Download

1 / 25
250 likes | 279 Views
Explore conventional inverted index operations and extensions for effective text retrieval. Learn about term weights, synonym specifications, stemming, and term truncation methods. Discover how to optimize document retrieval with Boolean query transformations. Dive into the world of text processing and database management.

E N D
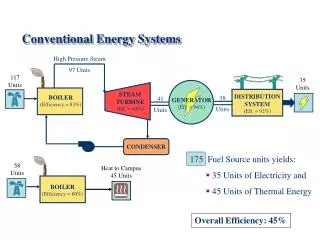
Conventional Text-Retrieval Systems Automatic Text Processing by G. Salton, Addison-Wesley, 1989. (Chapter 9)
Database Management • A specified set of attributes is used to characterize each record.EMPLOYEE(NAME, SSN, BDATE, ADDR, SEX, SALARY, DNO) • Exact match between the attributes used inquery formulationsandthose attached to the document. SELECT BDATE, ADDR FROM EMPLOYEE WHERE NAME = ‘John Smith’
Text-Retrieval Systems • Content identifiers (keywords, index terms, descriptors) characterize the stored texts. • Degrees of coincidence between the sets of identifiers attached to queries and documents content analysis query formulation
Possible Representation • Document representation • unweighted index terms (term vectors) • weighted index terms • … • Query • unweighted or weighted index terms • Boolean combinations (or, and, not) • … • Search operation must be effective
File Structures • Main requirements • fast-access for various kinds of searches • large number of indices • Alternatives • Inverted Files • Signature Files • PAT trees
Inverted Files • File is represented as an array of indexed documents.
Inverted-file process • The document-term array is inverted (transposed).
Inverted-file process (Continued) • Take two or more rows of an inverted term-document array, and produce a single combined list of document identifiers. • Ex: Query= (term2 and term3) term21 1 0 0term3 0 1 1 1------------------------------------------------------ 1 <-- D2
List-merging for two ordered lists • The inverted-index operations to obtain answers are based on list-merging process. • ExampleT1: {D1, D3}T2: {D1, D2}Merged(T1, T2): {D1, D1, D2, D3}
Extensions of Inverted Index Operations(Distance Constraints) • Distance Constraints • (A within sentence B)terms A and B must co-occur in a common sentence • (A adjacent B)terms A and B must occur adjacently in the text
Extensions of Inverted Index Operations(Distance Constraints) • Implementation • include term-location in the inverted indexesinformation: {P345, P348, P350, …}retrieval: {P123, P128, P345, …} • include sentence-location in the indexes information: {P345, 25; P345, 37; P348, 10; P350, 8; …}retrieval: {P123, 5; P128, 25; P345, 37; P345, 40; …}
Extensions of Inverted Index Operations(Distance Constraints) • Include paragraph numbers in the indexessentence numbers within paragraphsword numbers within sentencesinformation: {P345, 2, 3, 5; …}retrieval: {P345, 2, 3, 6; …} • Query examples(information adjacent retrieval)(information within five words retrieval) • Cost: the size of indexes
Term Weights • Term WeightsDi={Ti1, 0.2; Ti2, 0.5; Ti3, 0.6} • Issues • how to generate the term weights • how to apply the term weights • Sum the weights of all document terms that match the given query. • Rank the output documents in the descending order of term weight.
Boolean Query with Term Weights • Transform a Boolean expression into disjunctive normal form.T1 and (T2 or T3) = (T1 and T2) or (T1 and T3) • For each conjunct, compute the minimum term weight of any document term in that conjunct. • The document weight is the maximum of all the conjunct weights.
Boolean Query with Term Weights • Example: Q=(T1 and T2) or T3Document Conjunct QueryVectors Weights Weight(T1 and T2) (T3) (T1 and T2) or T3D1=(T1,0.2;T2,0.5;T3,0.6)0.2 0.6 0.6D2=(T1,0.7;T2,0.2;T3,0.1)0.2 0.1 0.2D1 is preferred.
Synonym Specification • Original Query(T1 and T2) or T3Assume S1 is a synonym of T1.Assume S3 is a synonym of T3. • Broader Query((T1 or S1) and T2) or (T3 or S3) • The number of relevant items retrieved may be larger.
Stemming • Term Truncation • Remove suffixes and/or prefixes from context terms. • ExamplePSYCH*: psychiatrist, psychiatry, psychiatric,psychology, psychological, …
Term Truncation • Implementation • Only suffix truncationConventional inverted-index methodology can be maintained unchanged. • Only prefix truncationThe term entries in inverted index are inversely alphabetized.antisymmetry --> yrtemmysitna
Term Truncation • Both prefix and suffix truncation*SYMM*:antisymmetric,asymmetryinverted-index entries that are alphabetized both forward and backward • infix truncationwom*nwomanwomeninverted index with entries for all possible “rotated” word forms
Term Truncation • Each term entry X=x1, x2, …, xn with individual characters xi is augmented by adding a special terminal character /.ABC ABC/BABC BABC/BCAB BCAB/ • Each augmented term x1, x2, …, xn/ is rotated cyclically by wrapping the term around itself n+1 times.ABC/ / ABC,C/ AB,BC/ A,ABC/
Term Truncation • Each resulting word form is then augmented by appending a blank character ^. • The resulting file of word forms is sorted alphabetically. ^, /, a, b, c, …, Zlow high
ABC ABC/ /ABC^ /ABC^ C/AB^ /BABC^ BC/A^ /BCAB^ ABC/^ AB/BC^ BABC BABC/ /BABC^ ABC/^ C/BAB^ ABC/B^ BC/BA^ B/BCA^ ABC/B^ BABC/^ BABC/^ BC/A^ BCAB BCAB/ /BCAB^ BC/BA^ B/BCA^ BCAB/^ AB/BC^ C/AB^ CAB/B^ C/BAB^ BCAB/^ CAB/B^
Retrieval Strategies • Query term XLook for index entries /X^orX/^. • Query term X*Look for /X*. • Query term *XLook for X/^ => X/Y1, …, X/Yn.original patterns: X, Y1X, …, YnX • Query term *X*Look for XY1/Z1, …, XYn/Zn.original patterns: Z1XY1, …, ZnXYn
ABC ABC/ /ABC^ /ABC^ *B* C/AB^ /BABC^ BC/A^ /BCAB^ ABC/^ AB/BC^ BABC BABC/ /BABC^ ABC/^ C/BAB^ ABC/B^ BC/BA^ B/BCA^ BCAB ABC/B^ BABC/^ BABC BABC/^ BC/A^ ABC BCAB BCAB/ /BCAB^ BC/BA^ BABC B/BCA^ BCAB/^ BCAB AB/BC^ C/AB^ CAB/B^ C/BAB^ BCAB/^ CAB/B^
Retrieval Strategies • Query term X*YLook for Y/XZ1, …, Y/XZm.Original patterns:XZ1Y, …, XZmY • CostIncrease index entries.