Download

1 / 8
110 likes | 1.15k Views
LSTM Neural Networks for Language Modeling. Martin Sundermeyer , Ralf Schl¨uter , and Hermann Ney Human Language Technology and Pattern Recognition, Computer Science Department, RWTH Aachen University, Aachen, Germany. INTERSPEECH 2012. 報告者:郝柏翰. Outline. Introduction

E N D
LSTM Neural Networks for Language Modeling Martin Sundermeyer, Ralf Schl¨uter, and Hermann NeyHuman Language Technology and Pattern Recognition, Computer Science Department, RWTH Aachen University, Aachen, Germany INTERSPEECH 2012 報告者:郝柏翰
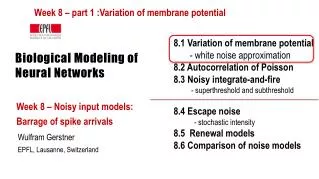
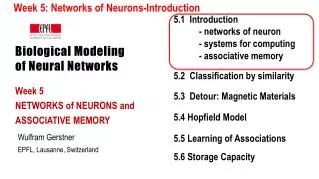
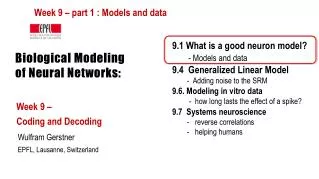
Outline • Introduction • Long Short Term Memory Neural Networks • Experiments • Conclusion
Introduction • Neural networks have become increasingly popular for the task of language modeling. Because neural network LMs overcome a major drawback of backing-off models. • Unfortunately, recurrent neural networks are hard to train using back-propagation through time(BPTT). The main difficulty lies in the well-known vanishing gradient problem which means that the gradient that is propagated back through the network either decays or grows exponentially.
LSTM • The Nodes(blue) are used to control the information flow from the network into the cell and from the cell back into the network. Without modified BPTT algorithm • To avoid this scaling effect, the authors re-designed the unit of a neural network in such a way that its corresponding scaling factor is fixed to one.
LSTM • To reduce the computational effort it was proposed to split the words into a set of disjoint word classes. Then the probability can be factorized as follows: • Where , and is the class of word .
Experiments • Corpus • We found that the perplexity of the models was constantly lower by about 8% compared to the standard recurrent neural network. The perplexities we obtained with the sigmoidal recurrent network closely match those obtained with the rnnlmtoolkit.