Download

1 / 4
0 likes | 4 Views
Artificial Intelligence Dataset (AI) models depend on high-quality data to produce accurate and dependable outcomes. Nevertheless, raw data frequently contains inconsistencies, errors, and extraneous information, which can adversely affect model performance. Effective data cleaning and preprocessing are critical steps to improve the quality of AI datasets, thereby ensuring optimal training and informed decision-making.<br><br>

E N D
Globose Technology Solutions Pvt Ltd March 21, 2025 How to Clean and Preprocess AI Data Sets for Better Results Introduction Arti?cial Intelligence Dataset (AI) models depend on high-quality data to produce accurate and dependable outcomes. Nevertheless, raw data frequently contains inconsistencies, errors, and extraneous information, which can adversely affect model performance. Effective data cleaning and preprocessing are critical steps to improve the quality of AI datasets, thereby ensuring optimal training and informed decision-making. The Importance of Data Cleaning and Preprocessing Explore our developer-friendly HTML to PDF API Printed using PDFCrowd HTML to PDF
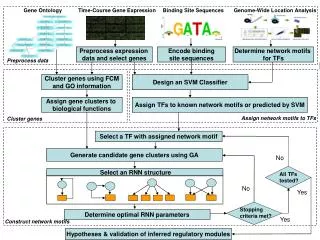
The quality of data has a direct impact on the effectiveness of AI and machine learning models. Inadequately processed data can result in inaccurate predictions, biased results, and ineffective model training. By adopting systematic data cleaning and preprocessing techniques, organizations can enhance model accuracy, minimize errors, and improve overall AI performance. Procedures for Cleaning and Preprocessing AI Datasets 1. Data Collection and Analysis Prior to cleaning, it is essential to comprehend the source and structure of your data. Identify key attributes, missing values, and any potential biases present in the dataset. 2. Addressing Missing Data Missing values can hinder model learning. Common approaches to manage them include: Deletion: Removing rows or columns with a signi?cant number of missing values. Imputation: Filling in missing values using methods such as mean, median, mode, or predictive modeling. Interpolation: Estimating missing values based on existing trends within the dataset. 3. Eliminating Duplicates and Irrelevant Data Duplicate entries can distort AI training outcomes. It is important to identify and remove duplicate records to preserve data integrity. Furthermore, eliminate irrelevant or redundant features that do not enhance the model’s performance. 4. Managing Outliers and Noisy Data Outliers can negatively impact model predictions. Employ methods such as The Z-score or Interquartile Range (IQR) approach to identify and eliminate extreme values. Smoothing techniques, such as moving averages, to mitigate noise. 5. Data Standardization and Normalization To maintain uniformity across features, implement: Standardization: Adjusting data to achieve a mean of zero and a variance of one. Normalization: Scaling values to a speci?ed range (e.g., 0 to 1) to enhance model convergence. 6. Encoding Categorical Variables Machine learning models perform optimally with numerical data. Transform categorical variables through: One-hot encoding for nominal categories. Label encoding for ordinal categories. Explore our developer-friendly HTML to PDF API Printed using PDFCrowd HTML to PDF
7. Feature Selection and Engineering Minimizing the number of features can enhance model performance. Utilize techniques such as: Principal Component Analysis (PCA) for reducing dimensionality. Feature engineering to develop signi?cant new features from existing data. 8. Data Partitioning for Training and Testing Effective data partitioning is essential for an unbiased assessment of model performance. Typical partitioning strategies include: An 80-20 split, allocating 80% of the data for training purposes and 20% for testing. Utilizing cross-validation techniques to enhance the model's ability to generalize. Tools for Data Cleaning and Preprocessing A variety of tools are available to facilitate data cleaning, such as: Pandas and NumPy, which are useful for managing missing data and performing transformations. Scikit-learn, which offers preprocessing methods like normalization and encoding. OpenCV, speci?cally for improving image datasets. Tensor Flow and Pytorch, which assist in preparing datasets for deep learning applications. Conclusion The processes of cleaning and preprocessing AI datasets are vital for achieving model accuracy and operational e?ciency. By adhering to best practices such as addressing missing values, eliminating duplicates, normalizing data, and selecting pertinent features, organizations can signi?cantly improve AI performance and minimize biases. Utilizing sophisticated data cleaning tools can further streamline these efforts, resulting in more effective and dependable AI models. For professional AI dataset solutions, visit Globose Technology Solutions to enhance your machine learning initiatives. Popular posts from this blog February 28, 2025 Exploring the Services Offered by Leading Image Annotation Companies Introduction With the ongoing advancements in arti?cial intelligence (AI) and machine learning (ML), the demand for high- … quality annotated data has reached unprecedented levels. Companies specializing in image Explore our developer-friendly HTML to PDF API Printed using PDFCrowd HTML to PDF
READ MORE February 26, 2025 The Role of an Image Annotation Company in Enhancing AI Precision Introduction The effectiveness of Arti?cial Intelligence (AI) is fundamentally dependent on the … quality of the data it processes, with Image Annotation Company being pivotal in READ MORE March 04, 2025 The Signi?cance of Varied AI Data Sets in Mitigating Bias in AI Introduction Arti?cial Intelligence Data Sets (AI) is transforming various sectors by facilitating automation, … improving decision-making processes, and increasing operational e?ciency. READ MORE Explore our developer-friendly HTML to PDF API Printed using PDFCrowd HTML to PDF