Parametric Query Generation
E N D
Presentation Transcript
Parametric Query Generation Student: Dilys Thomas Mentor: Nico Bruno Manager: Surajit Chaudhuri
Problem Statement Given Queries with Parametric filters, find values of Parameters so that cardinality constraints are satisfied on a given fixed database Constraints: Cardinality constraints on the query and its subexpressions. Parameters: Simple filters.
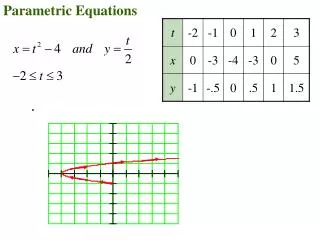
Example Select * from testR where ( testR.v1 between %f and %f) : 100,000 Select * from testS where ( testS.v1 <= %f): 17,000 Select * from testR, testS where (testR.v1=testS.v0) and ( testS.v1 <= %f) and ( testR.v0 >= %f) and ( testR.v1 between %f and %f): 30,000
Motivation Generation of queries to test the optimizer. RAGS tool is available presently to syntactically generate random queries and test for errors by a majority vote.
Motivation Needed to test different modules, new algorithms, test statistics estimator, and compare performances Queries not random but you want them to satisfy some constraints
Solution exists? NP complete. • For n parametric attributes with Joins • Database only has O(n) tuples Reduction from SUBSET SUM even for a single constraint.
Model For a given set of parameters can find the cardinality by a function invocation. Implemented by: • Actually running the query (slow, accurate) • Using optimizer estimates about the cardinality (fast, inaccurate) • Using an intermediate datastructure. Objective: Minimize the number of cardinality estimation calls
Understanding the Problem: Simplification • K single sided <= attribute parameters • Single relation and single constraint Let n=number of distinct values in each attribute. k= number of attributes Simple algorithm of time: Can we do better? 1 Dimension: Yes, Binary search.
2 Dimension Algorithm • Walk based Algorithm Search for 20
Lower Bound Incomparable set
For general k. Upper bound: For k-dimensions, recursively call n invocations of (k-1) dimension algorithm. T(k)=n * T(k-1) T(2)=n Hence T(K)= (Multiple walk algorithm) Lower bound: x_1 + x_2 + … x_k = n Solutions C(n+k-1,k-1)
Optimization Problem:Error Metrics. Single Constraint: Constraint cardinality: C , Achieved cardinality: D RelErr= max (C/D, D/C) Multiple Constraints: Combing the errors: Average relative error across all constraints. Objective: Minimize error
Simple Walk STEP= unit change in current parameter values While (can improve with step) {Make the improving step} Stepsize=1 tuple->converges to local optima Stepsize small -> convergence slow
Simple Walk-> Halving Walk • Initialize the parameters (point). Each stepsize=1.0 quantile • For (int i=0; i< maxhalve; i++) {while (can improve with step) {Make the improving step} //exited above loop -> cannot improve with local Halve all step sizes. } Use quantiles to decide steps.
Halving Walk • Initializing the parameters [More later] • Steps made in quantile domain of attribute done by simple equidepth wrapper over histograms provided by SQLServer Initial stepsize=1.0 quantile
Halving Walk: Steps considered For <=, >= parameters: RIGHT move ,LEFT move For between parameters: Apart from RIGHT move, LEFT move for each parameter. LEFT Translate. RIGHT Translate
Algorithm Halving-Steps A generalization of binary search // But only a heuristic. Converges to Local Optima #Steps per iteration : Constant. Hence much faster convergence.
Initialization • Random • Optimizer estimate • Solving equations: Power method. Least Square Error.
Least Squares Initialization For each parametric attribute, Pi , have variable pi For each Constraint build an equation: Cardinality without parametric filters: C Constraint cardinality with filters: F Then Filter selectivity= S = F/C If P1, P2, P3, Pk are parameters in this constraint Write equation: p1 * p2 * .. pk = S (Making Independence assumption)
Least Squares Initialization In log space: set of linear equations. May have single, multiple or no solutions! Use the solution that minimizes the least squares error metric. As in log-space this amounts to minimizing sum (L_2) of relative error. Simple and Fast Initialization.
Why still INIT step=1.0 quantile? Big Jumps in algorithm inspite of good start point: Optimizer estimates and independence assumptions may not be valid in the presence of correlated columns.
Efficiency: Statistics vs Execution • Optimizer used for cardinality estimation but Executor used to verify the final step taken. For a step when Optimizer (esimates decrease) and executor (evaluates increase) disagree switch to using only executor for cardinality estimation. • Good initialization obviates Optimizer use.
Shortcutting Traverse parameters in random order Make the first step that decreases the error (Compare to previous approach of trying all steps and making the “best” step that decreases error most) • No significant benefit. Shortcutting doesn’t seem to help. Infact sometimes slower convergence.
Experimental Results Dataset description: tables testR, testS, tesT, tableTA with upto 1M tuples. Have correlated columns and multiple correlated foreign key join columns. Columns include different Zipfian(1,0.5) and Gaussian distributions. Queries description: Queries join over correlated columns and have multiple correlated selectivities.
Query Description: Eg1: 6 Correlated parameters, 1 constraint. Single relation. Eg 2: 3 tables with 6 constraints including 2 way and 3 way join constraints. Filters on correlated columns across joins Other Queries with constraints over joins, many parameters over correlated attributes.
Problem Specifics: Reusing Results • Lots of queries with the same skeleton but different parameters. Creation of Indices will help! Use DTA for recommendations. 2-10 fold improvement in speed.
Interleaving OPT and Exec • Using Optimizer to guide search: gives 2-10 times improvement. Most of this improvement is also got by a good initialization procedure.
Prune Search • Look at only those steps that decrease the error • If present query has larger cardinality than constraint only make the filters less selective. • 30-40% improvement.
Initial Point • Random: Random may not converge to global optima Convergence much slower. • LSE/Power: Usually converge to global optima. Much faster convergence. Esp in 6 parameter query. Does not converge to global optima. Gets stuck up.
Multiple start points • Searches from start points do not give global optima • In practice a few start points gives the global optima
Problem Summary Create query for testing a module Query not random but must satisfy some constraints. Must satisfy Cardinality constraints given the freedom to select some parametric filters.
Algorithm: Summary • Theoretical walk based algorithm. • Halving search good in practice. • Use good initialization (optimizer, executor mix) pruning DTA indices. • Cost: That of 10-100 query executions, optimizer calls.