Download

1 / 50
500 likes | 722 Views
Harvesting Metadata Using OAI-PMH. Roy Tennant California Digital Library. Outline. The Open Archives Initiative OAI-PMH The Harvesting Process Harvesting Problems Steps to a Fruitful Harvest A Harvesting Service Model The OAI Future. Open Archives Initiative.

E N D
Harvesting Metadata Using OAI-PMH Roy Tennant California Digital Library
Outline • The Open Archives Initiative • OAI-PMH • The Harvesting Process • Harvesting Problems • Steps to a Fruitful Harvest • A Harvesting Service Model • The OAI Future
Open Archives Initiative • Aimed at making the large and growing number of repositories of freely available digital content interoperable • Protocol for Metadata Harvesting (OAI-PMH) specifies how repositories can expose their metadata for others to harvest • Over 800 repositories world-wide support the protocol • OAIster.org has indexed nearly 6 million items from over 500 of those repositories
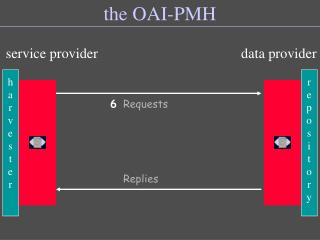
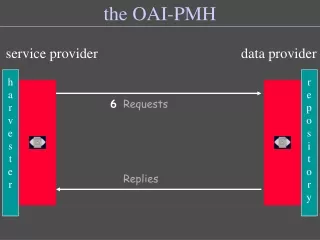
OAI-PMH • Data providers (DP) — those with the stuff • Service providers (SP) — those who harvest metadata and provide aggregation and search services • Software for both DPs and SPs readily available • OAI-PMH verbs: • Identify • ListIdentifiers • ListMetadataFormats • ListSets • ListRecords • GetRecord
OAI Architecture Source: Open Archives Forum Tutorial
Identify • Provides basic information about a repository
ListMetadataFormats • Lists available metadata formats
ListIdentifiers • Lists all identifiers (or only those of the optionally specified set) • Must include metadataPrefix attribute
ListSets • Lists available sets
ListRecords • Lists all records (or only those of the optionally specified set) • Must include metadataPrefix attribute
GetRecord • Retrieves a specific record • Must include metadataPrefix and identifier attributes
The Harvesting Process • Identifying Sources • Selecting Sets • Harvesting • Metadata Processing • Indexing • Interface
Selecting Sets • Review the response to the ListSets verb • May be instructive to search the collection in the native interface, if possible • Look for descriptive pages on the site being harvested
Harvesting • Many harvesting applications are available, I will focus on: • Public Knowledge Project (PKP) Harvester • Virginia Tech Perl Harvester • Library software vendors increasingly offer harvesting products (e.g., ExLibris’ MetaIndex)
Virginia Tech Perl Harvester +-----------------------------------------+ | Harvester Sample Configurator | +-----------------------------------------+ | Version 1.1 :: July 2002 | | Hussein Suleman <hussein@vt.edu> | | Digital Library Research Laboratory | | www.dlib.vt.edu :: Virginia Tech | ------------------------------------------+ Defaults/previous values are in brackets - press <enter> to accept those enter "&delete" to erase a default value enter "&continue" to skip further questions and use all defaults press <ctrl>-c to escape at any time (new values will be lost) Press <enter> to continue [ARCHIVES] Add all the archives that should be harvested Current list of archives: No archives currently defined ! Select from: [A]dd [D]one Enter your choice [D] : a{return} [ARCHIVE IDENTIFIER] You need a unique name by which to refer to the archive you will harvest metadata from Examples: nsdl-380602, VTETD Archive identifier [] : nsdl-380602{return}
Indexing • Pick your favorite database/indexing software: • MySQL • SWISH-E • Whatever is lying around… • May need to specifically set up a method to search across the entire record • May need different fields for indexing than for display • Will need to deal with element collision
Interface • Software interface (API) for other applications: • SRU/SRW? • MXG? • Arbitrary Web Services schema? • User interface: • What functions do you want your users to be able to perform? • What kinds of displays do you want?
Harvesting Problems • Sets • Metadata Formats • Metadata Artifacts • Granularity • Metadata Variances
Sets • Records are harvested in clumps, called “sets” created by DPs • No guidelines exist for defining sets • Examples: • Collection • Organizational structure • Format (but is a page image an image? See example)
Metadata Formats • Only required format is simple Dublin Core, although any format can be made available in addition • Few DPs surface richer metadata • Simple DC is simply too simple! • Example (artifact vs. surrogate dates)
Metadata Artifacts • “unintended, unwanted aberrations” • Sample causes: • Idiosyncratic local practices • Anachronisms • HTML code • Examples: • Circa = string of dates for searching purposes • [electronic resource]
Granularity • Record Granularity: what is an “object”? • A book, or each individual page? • Examples: CDL, Univ. of Michigan • Metadata Granularity: • Multiple values in one field • Example: Univ. of Washington
Metadata Variances • Subject terminology differences • Disparities in recording the same metadata • Example: date variances • Mapping oddities or mistakes • Examples: 1) format into description, 2) description into subject
Steps to a Fruitful Harvest • Needs Assessment (it’s the user, stupid) • DP Identification and Communication • Metadata Capture • Metadata Analysis • Metadata Subsetting • Metadata Normalization • Metadata Enrichment • Indexing & Display • Interface (it’s still the user, stupid)
Needs Assessment • What are you trying to accomplish? • What will your users want to be able to do? • What metadata will you need, and what procedures will you need to set up to enable these activities? • Which repositories have what you want? • Is what they have (e.g., sets, metadata) usable as is, or ?
DP Identification & Communication • Identification: • Use UIUC directory of DPs to identify potential sources • Communication: • Not required to tell them you are harvesting, but may help establish a good relationship • May want to request that they surface a richer metadata format and/or provide a different set
Metadata Capture • Sample questions to answer: • Individual sets, or all? • Richer metadata formats available? • How frequently to reharvest? • Start from scratch each time or update? • Many software options
Metadata Analysis • Finding out what you have (and don’t have) • Encoding practices • Gap analysis (e.g., missing fields, etc.) • Mistakes (e.g., mapping errors) • Software can help • Commercial software like Spotfire • In-house or open source software tools
Five elements are used 71% of the time Source: 2002 Master’s Thesis, Jewel Hope Ward, UNC Chapel Hill
Metadata Subsetting • DP sets are unlikely to serve all SP uses well • SPs will need the ability to subset harvested metadata
Metadata Normalization • Normalizing: to reduce to a standard or normal state • Prototype date normalization service screen
Metadata Enrichment • Adding fields and/or qualifiers may be useful or required, for example: • Metadata provider information • Geographic coverage • Subject terms mapped to a different thesaurus • Authority control record • The enrichment process may be the same tool as the subsetting tool (i.e., find a cluster of records and perform an action)
<date>1863.</date> <date>[2001 or 2002.]</date> <identifier>SHS 1,679</identifier> <identifier>http://content.lib.washington.edu/cgi-bin/htmlview.exe?CISOROOT=/loc&CISOPTR=58</identifier> <identifier>http://content.lib.washington.edu/loc/image/1679.jpg</identifier> Indexing & Display • Selected fields may need to be mapped to specific indexing and display elements • Particularly required if harvesting different metadata formats • But also needs to be done with multiple, conflicting fields:
The OAI Future • Further protocol development • Services layered on top of OAI-PMH • Shared software tools • Best practices for both DPs and SPs