Download

1 / 32
320 likes | 423 Views
GPU. Graphic Processing Unit. GPU. ARCHITETTURA DI COMUNICAZIONE. Display. Architettura di Comunicazione. AGP 2x, 4x e 8x (banda massima 528 MB/sec ). PCI Express (la banda massima teorica è di 4 GB/sec in ingresso e di 4 GB/sec in uscita contemporaneamente). Efficiente

E N D
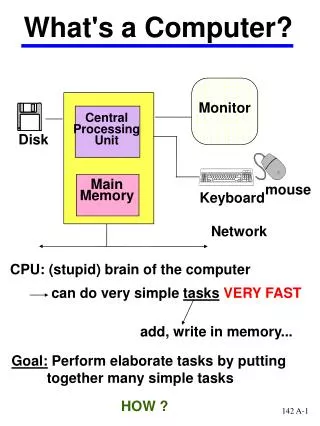
GPU Graphic Processing Unit
GPU ARCHITETTURA DI COMUNICAZIONE
Display Architettura di Comunicazione AGP 2x, 4x e 8x (banda massima 528 MB/sec) PCI Express(la banda massima teorica è di 4 GB/sec in ingresso e di 4 GB/sec in uscita contemporaneamente) Efficiente Co-Processore Off-Screen Multi-Pass Algorithm
Architettura PIPELINE GRAFICA
( 2D ) Primitive Assembly ( 2D ) Render Vertex Model Pixel colorati fragment Position (x,y,z) Normal (x,y,z) Color (r,g,b,a) Rasterizzazione ( 2D ) ( 3D ) Vertex Model Position (x,y,z) Normal (x,y,z) Color (r,g,b,a) ( 2D ) Traditional Graphics Pipeline La Pipeline Grafica è una pipeline di processori con differenti caratteristiche (tipicamente processori SIMD o MIMD) che operano su stream di primitive grafiche (vertici, frammenti, texture …) Le operazioni sono eseguite in relativo isolamento. Questo significa che l'elaborazione di un dato vertice o fragment non influisce sugli altri. Multi-Pass Algorithm
RecentGraphics Pipeline SIMD MIMD Multi-Pass Algorithm
RecentGraphics Pipeline L’estensione Framebuffer object (FBO) permette il multi-RENDER TO TEXTUREs Off-Screen MULTIPASS Algorithm RENDER TO TEXTURE (PING PONG)
Trasform Lighting Vertex 3D Vertex 2D Vertex Processing gluLookAt gluPerspective 3D Model 2D Image glLightfv gluPerspective gluLookAt
Fragment Processor - Shading x1 (r1,g1,b1,a1) (r2,g2,b2,a2) y1 x2 y2 Immagine 2D RASTERIZZATA Immagine 2D RENDERIZZATA INPUT Multi-Pass Algorithm OUTPUT NB: L’I/O è una lettura / scrittura ordinata (r2,g2,b2,a2) = F((r1,g1,b1,a1) , TEX ) TEX F è il fragment shader(il programma che colora il frammento corrente utilizzando una o più texture)
Architettura SIMD
Streaming –elaborazione SIMD 8 5 2 7 4 1 6 3 0 8 5 2 6 3 0 7 4 1 U0 U1 K U2 pn p3 p2 p1 p0 pn p3 p2 p1 p0 K K Letture Ordinate Scritture Ordinate uniform vec3 LightPosition; const float SpecularContribution = 0.3; const float DiffuseContribution = 1.0 - SpecularContribution; varying float LightIntensity; varying vec2 MCposition; void main(void) { vec3 ecPosition = vec3(gl_ModelViewMatrix * gl_Vertex); vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal); vec3 lightVec = normalize(LightPosition - ecPosition); vec3 reflectVec = reflect(-lightVec, tnorm); vec3 viewVec = normalize(-ecPosition); float diffuse = max(dot(lightVec, tnorm), 0.0); float spec = 0.0; if (diffuse > 0.0) { spec = max(dot(reflectVec, viewVec), 0.0); spec = pow(spec, 16.0); } LightIntensity = DiffuseContribution * diffuse + SpecularContribution * spec; MCposition = gl_Vertex.xy; gl_Position = ftransform(); } oppure oppure Input Ordinato Output Ordinato Kernel STREAM: vettore ordinato di dati (vertici o frammenti) KERNEL: opera su ogni elemento dello stream indipendentemente SIMD Processor INPUT Stream OUTPUT Stream Flussi INDIPENDENTI
4 4 7 7 6 6 5 5 3 3 21 21 9 6 3 7 4 1 8 5 2 FU FU FU Display Multi-Pass Algorithm Fragment Processor Fragment Streaming (r,g,b,a) Letture Ordinate Scritture Ordinate oppure oppure Letture Random Input Ordinato Output Ordinato Texture FBO based Una texture può essere vista come un array bidimensionale o tridimensionale
Architettura Gerarchia di Memoria
Gerarchia di Memoria Mem.CENTRALE Cache Registri ALU INTERFACCIA GRAFICA Mem.VIDEO OpenGL Direct3D Utilizzano particolari accessi a memoria utilizzando specifiche primitivecomevertici,fragment,textureeframebuffer Ho quattro tipi astrazioni grafiche in corrispondenza dei seguenti stream: · Vertexstream · Texturestream · Fragmentstream · Framebufferstream (Il Framebuffer stream comincia e termina all’interno della GPU)
Texture Stream + FB Stream E’ necessaria L’estensione GLEW delle OpenGL per gestire il Framebuffer Object (FBO) Texture Stream Multipass AlgorirhmRender to Texture FB Stream
Architettura PROGRAMMABILE
Assemble primitives I vertici sono poi raggruppati in primitive: punti, linee e triangoli. Cull / Clip / Setup esegue le operazioni pre-primitiva, rimuovendo le primitive che non sono visibili perché dietro la visuale e ritagliando le primitive che intersecano il riquadro visualizzabile. z-cull scarta i pixel che sono occlusi da oggetti Rasterizzazionecalcola quanti fragment compongono ogni primitiva Fragment è un “possibile” pixel Quad / RGBA I fragment lasciano i fragment processor nell'ordine in cui sono stati rasterizzati e fluiscono all'unità z-compare e all'unità blend, che eseguono vari test, quindi il colore finale viene scritto sul render target o sul framebuffer. 1 - 8 unità parallele Pipeline GPU 1 – 128 unità parallele
Riepilogo sullaProgrammabilità Le zone non programmabili, posso comunque sfruttarle, come blocchi decisionali, per scartare determinate porzioni dello stream in input senza ricorrere a codice aggiuntivo. Tale tecnica sicuramente alleggerisce il codice degli shader file ma il vero vantaggio risiede nel guadagno ottenuto in fase di esecuzione.
GPU Linguaggi di programmazione
Le differenze spesso sono puramente sintattiche mentre l'insieme delle funzioni disponibili è praticamente identico. I Metalinguaggi non sono linguaggi veri e propri ma delle librerie che incluse in un linguaggio di programmazione aggiungono nuovi comandi di facile lettura e scrittura che facilitano il lavoro del programmatore. Sia Sh che Brooksono metalinguaggi che si appoggiano al C++, e permettono l'utilizzo della GPU come coprocessore. La differenza principale tra Sh e Brook è che il primo si propone per un utilizzo grafico, ma facilita la stesura anche di applicazioni general purpose mentre Brook è specializzato per la general purpose computation. Inoltre Brook ha un suo compilatore che traduce il codice in Cg che poi deve essere ricompilato, mentre Sh viene compilato direttamente insieme al codice C++, saltando questa fase intermedia. Linguaggi di Shading Gestiscono array ed è possibile definire strutture, prevedono controlli di flusso quali le condizioni, i cicli e infine le chiamate di funzioni. Data la natura dei dati che devono gestire, il supporto a vettori e matrici e relativi operatori matematici sono fortemente ottimizzati ed è prevista tutta una serie di funzioni tipiche dell'ambiente grafico. GLSL
La vera differenza sta nella portabilità. Interfacce: OpenGL/Direct3D
OpenGL CompilazioneDinamica
Gestori di finestre: GLUT / SDL La visualizzazione avviene in una finestra messa a disposizione dal window system: Il frame buffer viene mappato sulla finestra OpenGL è indipendente dallo specifico window system, quindi non ha modo di fare da solo questa mappatura Utilizza il paradigma event driven programming Gestione interazione applicazione utente tramite callback (message handlers ecc.) attivate in risposta a vari eventi (messaggi) gestiti dal sistema operativo (pressione di un tasto del mouse o della tastiera, reshape della finestra, ecc.) Il flusso principale dell’applicazione è in mano all’utente, o meglio al sistema operativo che intercetta le azioni dell’utente
NVIDIA G80 Architecture
SLI Scalabile Link Interface SLI Frame Rendering:Combinadue schedegrafiche PCI Express con un connettore SLI per scalare in modo trasparente le prestazioni delle applicazioni su unsingolo display, presentandole al sistema operativo come un’unica scheda grafica SLI Multi View:Combina la potenza didue schedegrafiche NVIDIA Quadro PCI Express per estendere supiù displayuna singola finestra di un’applicazione OpenGL ad accelerazione hardware, eseguire una singola applicazione per GPU con più output su display, o abilitare altri usi flessibili di due schede grafiche PCI Express. Interconnessione