
Chapter 4: Syntax analysis
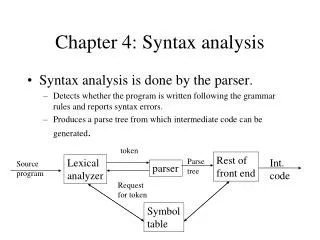
Chapter 4: Syntax analysis. Syntax analysis is done by the parser. Detects whether the program is written following the grammar rules and reports syntax errors. Produces a parse tree from which intermediate code can be generated . token. Rest of front end. Lexical analyzer. Parse tree.

Chapter 4: Syntax analysis
E N D
Presentation Transcript
Chapter 4: Syntax analysis • Syntax analysis is done by the parser. • Detects whether the program is written following the grammar rules and reports syntax errors. • Produces a parse tree from which intermediate code can be generated. token Rest of front end Lexical analyzer Parse tree Int. code Source program parser Request for token Symbol table
The syntax of a programming language is described by a context-free grammar(Backus-Naur Form (BNF)). • Similar to the languages specified by regular expressions, but more general. • A grammar gives a precise syntactic specification of a language. • From some classes of grammars, tools exist that can automatically construct an efficient parser. These tools can also detect syntactic ambiguities and other problems automatically. • A compiler based on a grammatical description of a language is more easily maintained and updated.
A grammar G = (N, T, P, S) • N is a finite set of non-terminal symbols • T is a finite set of terminal symbols • P is a finite subset of • An element is written as • S is a distinguished symbol in N and is called the start symbol. • Language defined by a grammar • We say “aAb derives awb in one step”, denoted as “aAb=>awb”, if A->w is a production and a and b are arbitrary strings of terminal or nonterminal symbols. • We say a1 derives am if a1=>a2=>…=>am, written as a1=>am • The languages L(G) defined by G are the set of strings of the terminals w such that S=>w. * *
Example: A->aA A->bA A->a A->b
Chomsky Hierarchy (classification of grammars) • A grammar is said to be • regular if it is • right-linear, where each production in P has the form, or . Here, A and B are non-terminals and w is a terminal • or left-linear • context-free if each production in P is of the form , where and • context sensitive if each production in P is of the form where • unrestricted if each production in P is of the form where
Languages specified by different types of grammars: • Language1 = {a, aa, aaa, aaaa, ….} • Language2 = {ab, aabb, aaabbb, aaaabbbb, …} • Language3 = {abc, aabbcc, aaabbbccc, …}
Context-free grammar is sufficient to describe most programming languages. • Example: a grammar for arithmetic expressions. <expr> -> <expr> <op> <expr> <expr> -> ( <expr> ) <expr> -> - <expr> <expr> -> id <op> -> + | - | * | / derive -(id) from the grammar: <expr> => -<expr> => - (<expr>) =>-(id) sentence: a strings of terminals that can be derived from S sentential form: a strings of terminals or none terminals that can be derived from S.
derive id + id * id from the grammar: E=>E+E=>E+E*E=>E+E*id=>E+id*id=>id+id*id • leftmost/rightmost derivation -- each step replaces leftmost/rightmost non-terminal. E=>E+E=>id+E=>id+E*E=>id+id*E=>id+id*id • Parse tree: • A parse tree pictorially shows how the start symbol of a grammar derives a specific string in the language. Given a context-free grammar, a parse tree has the following properties: • The root is labeled by the start symbol • Each leaf is labeled by a token or the empty string • Each interior node is labeled by a nonterminal • If A is a non-terminal labeling some interior node and abcdefg..z are the labels of the children of that node from left to right, then A->abcdefg..z is a production of the grammar.
The leaves of the parse tree read from left to right is called “yield” of the parse tree. It is equivalent to the string derived from the nonterminal at the root of the parse tree. • An ambiguous grammar is one that can generate two or more parse trees that yield the same string. • E.G string -> string + string string->string - string string ->0|1|2|3|4|5|6|7|8|9 string=>string + string =>string - string + string => 9 -5 + 2 string=>string - string=>string - string + string =>9-5+2


















