Download
1 / 5
50 likes | 76 Views
Conducting experiments on Faust dataset using innovative methods to improve accuracy and efficiency in classification tasks. Results show promising performance gains in cutting-edge techniques.

E N D
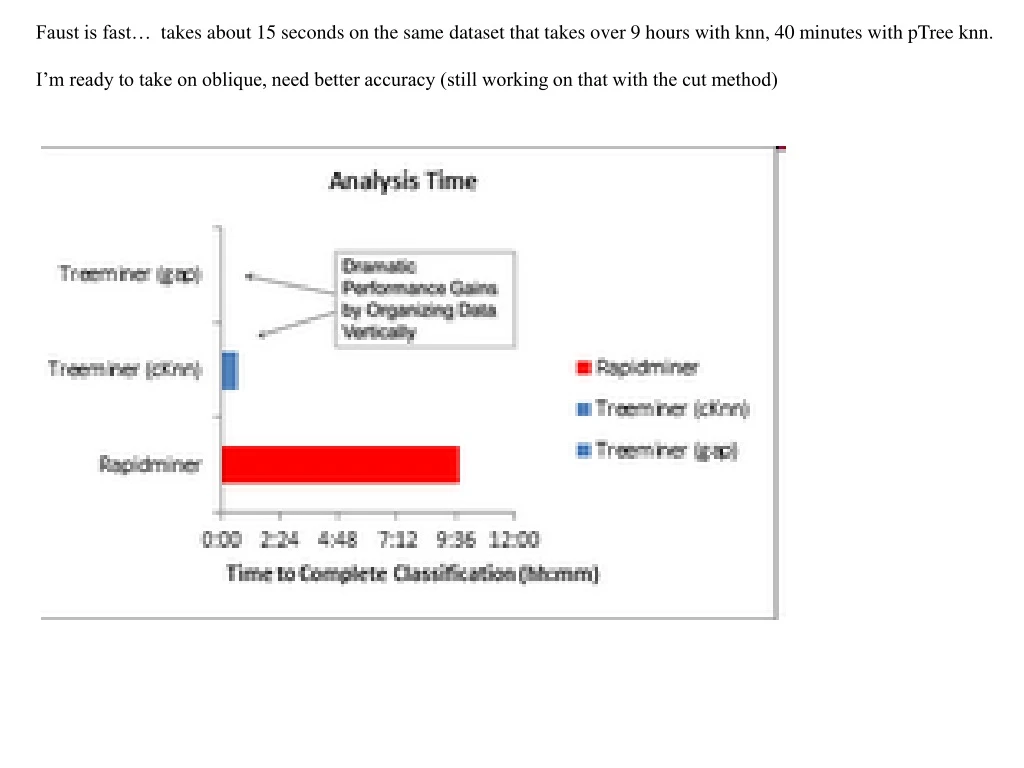
Faust is fast… takes about 15 seconds on the same dataset that takes over 9 hours with knn, 40 minutes with pTree knn. I’m ready to take on oblique, need better accuracy (still working on that with the cut method)
Some data. I started doing some experiments on faust to assess cutting off classification when gaps got too small (with an eye towards using knn or something from there). Results are pretty darn good if you ask me… and for faust this is still single gap, working on total gap (maximum of (minimum of prev and next gaps)) Here’s also a new data sheet I’ve been working on focused on gov’t clients -Mark
R G ir1 ir2 std 8 15 13 9 1 8 13 13 19 2 5 7 7 6 3 6 8 8 7 4 6 12 13 13 5 5 8 9 7 7 R G ir1 ir2 mn 62.83 95.29 108.12 89.50 1 48.84 39.91 113.89 118.31 2 87.48 105.50 110.60 87.46 3 77.41 90.94 95.61 75.35 4 59.59 62.27 83.02 69.95 5 69.01 77.42 81.59 64.13 7 FAUST Satlog evaluation 1 2 3 4 5 7 tot 461 224 397 211 237 470 2000 TP actual 99 193 325 130 151 257 1155 TP nonOb L0 pure1 212 183 314 103 157 330 1037 TP nonOblique 14 1 42 103 36 189 385 FP level-1 50% 322 199 344 145 174 353 1537 TP Obl level-0 28 3 80 171 107 74 463 FP MeansMidPoint 359 205 332 144 175 324 1539 TP Obl level-0 29 18 47 156 131 58 439 FP s1/(s1+s2) 410 212 277 179 199 324 1601 TP 2s1/(2s1+s2) 114 40 113 259 235 58 819 FP Ob L0 no elim 309 212 277 154 163 248 1363 TP 2s1/(2s1+s2) 22 40 65 211 196 27 561 FP Ob L0 234571 329 189 277 154 164 307 1420 TP 2s1/(2s1+s2) 25 1 113 211 121 33 504 FP Ob L0 347512 355 189 277 154 164 307 1446 TP 2s1/(2s1+s2) 37 18 14 259 121 33 482 FPOb L0425713 2 33 56 58 6 18 173 TP BandClass rule 0 0 24 46 0 193 263 FP mining (below) red green ir1 ir2 abv below abv below abv below abv below avg 1 4.33 2.10 5.29 2.16 1.68 8.09 13.11 0.94 4.71 2 1.30 1.12 6.07 0.94 2.36 3 1.09 2.16 8.09 6.07 1.07 13.11 5.27 4 1.31 1.09 1.18 5.29 1.67 1.68 3.70 1.07 2.12 5 1.30 4.33 1.12 1.32 15.37 1.67 3.43 3.70 4.03 7 2.10 1.31 1.32 1.18 15.37 3.43 4.12 pmr*pstdv + pmv*2pstdr 2pstdr a = pmr + (pmv-pmr) = pstdr +2pstdv pstdv+2pstdr G[0,46]2 G[47,64]5 G[65,81]7 G[81,94]4 G[94,255]{1,3} R[0,48]{1,2} R[49,62]{1,5} above=(std+stdup)/gap below=(std+stddn)/gapdn suggest ord 425713 cls avg 4 2.12 2 2.36 5 4.03 7 4.12 1 4.71 3 5.27 R[82,255]3 ir1[0,88]{5,7} ir2[0,52]5 NonOblique lev-0 1's 2's 3's 4's 5's 7's True Positives: 99 193 325 130 151 257 Class actual-> 461 224 397 211 237 470 2s1, # of FPs reduced and TPs somewhat reduced. Better? Parameterize the 2 to max TPs, min FPs. Best parameter? NonOblq lev1 gt50 1's 2's 3's 4's 5's 7's True Positives: 212 183 314 103 157 330 False Positives: 14 1 42 103 36 189 Oblique level-0 using midpoint of means 1's 2's 3's 4's 5's 7's True Positives: 322 199 344 145 174 353 False Positives: 28 3 80 171 107 74 Oblique level-0 using means and stds of projections (w/o cls elim) 1's 2's 3's 4's 5's 7's True Positives: 359 205 332 144 175 324 False Positives: 29 18 47 156 131 58 Oblique lev-0, means, stds of projections (w cls elim in 2345671 order)Note that none occurs 1's 2's 3's 4's 5's 7's True Positives: 359 205 332 144 175 324 False Positives: 29 18 47 156 131 58 Oblique level-0 using means and stds of projections, doubling pstd No elimination! 1's 2's 3's 4's 5's 7's True Positives: 410 212 277 179 199 324 False Positives: 114 40 113 259 235 58 Oblique lev-0, means, stds of projs,doubling pstdr, classify, eliminate in 2,3,4,5,7,1 ord 1's 2's 3's 4's 5's 7's True Positives: 309 212 277 154 163 248 False Positives: 22 40 65 211 196 27 Oblique lev-0, means,stds of projs,doubling pstdr, classify, elim 3,4,7,5,1,2 ord 1's 2's 3's 4's 5's 7's True Positives: 329 189 277 154 164 307 False Positives: 25 1 113 211 121 33 2s1/(2s1+s2) elim ord: 425713 TP: 355 205 224 179 172 307 FP: 37 18 14 259 121 33 Conclusion? MeansMidPoint and Oblique std1/(std1+std2) are best with the Oblique version slightly better. I wonder how these two methods would work on Netflix? Two ways: UTbl(User, M1,...,M17,770) (u,m); umTrainingTbl = SubUTbl(Support(m), Support(u), m) MTbl(Movie, U1,...,U480189) (m,u); muTrainingTbl = SubMTbl(Support(u), Support(m), u)
Mark Silverman silverson4@gmail.com] Feb 29: speed-wise, knn on oakes (using 50% as training set and classifying the other 50%) using rapidminer over 9 hrs, vertical knn 40 min (resisting attempts to optimize). curious to see FAUST. accuracy is pretty similar (for the knns) very excited about MYRRH and classification problems - seems hugely innovative... know who would be interested in twitter bloom analysis.. tweaking Greg's faust impl to generalize it and look at gap split (currently looks for the max gap, not max gap on both side of mean -should be?) WP: looks like 50%ones impure pTrees can give cut-hyperplanes (for FAUST) as good as raw pTrees. what's the advantage? Since FAUST training is a 1-time process, it isn't speed critical. Very fast impure pTree batch classification (after training) would be very exciting. Once the cut-hyper-planes identified (e.g., FPGA spits out 50%ones impure pTrees for incoming unclassified datasets (e.g., satellite images) and sends them thro (FPGA) for "Md's "One-Pass-Across-Columns = OPAC" batch classification - all happening on-the-fly with nearly zero delay... For PINE (nearest neighbor), we don't even train a model, so the 50%ones impure pTree classification-phase could be very significantly better. Business Intelligence= "What does this customer want next, based on histories?": FAUST is model-based (training phase=build model of 1 hyperplane for Oblique or up to 1-per-col for non-Oblique). Use the model to classify. In Bus-Intel, with every new unclassified sample, a different vector space appears. (every customer rates a different set of items). So to use FAUST-PINE, there's the non-vector-space problem to solve. non-Oblique FAUST better than Oblique, since cols have different cardinalities (not a vector space to calculate oblique hyperplanes). In general, we're attempting is to marry MYRRH multi-hop Relationship or Rule Mining with FAUST-PINE Classification or Table Mining. On Social Network Mining: We have some social network mining research threads percolating: 1. facebook-friends multi-hopped with buying-preference relationships (or multi-hopped with security threat relationships or with?) 2. implications of twitter blooms for event prediction (e.g., commod/stock changes, events, political trends, bubbles/bursts, purchasing patterns ... I would like to tie image classification with social networks somehow too ;-) WP: 3/1/12 Note on "...very excited about the discussions on MYRRH and applying it to classification problems, seems hugely innovative..." I want to try to view Images as relationships, rather than as tables, each row = a pixel and each cols is "the photon count in a frequency band". Any table=relationship (AKA, a matrix, rolodex card) w 2 entity axes: 1. usual row entity (e.g., pixels), 2. col entity(s) (e.g., wavlen interval). Any matrix is a dual pair of tables (via rotation). Cust-Item Rating matrix is rating tbl pair: Custs(Items) and its rotated dual, Item(Custs). When sufficient #of fine-band, hyper-spectral sensors in the air (plus on/in the ground), there will be a sufficient # of separate columns to do MYRRH on the relationship between pixels and wavelengths multi-hopped with the relationship between classes and pixels (...nearly every measurement is a summarization or a intervalization (even a pixel is a 2-D intervalization of an infinite set of points in space), so viewing wavelength as an intervalization of a continuous phenomenon is just as valid, right?). What if we do FAUST-PINE on the rotated image relationship, Wavelength(pixel_photon_count) instead of, Pixel(Wavelength_photon_count)? Note that classes which are not convex in Pix(WL) (that are spread out spatially all over the image) might be convex in WL(Pix)? tried prelims - disappointing for classification (tried applying concept on SatLogLandsat(R,G,ir1,ir2,class). too few bands or classes? Still, I'm hoping for "Wow! Look at this!" when, e.g., classes aren't known/clear and there are thousands of them and millions of bands...) e.g., 2 huge square-ish relationships to multi-hop. difficult (curse of dim = too many cols which are the relevant?) rule mining comes into its own. One last thought: regarding " the curse of dimensionality = too many columns - which are the relevant ones? ", FAUST automatically filters irrelevant cols to find those that reveal [convex] classes (all good classes are convex in proper feature space. e.g., Class=yellow_car may round-ish in Pix(RedWaveLen,GreenWaveLen, BlueWaveLen, OtherWaveLens), once R,G,B are isolated as relevant ones. Class=pavement is fragmented in Pix(RWL,GWL,BWL,OWLs) but may be convex in WL(pix_x, pix_y) (because pavement is color consistent?) Last point: We have to get you a FAUST implementation! It almost has to be orders of magnitude faster than pknn! The speedup should be very sublinear - almost constant (nearly independent of cardinality) - because it is a bulk classifier (one horizontal pass gains us a class_mask_pTree, distinguishing all points predicted to be in that class). So, not only is it model-based, but it is a batch classifier. Model-based classifiers that require scanning horizontal datasets cannot compete! Mark wrote 3/2/12:Very close on faust. I have it now fully integrated into my "platform" - I can split the training and classification into two steps easily, but i'll assess that again after i run some larger datasets through. A question I have though is what happens at the end if you've peeled off all the classes and there are still some unclassified points left? Some potential interest from some folks I know who have a very close relationship with Arbitron. Seems like a netflix story to me... up to us to talk about what we may be able to do. WP 3/2/12: it's paramount that the classification step be done in bulk lest you lose the main huge benefit of FAUST (i.e., Once you trainfor a set of classes (i.e., once you have constructed cut-hyperplanes for each image class, e.g., red cars or high_yield…) then for each incoming SET of new unclassified sample points (e.g., each new image as a whole set of points to be classified) it is just one AND/OR program across the PTreeSET to produce a mask pTree indicating ALL the points in a class (as the 1-bits in the mask - all non-class points are the 0-bits). Then Greg’s converter routine can turn this class mask pTree into a list to be displayed (throw mask pTrees directly to screen vertically vertical Right now your probably using the “std-ratio-based best gap at a time FAUST? There are at least two ways to do that. One is to use the DIANA classifier approach (think of the entire training set as one cluster; divide it in two clusters at the “best gap” then recursively divide each cluster at the best of its gaps… You end up with each class fully differentiated by two inequality (half-open interval) pTrees. faster? other way:peel off one class at a time by recursively looking for the best pair of consec gaps. Result is same. DIANA faster-fewer AND/ORs? Either is a good 1st implementation (reap the main huge speed benefit of bulk classification). Later other can be compared for speed diff. even later Oblique FAUST (Md’s) can be impl for speedup? But any should demonstrate huge speed over knns or anything 1 class at a time. A question I have though is what happens at the end if you've peeled off all the classes and there are still some unclassified points left? have “mixed” or “default” (e.g., SatLog class=6=“mixed”) potential interest from some folks who have close relationship with Arbitron. Seems like a netflix story to me... up to us to say what we can do.