoneme Conversion”, in Proc. of Eurospeech 2003.
Search Algorithm Input: a query term, word based index , sub-word based index Process: 1. Extract the query keywords 2. For In-Voc query keywords, extract the posting lists from the word based index 3. For OOV query keywords, convert the keywords to sub-words and extract the posting list of each sub-word from the sub-word index 4. Merge the different posting lists according to the timestamp of the occurrences in order to create results matching the query - check that the words and sub-words appear in the right order according to their begin times - check that the words/sub-words are adjacent (less that 0.5 sec for word-word, word-phoneme and less than 0.2 sec for phoneme-phoneme) Output: the set of all the matches of the given term
Search Algorithm Extract Posting List from Word Index Word-Word, Word-Phone: < 0.5s Phone-Phone: < 0.2s In-Voc Extract Terms in the Query Merge based on begin time and adjacency Query Extract Posting List from Phone Index OOV Set of matches for all terms in the query
Scoring for hard-decision • We have boosted the score of multiple-words terms • Decision thresholds are set according to the analysis of the DET curve obtained on the development set. • We have used different threshold values per source type
Primary and Contrast system differences • Primary system (WCN): WCN for all the types, CONFMTG transcripts generated using the BN model. Combination with phonetic 1-best transcripts for BN and CTS. • Contrastive 1 (WCN-C): same as P except for the WCN of CONFMTG that was generated using the CONFMTG model • Contrastive 2 (CTM): CTM for all the types, CONFMTG transcripts generated using the BN model. Combination with phonetic 1-best transcripts for BN and CTS. • Contrastive 3 (1-best-WCN): 1-best path extracted from WCN, CONFMTG transcripts generated using the BN model. Combination with phonetic 1-best transcripts for BN and CTS.
Data Results • Retrieval performances are improved • using WCNs, relatively to 1-best path • using 1-best from WCN than CTM • Our ATWV is close to the MTWV; we have used appropriate thresholds for punishing bad results.
Condition performance duration character In general we performed better on long terms.
System characteristics (Eval) • Index size: 0.3267 MB/HP • Compression of the index storage • Indexing time: 7.5627 HP/HS • Search speed: 0.0041 sec.P/HS • Index Memory Usage: 1653.4297 MB • Search Memory Usage: 269.1250 MB
Conclusion • Our system combines a word retrieval approach with a phonetic retrieval approach • Our work exploits additional information provided by WCNs • Extending the 1-best transcript with all the hypotheses of the WCN, considering confidence levels and boostingby term rank. • ATWV is increased compared to the 1-best transcript • Miss probability is significantly improved by indexing all the hypotheses provided by the WCN. • Decision score are set to NO for “bad” results in order to attenuate the effect of FA added by WCN.