Download

1 / 0
0 likes | 433 Views
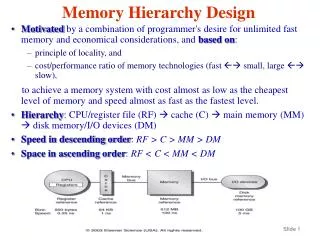
Advanced Computer Architecture Memory Hierarchy Design. Course 5MD00 Henk Corporaal November 2013 h.corporaal@tue.nl. Welcome!. This lecture: Memory Hierarchy Design Hierarchy Recap of Caching (App B) Many Cache and Memory Hierarchy Optimizations VM: virtual memory support

E N D