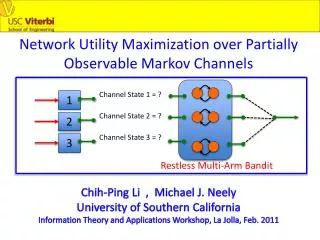
Hierarchical Markov Network
This work presents the Hierarchical Markov Network (HMN), an advanced extension of the Hierarchical Hidden Markov Model (H-HMM), aimed at efficient temporal pattern recognition. By merging identical sub-models, HMN provides a compact representation, enabling effective computation through a new Viterbi algorithm that shares results among parent nodes. This innovative approach addresses scalability and redundancy issues prevalent in traditional Hierarchical HMMs. Applications span speech recognition, handwriting, language processing, and more, promising significant improvements in computational efficiency.


Hierarchical Markov Network
E N D
Presentation Transcript
Hierarchical Markov Network ACKNOWLEDGMENT: Daniel Rubin, Dima Vainbrand, Ronny Ronen, Ohad Falik, Zev Rivlin, Mike Deisher, Shai Fine, Shie Mannor ICRI-CI Retreat 2013 May 9, 2013 Boris Ginzburg ICRI - Computational Intelligence
Summary • Hierarchical Hidden Markov Model (H-HMM):A known statistical model for complex temporal pattern recognition (Fine, Singer, Tishby-1998) • Hierarchical Markov Network (HMN): • Compact and computationally efficient extension of H-HMM based on merging of identical sub-models • A new efficient Viterbi algorithm: sharing of computations for sub-model by its “parents” ICRI - Computational Intelligence
background Hidden Markov Model • Hidden Markov Model (HMM) is among the leading tools used for temporal pattern recognition. • Used in: • Speech recognition • Handwriting • Language processing • Gesture recognition • Bioinformatics • Machine translation • Speech synthesis ICRI - Computational Intelligence
background Hidden Markov Model The state of model is hidden from observer. 20% 30% 3 3 2 5 1 80% 4 1 30% 2 4 40% 2.7 3.4 1.2 4.9 ICRI - Computational Intelligence HMM is stochastic FSM described by Markov model: α(i,j)≔ Prob( q(t+1)=j | q(t)=i) Initial probability: π(i)≔Prob (q(1) = i); State [i] can emit symbol [o] with β(i,o):= Prob ( o | q(t) = i);
background HMM: Viterbi Algorithm Problem:Given the observation sequence: O=( o(1),…o(T) ), what is the most probable state sequence: Q=(q(1),…q(T))? Solution: Forward-Backward (Baum-Welch) algorithm. For each state [x] and time t: Given that system was in [x]at time t, let’s define δ(x,t) - the likelihood of the most probable state sequence,whichcouldgenerate observation ( o(1),…,o(t) ): δ(x,t)≔ max P(q(1),…,q(t-1) | q(t)=x, o(1),…o(t)). We willuselog-likelihood:S(x, t):= -log (δ(x,t)). The S(x,t) iscalledtoken at state [x] at moment t ICRI - Computational Intelligence
background HMM: Viterbi Algorithm Initialization (t=1): S(x,1) = p(x)+ b(x,o(1)); ψ(x,1) = 0; Induction (t t+1): S(y,t+1) = min[ S(x,t) + a(x,y) + b(y,o(t+1)) ]; ψ(y,t+1) = argmin[ S(y,t+1) ]; Termination (t=T): Smin = min[ S(x,T) ]; q(T) = argmin[ S(x,T ) ]; Backward procedure, path recovery (T1): q(t) = ψ(q(t+1),t+1); Forward-backward algorithm (Baum-Welch) is based on principle of dynamic programming (Viterbi) ICRI - Computational Intelligence
background Hierarchy of HMMs Example. Speech recognition - multi-layer hierarchy of HMMs ICRI - Computational Intelligence
background Hierarchical HMM • H-HMM replaces the complex hierarchy of simple HMMs, with one unified model [Fine, Singer, Tishby-1998]. • H-HMM - hierarchical FSM with two types of states: • “Complex” state - state which is itself HMM • “Production” state - simple state on lowest level of hierarchy, which produces observed symbol • Efficient Viterbi algorithm on HHMM with complexity O(T*N2 ), where • T – sequence duration • N – number of states in H-HMM • [K. Murphy & Paskin-2001] and [Wakabayashi & Miura - 2012). ICRI - Computational Intelligence
problem Scalability Problem PROBLEM: structural & computational redundancy, both for “Hierarchy of HMMs” and for H-HMM • Example: dictionary ={speech, beach, peach}. • Use 3-state HMM for phoneme model • 10 instances of HMMs • only 5 different HMM templates ICRI - Computational Intelligence
solution Hidden Markov Network HMN is based on “call-return” semantics: parent node calls sub-HMM, which computes the score of subsequence and returns result to parent node. Hierarchical Markov Network: Compact representation of H-HHM, where each sub-model is embedded once and serves multiple “parents” ICRI - Computational Intelligence
solution HMN: Viterbi algorithm The key observation: Viterbi computations inside identical HMMs, are almost the same. Consider e.g. H-HMM for “beach” and “peach”: ICRI - Computational Intelligence
solution HMN: Viterbi algorithm Token S(.) in sub-HMM “i“ in the word ‘beach”, is based on score of previous phoneme “b”: S(beach.i.x1,t) = [S(beach.b1, t-1) + a(beach.b1, beach.i0)]+ [a(beach.i0, beach.i.x1) + b(beach.i.x1,o(t)) ]; For “peach” S(.) will be based on the score from “p”: S(peach.i.x1,t) = [S(peach.p1, t-1) + a(peach.p1, peach.i0)] + [a(peach.i0, peach.i.x1) + b(peach.i.x1,o(t)) ]; Two last terms in both expressions are equal: a(beach.i0, beach.i.x1) + b(beach.i.x1,o(t)) = a(peach.i0, peach.i.x1) + b(peach.i.x1,o(t)) We can do the computation once, and use it for both words. ICRI - Computational Intelligence
solution HMN: Viterbi algorithm One sub-HMM can serve multiple parents: computes the score of sub-sequence, and returns it to parents ICRI - Computational Intelligence
solution HMN: call-return • Child HMM: • serves multiple calls from multiple nodes. Child maintains list of received calls. • all calls, received at the same moment, are merged and computed together; child keeps list of “return address” • multiple tokens can be generated by one call (all marked by time when call was started) • when token reaches ‘end” state, the score is sent to parent • Parent node: • Maintains list of open calls and prefix scores • Add prefix-score to the score received from child ICRI - Computational Intelligence
solution HMN: call-return ICRI - Computational Intelligence
solution HMN: Temporal hierarchy Inspired by Tali Tishby’ talk yesterday How to support multiple temporal scales on different level of hierarchy? Possible directions: • Exponential increase time scale by each level of hierarchy ∆d = 2* ∆d+1 • One call cover a number of time overlapping sub-sequences, child selects sequence with best score S(x, td) = min (S(x,td+1),S(x,t d+1+1) ICRI - Computational Intelligence
solution HMN: Temporal hierarchy ICRI - Computational Intelligence
solution HMN: performance • HMN has potential performance benefits over HMM/H-HMM if cost of HMM > cost of “call-return”, • Cost of HMM is ~ number of arcs. • Cost of call / return is fixed, depends only on number of return tokens / call; does not depend on size of HMM. Back-of-the envelope: • Cost of Viterbi on 5-state HMM ~ 10 MACs; • Cost of one return token–1 MAC; Additional HMN cost - increased complexity: • book-keeping in HMM, complex parent node structure… ICRI - Computational Intelligence
Next steps Next Steps • A promising idea, need to establish its efficiency beyond plain “back-of-the-envelop”; prototype to check performance claims • Extend HMN theory to support multiple temporal scales on different levels of hierarchy • Connection between Convolutional Neural Network and HMN ICRI - Computational Intelligence
BACKUP ICRI - Computational Intelligence