Download

1 / 16
160 likes | 275 Views
Generalized Sparsest Cut and Embeddings of Negative-Type Metrics. Shuchi Chawla, Anupam Gupta, Harald R ä cke Carnegie Mellon University 1/25/05. capacity of cut links demand across cut. Sparsity of a cut =. Finding Bottlenecks.

E N D
Generalized Sparsest Cut and Embeddings of Negative-Type Metrics Shuchi Chawla, Anupam Gupta, Harald Räcke Carnegie Mellon University 1/25/05
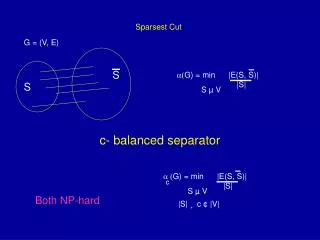
capacity of cut links demand across cut Sparsity of a cut = Finding Bottlenecks • Find the cut across which demand exceeds capacity by the largest factor Sparsest cut Capacity = 2.1 units Demand = 3 units 1 Sparsity of the cut = 0.7 10 0.1 Sparsest Cut and Embeddings of Negative-type Metrics
The Generalized Sparsest Cut Problem • The givens: a graph G=(V,E) capacities on edges c(e) demands on pairs of vertices D(x,y) • Sparsity of a cut S V, (S) = (S)c(e) xS, yS D(x,y) • Sparsity of graph G, (G) = minSV(S) • Our result: an O(log¾n)-approximation for (G) V S\V Sparsest Cut and Embeddings of Negative-type Metrics
What’s known • Uniform-demands – a special case D(x,y) = 1 for all x y • O(log n)-approx [Leighton Rao’88] based on LP-rounding • Cannot do better than O(log n) using the LP • O(log n)-approx [Arora Rao Vazirani’04] based on an SDP relaxation • General case • O(log n)-approx [Linial London Rabinovich’95 Aumann Rabani’98] based on LP-rounding and low-distortion embeddings • Our result: O(log¾n)-approx Extends [ARV04] using the same SDP Sparsest Cut and Embeddings of Negative-type Metrics
(d) = ec(e) d(e) x,y D(x,y) d(x,y) A metrics perspective • Given set S, define a “cut” metric S(x,y) = 1 if x and y on different sides of cut (S, V-S) 0 otherwise • (S) = ec(e) S(e) x,y D(x,y) S(x,y) • Finding sparsest cut minimizing above function over all metrics • Typical technique: Minimize over class ℳ of metrics, with ℳ ℓ1, and embed into ℓ1 NP-hard ℓ1 cut Sparsest Cut and Embeddings of Negative-type Metrics
(d) = ec(e) d(e) x,y D(x,y) d(x,y) A metrics perspective • Finding sparsest cut minimizing a(d) over metrics • Lemma: Minimize over a class ℳ to obtain d + have -distortion embedding from d into -approx for sparsest cut ℓ1 ℓ1 • When ℳ = all metrics, obtain O(log n) approximation • [Linial London Rabinovich ’95, Aumann Rabani ’98] • Cannot do any better [Leighton Rao ’88] Sparsest Cut and Embeddings of Negative-type Metrics
(d) = ec(e) d(e) x,y D(x,y) d(x,y) Squared-Euclidean, or ℓ2-metrics 2 A metrics perspective • Finding sparsest cut minimizing a(d) over metrics • Lemma: Minimize over a class ℳ to obtain d + have -avg-distortion embedding from d into -approx for “uniform-demands” sparsest cut ℓ1 ℓ1 • ℳ = “negative-type” metrics O(log n) approx • [Arora Rao Vazirani ’04] • Question: Can we obtain O(log n) for generalized • sparsest cut, • or an O(log n) distortion embedding from into ℓ2 ℓ1 2 Sparsest Cut and Embeddings of Negative-type Metrics
ℓ2 2 ℓ2 2 Arora et al.’s O(log n)-approx • Solve an SDP relaxation to get the best representation • Key Theorem: Let d be a “well-spread-out” metric. Then m – an embedding from d into a line, such that, - for all pairs (x,y), m(x,y) d(x,y) - for a constant fraction of (x,y), m(x,y) 1 ⁄O(log n) d(x,y) • The general case – issues • Well-spreading does not hold • Constant fraction is not enough Want low distortion for every demand pair. For a const. fraction of (x,y), d(x,y) > const. diameter Implies an avg. distortion of O(log n) Sparsest Cut and Embeddings of Negative-type Metrics
1. Ensuring well-spreading • Divide pairs into groups based on distances Di = { (x,y) : 2i d(x,y) 2i+1 } • At most O(log n) groups • Each group by itself is well-spread, by definition • Embed each group individually • distortion O(log n) contracting embedding into a line for each (assume for now) • “Glue” the embeddings appropriately Sparsest Cut and Embeddings of Negative-type Metrics
Gluing the groups • Start with an a = O(log n) embedding for each scale • A naïve gluing • concatenate all the embeddings and renormalize by dividing by O(log n) • Distortion O(alog n) = O(log n) • A better gluing lemma • “measured-descent” by Krauthgamer, Lee, Mendel & Naor (2004) (Recall the previous talk by James Lee) • Gives distortion O(a log n) distortion O(log¾n) Sparsest Cut and Embeddings of Negative-type Metrics
2. Average to worst-case distortion • Arora et al.’s guarantee – a constant fraction of pairs embed with low distortion • We want – every pair should embed with low distortion • Idea: Re-embed pairs that have high distortion • Problem: Increases the number of embeddings, implying a larger distortion • A “re-weighting” solution: • Don’t ignore low-distortion pairs completely – keep them around and reduce their importance Sparsest Cut and Embeddings of Negative-type Metrics
Weighting-and-watching • Initialize weight = 1 for each pair • Apply ARV to weighted instance • For pairs with low-distortion, decrease weights by factor of 2 • For other pairs, do nothing • Repeat until total weight < 1/k • Total weight decreases by constant factor every time • O(log k) iterations • Each individual weight decreases from 1 to 1/k • Each pair contributes to W(log k) iterations • Implies low distortion for every pair A constant fraction of the weight is embed with low distortion Sparsest Cut and Embeddings of Negative-type Metrics
Summarizing… • Start with a solution to the SDP • For every distance scale • Use [ARV04] to embed points into line • Use re-weighting to obtain good worst-case distortion • Combine distance scales using measured-descent • In practice • Write another SDP to find best embedding into • Use J-L to embed into and then into a cut-metric ℓ2 ℓ2 ℓ1 Sparsest Cut and Embeddings of Negative-type Metrics
ℓ2 2 Recent developements • Arora, Lee & Naor obtained an O(log n log log n) approximation for sparsest cut • The improvement lies in a better concatenation technique • Nearly optimal embedding from into • Evidence for hardness • Khot & Vishnoi:W(log log log n) integrality gap for the SDP l.b. for embedding into • Chawla, Krauthgamer, Kumar, Rabani & Sivakumar: W(log log n) hardness based on “Unique Games Conjecture” • Evidence that constant factor approximation is not possible • Other approximations using similar SDP relaxations • Feige, Hajiaghayi & Lee: O(log n) approx for min-wt. vertex cuts ℓ1 ℓ2 ℓ1 Sparsest Cut and Embeddings of Negative-type Metrics
Open Problems • Beating the [ALN05] O(log n log log n)approximation • Can the SDP give a better bound? • Exploring flow-based techniques • Closing the gap between hardness and approximation • Other applications of SDP with triangle inequalities • Other partitioning problems • Directed versions? SDP/LP don’t seem to work Sparsest Cut and Embeddings of Negative-type Metrics