Reducing Reorder Buffer Complexity Through Selective Operand Caching
Reducing Reorder Buffer Complexity Through Selective Operand Caching. Gurhan Kucuk, Dmitry Ponomarev, Oguz Ergin, Kanad Ghose Department of Computer Science State University of New York Binghamton, NY 13902-6000 http://www.cs.binghamton.edu/~lowpower.


Reducing Reorder Buffer Complexity Through Selective Operand Caching
E N D
Presentation Transcript
Reducing Reorder Buffer Complexity Through Selective Operand Caching Gurhan Kucuk, Dmitry Ponomarev, Oguz Ergin, Kanad Ghose Department of Computer Science State University of New York Binghamton, NY 13902-6000 http://www.cs.binghamton.edu/~lowpower International Symposium on Low Power Electronics and Design (ISLPED’03), August 26th 2003 *supported in part by DARPA through the PAC-C program and NSF ISLPED’03
Outline • Reorder Buffer (ROB) complexities • Motivation for the low-complexity ROB • Low-complexity ROB (ICS’02) • Improving the design using short-lived values • Results • Concluding remarks ISLPED’03
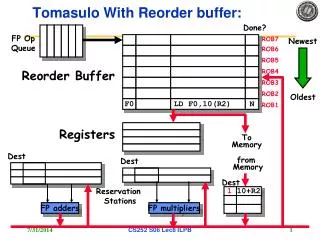
P6 Style Superscalar Datapath Function Units Architectural Register File Instruction Issue IQ FU1 F1 F2 D1 D2 FU2 ROB ARF FUm Fetch Decode/Dispatch LSQ EX Instruction dispatch D-cache Result/status forwarding buses ISLPED’03
ROB Port Requirements for a W-way CPU Decode/Dispatch W write ports to setup entries Writeback W write ports to write results ROB Dispatch/Issue 2W read ports to read the source operands Commit W read ports for instruction commitment ISLPED’03
Where are the Source Values Coming From? Function Units Architectural Register File Instruction Issue 1 2 IQ FU1 F1 F2 D1 D2 FU2 ROB ARF FUm Fetch Decode/Dispatch LSQ EX 3 Instruction dispatch D-cache Result/status forwarding buses ISLPED’03
Where are the Source Values Coming From ? 62% 32% 6% 96-entry ROB, 4-way processor SPEC2K Benchmarks ISLPED’03
How Efficiently are the Ports Used ? Decode/Dispatch W write ports to setup entries Writeback W write ports To write results ROB Dispatch/Issue 2W read ports to read the source operands Commit W read ports for instruction commitment 6% ISLPED’03
Our Solution: Elimination of Read Ports Function Units Architectural Register File Instruction Issue 1 2 IQ FU1 F1 F2 D1 D2 FU2 ROB ARF FUm Fetch Decode/Dispatch LSQ EX 3 Instruction dispatch D-cache Result/status forwarding buses ISLPED’03
Our Solution: Elimination of Read Ports Function Units Architectural Register File Instruction Issue 1 2 IQ FU1 F1 F2 D1 D2 FU2 ROB ARF FUm Fetch Decode/Dispatch LSQ EX 3 Instruction dispatch D-cache Result/status forwarding buses ISLPED’03
Our Solution: Elimination of Read Ports Function Units Architectural Register File Instruction Issue 1 IQ FU1 F1 F2 D1 D2 FU2 ROB ARF FUm Fetch Decode/Dispatch LSQ EX 3 Instruction dispatch D-cache Result/status forwarding buses ISLPED’03
Comparison of ROB Bitcells (0.18µ, TSMC) Layout of a 32-ported SRAM bitcell Layout of a 16-ported SRAM bitcell Area Reduction – 71% Shorter bit and wordlines ISLPED’03
Completely Eliminating the Source Read Ports on the ROB • The Problem: Issue of instructions that require a value stored in the ROB will stall • Solutions: • Forward the value to the waiting instruction at the time of committing the value: LATE FORWARDING ISLPED’03
Late Forwarding: Use the Normal Forwarding Buses! Function Units Architectural Register File Instruction Issue IQ FU1 F1 F2 D1 D2 FU2 ROB ARF FUm Fetch Decode/Dispatch LSQ EX Instruction dispatch D-cache Result/status forwarding buses: ISLPED’03
Late Forwarding: Use the Normal Forwarding Buses! Function Units Architectural Register File Instruction Issue IQ FU1 F1 F2 D1 D2 FU2 ROB ARF FUm Fetch Decode/Dispatch LSQ EX Instruction dispatch D-cache Result/status forwarding buses: ISLPED’03
Improving Performance • Cache recently generated values in a set ofRETENTION LATCHES (RL) • Retention Latches areSMALLandFAST • Only 8 to 16 latches needed in the set • Entire set has 1 or 2 read ports ISLPED’03
Datapath with the Retention Latches Function Units Architectural Register File Instruction Issue IQ FU1 F1 F2 D1 D2 FU2 ROB ARF FUm Fetch Decode/Dispatch LSQ EX Instruction dispatch D-cache Result/status forwarding buses ISLPED’03
Datapath with the Retention Latches RETENTION LATCHES Function Units Architectural Register File Instruction Issue IQ FU1 F1 F2 D1 D2 FU2 ROB ARF FUm Fetch Decode/Dispatch LSQ EX Instruction dispatch D-cache Result/status forwarding buses ISLPED’03
Retention Latch Management Strategies • FIFO • 8 entry RL: 42% hit rate • 16 entry RL: 55% hit rate • LRU • 8 entry RL: 56% hit rate • 16 entry RL: 62% hit rate • Random Replacement • Worse performance than FIFO ISLPED’03
Advantages of Using Retention Latches • Reduces energy dissipation in the ROB – avoids creating a localized hot spot • Reduces associated performance losses • Reduces ROB complexity – smaller floor plan, easier validation ISLPED’03
Improving Retention Latch Management • PROBLEM: All generated results, irrespective of whether they could be potentially read from the RLs, are written into the latches unconditionally • CONSEQUENCE: The array of RLs is not utilized efficiently and performance loss is still noticeable • SOLUTION: We identify the values which are never going to be read after the cycle of their generation and avoid writing of these values into the RLs ISLPED’03
Short-Lived Values • Our definition: a value is short-lived if the destination register is renamed by the time of the result generation • Identified one cycle before the result writeback LOAD R1, R2, 100 SUB R5, R1, R3 ADD R1, R5, R4 LOAD P31, R2, 100 SUB P32, P31, R3 ADD P33, P32, R4 RENAMER ISLPED’03
Key Idea: Do not cache short-lived values • AVOID WRITING SHORT-LIVED VALUES INTO THE RETENTION LATCHES • Reasons: • Short-lived values are forwarded directly to all potential consumers in the issue queue • No instruction will ever consume a short-lived value from the retention latches • Results: • Increased RL hit ratios and better overall performance ISLPED’03
The Good News : 80%+ of the Values are Short-Lived % 96-entry ROB, 4-way processor ISLPED’03
Renamed 1 31 Identifying Short-Lived Values • Maintain the bit-vector Renamed • Set by the Renamer at the time of renaming LOAD R1, R2, 100 SUB R5, R1, R3 ADD R1, R5, R4 LOAD P31, R2, 100 SUB P32, P31, R3 ADD P33, P32, R4 ISLPED’03
Identifying Short-Lived Values • Maintain the bit-vector Renamed • Set by the Renamer at the time of renaming LOAD R1, R2, 100 SUB R5, R1, R3 ADD R1, R5, R4 LOAD P31, R2, 100 SUB P32, P31, R3 ADD P33, P32, R4 Renamed 1 31 ISLPED’03
Identifying Short-Lived Values • Renamed bit is checked one cycle before writeback • Value produced by LOAD is short-lived because Renamed [31]=1 LOAD P31, R2, 100 SUB P32, P31, R3 ADD P33, P32, R4 LOAD R1, R2, 100 SUB R5, R1, R3 ADD R1, R5, R4 Renamed 1 31 ISLPED’03
Hit Ratios to Retention Latches 46% 73% Average Hit Ratio: Hit Ratios bzip2 gap gcc gzip mcf parser perl twolf vortex vpr Int Avg. applu apsi art equake mesa mgrid swim wupwise FP Avg. ISLPED’03
Experimental Results: Effect on Performance Avg. IPC Drop: 1.7% 0.5% 1.1% 1.7% IPC bzip2 gap gcc gzip mcf parser perl twolf vortex vpr Int Avg. applu apsi art equake mesa mgrid swim wupwise FP Avg. ISLPED’03
Experimental Results: Effect on ROB Power Avg. Savings: 13.7% 15.0% 15.9% Energy (pJ) bzip2 gap gcc gzip mcf parser perl twolf vortex vpr Int Avg. applu apsi art equake mesa mgrid swim wupwise FP Avg. ISLPED’03
Conclusions • We proposed a mechanism to further improve the performance and reduce the complexity of a processor that uses retention latches and eliminates the ROB source read ports • The idea is to avoid caching the short-lived result values in the retention latches • Both retention latch hit ratio and the overall performance improved • Alternatively, fewer retention latches can be used with the same performance ISLPED’03
THANK YOU ! LOW POWER RESEARCH GROUP Department of Computer Science State University of New York Binghamton, NY 13902-6000 http://www.cs.binghamton.edu/~lowpower International Symposium on Low Power Electronics and Design (ISLPED’03), August 27th 2003 *supported in part by DARPA through the PAC-C program and NSF ISLPED’03