Download

1 / 59
880 likes | 1.62k Views
Structure and function of genome. Genome and Gene. gene is the basic functional unit of heredity in a living organism . Its nature is the nucleic sequence encoding a polypeptide or protein .

E N D
Genome and Gene gene is the basic functional unit of heredity in a living organism. Its nature is the nucleic sequence encoding a polypeptide or protein . Gene determines amino acid sequences of a polypeptide, and also determines the cell-specific traits. rRNA, tRNA, also have their own gene. genome is the entirety of an organism's hereditary information. It is encoded either in DNA or, for many types of virus, in RNA. The genome includes both the genes and the non-coding sequences of the DNA of haploid. The human genome contains 24 chromosomes.
Section 1 genome of virus The main types of virus genome :Double-stranded DNA: SV40, adenovirus, herpes virus. Single-stranded DNA: parvovirus, M13 phage Double-stranded RNA: retrovirus. Plus-strand RNA: polio virus, corona virus. Minus-strand RNA: rabies virus, influenza virus, measles virus. Reverse transcription virus: specific taxa, such as HIV, HCV.
genome of SV40virus • Double-stranded circular DNA • Regions of early genes and late genes. Early genes: T antigen and t antigen. Late gene: VP1, VP2, VP3. there are regulatory regions between early genes and late genes : including origin of replication, promoter, enhancer.
genome of SV40virus • There is the phenomenon of alternative splicing and overlapped genes
retrovirus • Carrying two identical positive-stranded RNA. bind two tRNA in host cellThe structural proteins of virus : envelope protein(env), Capsid protein (gag). Reverse transcriptase (pol)
genome of Retrovirus • Coding region containing three genes: gag, pol and env. Non-coding region: R region: 20 ~ 80 nucleotide repeats. PBS: primer binding sites, binding to tRNA as a primer. U region :promoter in U3 and polyadenylation signal in U5. provirus: long terminal repeat (LTR ) in the end.
genome is simple, with a small number of coding genes. The genome size of different viruses varied significantly. Hepatitis B virus: 3.2kb; pox virus: 300kb. Genomes of different viruses have individual natures of nucleic acid. Most of genes is single copy with single-stranded nucleic acid. Retrovirus: diploid. Influenza virus: 8 single-stranded RNA. Retrovirus: 10 double-stranded RNA.
Most of the genome is coding sequences, a part of it is regulatory sequence, and very few of it is structure sequence.Replication and transcription of virus depend on host cells. Eukaryotic viruses can contain introns, while bacteria and viruses not. Alternative splicing happened in viral genome and produced several kinds of mRNA from one transcript. gene overlapping is common. A sequence may have two kinds of open reading frame, resulting protein with very different amino acid.
Section 2 Genome ofprokaryotes • Containing the complete set of genome to ensure their own metabolism and reproduction. The survival of mycoplasma, chlamydia etc depends on the host. Containing genes which can regulate their own growth and metabolism based on the environmental change.No differentiation and development in prokaryotes ,and the number of gene is smaller than that of eukyrocytes.
Genome of E. coli Size of E.coli:4.6 × 106bp, 4288 ORF; 2584 operons. The average size of the gene:951bp. The average interval between genes:118bp
features of prokaryotic genome Genome usually consists of double-stranded circular DNA. Prokaryotic DNA does not form a chromosome. There is no nucleus, but there is a nucleoid where DNA concentrate. The average size of genes is around 106~107 bp. The number of genes is fewer
the features of structure and function of prokaryotic genome An operon is a functioning unit of genomic material containing a cluster of genes under the control of a single regulatory signal or promoter. The genes are transcribed together into a mRNA strand and either translated together in the cytoplasm. Polycistronic mRNA:a single mRNA molecule that codes for more than one protein
The majority of the genome is single sequence, and rarely duplicated. rRNA gene are multiple copies. Isozymes in genome: E. coli has three acetolactate synthase, and two branches mutase. The majority of sequences are coding sequence, with a very few non-coding sequences. There is a certain regulatory sequences which often contained inverted repeat. Most genes are in the state of expression.
Plasmid DNA A plasmid is an extra chromosomal DNA molecule separate from the chromosomal DNA which is capable of replicating independently from the chromosomal DNA. In many cases, it is circular and double-stranded. Plasmids usually occur naturally in bacteria, Its size varies from 1.5 to 15 kb.
to classify plasmids is by function. There are 3 main classes: Fertility-F-plasmids, which contain tra-genes. They are capable of conjugation (transfer of genetic material between bacteria which are touching). Resistance-(R)plasmids, which contain genes that can build a resistance against antibiotics or poisons and help bacteria produce pili. Col-plasmids, which contain genes that code for (determine the production of) bacteriocins, proteins that can kill other bacteria.
F factor • Conjugation: transfer of genetic material between bacteria which are touching
Transposable elements Transposable elements :the genetic material of genome that can move independently They can cause the changes of genome structure and gene sequences
The types of transposable elements insertion sequence transposon transposable bacteriophage。
Insertion sequence An insertion sequence is a short DNA sequence that acts as a simple transposable element. IS have two major characteristics: they are small, generally around 700 to 2500 bp in length only code for proteins implicated in the transposition. These proteins are usually the transposase which catalyses the enzymatic reaction allowing the IS to move, and also one regulatory protein which either stimulates or inhibits the transposition activity. The coding region in an IS is usually flanked by inverted repeats. Frequency of translocation is 10-7
Transposon Transposons are sequences of DNA that can move around to different positions within the genome of a single cell, a process called transposition. transposons, which carry transposase gene and accessory genes such as antibiotic resistance genes In the process, they can cause mutations and change the amount of DNA in the genome. Transposons were also once called jumping genes, and are examples of mobile genetic elements. They were discovered by Barbara McClintock early in her career, for which she was awarded a Nobel Prize in 1983.
Genetic effects of transposable elements 1 The transposition of a transposable element is not movement of itself, but to copy a new copy of the gene. 2 When transposition occurred, the target sequence doubled, and located on both sides of transposable elements to form direct repeat sequences 3 form the co-integrate in the process of transposition 4 chromosomal aberrations possibly occurred5 transposable elements can be excised from the original location
Transposons are mutagens. They can damage the genome of their host cell in different ways: A transposon that inserts itself into a functional gene will most likely disable that gene. After a transposon leaves a gene, the resulting gap will probably not be repaired correctly. Multiple copies of the same sequence, such as Alu sequences can hinder precise chromosomal pairing during mitosis and meiosis, resulting in unequal crossovers, one of the main reasons for chromosome duplication. Diseases that are often caused by transposons include hemophilia A and B, severe combined immunodeficiency, porphyria, predisposition to cancer, and Duchenne muscular dystrophy. Additionally, many transposons contain promoters which drive transcription of their own transposase. These promoters can cause aberrant expression of linked genes, causing disease or mutantphenotypes
Significance of bacterial genomics research To shed more light on the characteristics of pathogenic microorganisms and pathogenic mechanism. To provide more convenient tools for the discovery of disease-causing genes To Reveal more pathogen-specific sequence, and to improve the accuracy of identification of pathogens. To provide a basis for the discovery of vaccines and screening of durgs
Section 3 Eukaryotic genomes Most eukaryotes are multi-cellular organisms, with the complex phenomenon of differentiation and development. Eukaryotes have more genes and more complex regulation mechanism than that in prokaryotes Eukaryotes have a nucleus, and the genome in the nucleus bind to histone proteins to form chromatin. Mitochondria and chloroplasts of the eukaryotic also have their own genetic material.
There are 280 kinds of eukaryotic genome project, of which 19 kinds have been completed, including 3 kinds of plants, 9 kinds of fungi, 3 kinds of protozoa, Caenorhabditis elegans, Drosophila, mouse, human
The structural characteristics of eukaryotic genomes Linear double-stranded DNA, and each species has a fixed number of chromosomes. eukaryotic cells are generally diploid. Yeast has both haploid and diploid states. Haploid and polyploid widely exist in eukaryotic species . Structure of eukaryotic genomes is complex, and the number of genes is large. The size of the human genome is about 1000 times bigger than that of E. coli. The number of human genes is about 10 times more than that of E. coli.
An mRNA molecule is said to be monocistronic when it contains the genetic information to translate only a single protein. • polycistronic mRNA carries the information of several genes, which are translated into several proteins. These proteins usually have a related function and are grouped and regulated together in an opero rRNA and tRNA mRNA are polycistronic. There is no operon, and function-related genes are often sparse in different parts of the genome. α-globin gene locates in chromosome 16. β-globin gene locates in chromosome 11.
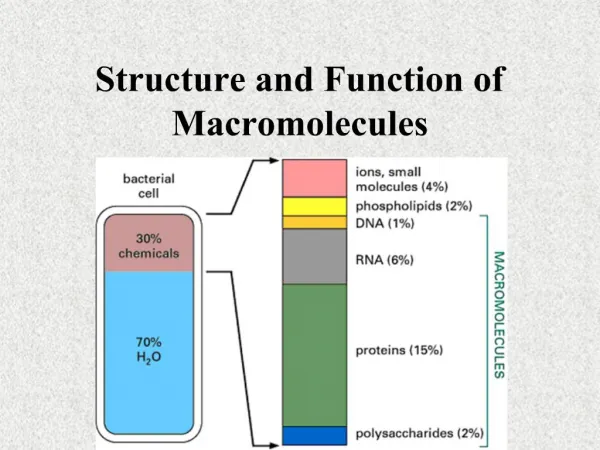
The vast majority of genome is non-coding sequence, with the role of forming structure and regulation. coding sequences less than 10%. Size of the human genome is 3 × 109 bp, with only 3 × 104 genes, the average size of genes is 105 bp. Containing a large number of repetitive sequences. Highly repetitive sequences: 105 or more Moderately repetitive sequence :10-104 Single-copy sequence: less than 10
The structural characteristics of eukaryotic genomes Eukaryotic genes are split genes An intron is a DNA region within a gene that is not translated into protein The non-coding sequences within genes. exon can refer to the sequence in the DNA or its RNA transcript
The structural characteristics of eukaryotic genomes A gene family is a set of genes with a known homology. They are generally biochemically similar. Globin gene family (α, β, γ, δ, ε, ζ). Superfamily: gene members shared structural homology and different function.
The structural characteristics of eukaryotic genomes A gene cluster is a set of two or more genes that serve to encode for the same or similar products. Because populations from a common ancestor tend to possess the same varieties of gene clusters, they are useful for tracing back recent evolutionary history. Histone gene cluster: 5 kinds of genes clustered in tandem, and there are multiple copies.
α-globin gene cluster • An example of a gene cluster is the Human a-globin gene cluster, which contains 3 functional genes and 3 non-functional gene for similar proteins • α1, α2: α gene duplicate with adult expression. ξ: embryonic genes. ψξ, ψα1, ψα2: pseudo-genes, 75% homology with α, accumulate much mutations ,so it can not be expressed.
β-globin gene cluster ε: expressed in early embryonic stage. γ: in embryonic stage. δ: express at birth with a extremely low level. β: key protein expressed in adult. ψβ, ψβ1: pseudogene.
structural characteristics of eukaryotic genomes Eukaryotic genomes are highly variable.During meiosis, association and exchange occurred in homologous chromosome Eukaryotic genomes also have mobile genetic material. transposon The human genome contains a large number of transposon, most of which have been inactivated by mutation.
Features of human genome • Genes There are estimated ca. 54,000 human protein-coding genes. The number of human genes seems to be less than a factor of two greater than that of many much simpler organisms, such as the roundworm and the fruit fly. human cells make extensive use of alternative splicing to produce several different proteins from a single gene, and the human proteome is thought to be much larger than those of the afore mentioned organisms Besides, most human genes have multiple exons, and human introns are frequently much longer than the flanking exons Human genes are distributed unevenly across the chromosomes. Each chromosome contains various gene-rich and gene-poor regions, which seem to be correlated with chromosome bands and GC-content. The significance of these nonrandom patterns of gene density is not well understood.In addition to protein coding genes, the human genome contains thousands of RNA genes, including tRNA, rRNA, microRNA, and other non-coding RNA genes.
The composition of the human genome The known coding sequence is only about 1.5%, there are a large number of interval sequence between the genes, insertion sequence and repetitive sequence within the gene. Coding sequence: coding proteins and a variety of RNA, and part of the coding sequences is. Non-coding sequences include: Regulatory sequences: promoter, enhancer and so on. Intron: it also contain regulatory sequences. Interval sequence: Junction area between genes. Repetitive sequences.
the repetitive sequences of the human genome Inverted repeat sequence Tandem repeat sequence: satellites, small satellites, mini-satellite, micro-satellite DNA. Gene cluster: group proteins, rRNA, tRNA and so on. Interspersed repeated sequence: Alu family, Kpn family and so on. Single-copy sequence: gene coding sequences and spacer sequences.
Satellite DNA consists of highly repetitive DNA, and is so called because repetitions of a short DNA sequence tend to produce a different frequency of the nucleotidesadenine, cytosine, guanine and thymine, and thus have a different density from bulk DNA - such that they form a second or 'satellite' band when genomic DNA is separated on a density gradient.
A minisatellite is a section of DNA that consists of a short series of bases 10–60bp.These occur at more than 1000 locations in the human genome. Some minisatellites contain a central (or "core") sequence of letters “GGGCAGGANG” (where N can be any base) or more generally a strand bias with purines (Adenosine (A) and Guanine (G)) on one strand and pyrimidines (Cytosine (C) and Thymine (T)) on the other. It has been proposed that this sequence per se encourages chromosomes to swap DNA. In alternative models, it is the presence of a neighbouring cis-acting meiotic double-strand break hotspot which is the primary cause of minisatellite repeat copy number variations. Somatic changes are suggested to result from replication difficulties (which might include replication slippage, among other phenomena).
Microsatellites, Simple Sequence Repeats (SSRs), or tandem repeats, are repeating sequences of 1-6 base pairs of DNA.[1] Microsatellites are typically neutral and co-dominant. They are used as molecular markers in genetics, for kinship, population and other studies. They can also be used to study gene duplication or deletion
1. 反向重复顺序Inverted repeat sequence • 亦称倒位重复顺序(inverted repeats sequence)。 • 两端反向重复,可形成发卡结构。 • 无插入:GGTACC • 有插入:GGTNNN…NNNACC • 人类基因组有约 5% 的反向重复顺序,大部分以单拷贝形式散布于整个基因组。 • 常见于蛋白结合区与转录调控区。 • Also known as inverted repeat sequence Inverted repeats at both ends can form a hairpin. Without insertion: GGTACC with insertion: GGTNNN ... NNNACC There is about 5% inverted repeat sequence in human genome , and the majority is the form of single copy spersed in the whole genome. Commonly found in protein-binding regions and the transcriptional regulatory region.
2. 串联重复顺序Tandem repeat sequence • 串联重复序列是一个固定的重复单位头尾相连形成的重复。 • 串联重复序列约占基因组的 10%。 • 将基因组打断后进行密度梯度离心时发现,称卫星 DNA。 • 组蛋白基因,rRNA 基因等也属串联重复序列。 • Tandem repeat sequence is duplication formed by a fixed repeat which is connected end to endTandem repeat sequences account for about 10% of the genome. • satellite DNA. Histone genes, rRNA genes also are tandem repeat.
卫星 DNA Satellite DNA • 重复次数非常高,可达数百万。每一个重复序列簇有数千重复单元。 • 按序列特征可分为Ⅰ、Ⅱ、Ⅲ、Ⅳ、α、β。每种类型有不同家族,其核心序列不同。 • 原位杂交证实:各组卫星 DNA 主要位于异染色质,特别是中心粒。但很少具有染色体特异性。 • II 和 III 分布于几乎分布于所有染色体。 • 一些卫星 DNA 具有染色体特异性和区域特异性。 • β 存在于 Y 染色体等的着丝粒区域。 • α分布于所有染色体的着丝粒区域 Repetition number is very high, up to several millions. There are thousands of repeatitive units in each repeat cluster. It can be divided into Ⅰ, Ⅱ, Ⅲ, Ⅳ, α, β by sequence features . Each type has a different family whith different from its core sequence. In situ hybridization confirmed: Satellite DNA in each group are mainly located in heterochromatin, in particular the centriole. But rarely has a chromosome-specific. II and III is found in almost distributed in all chromosomes. Some satellite DNA has the chromosome-specific and regional specificity. β exists in the centromere region of Y chromosome. α is found in all the centromere region of chromosome 。
小卫星 DNA Small satellite DNA • 可变数目串联重复: • variable number of tandem repeats,VNTR • 6-70 bp,串联成簇,重复几到几十次,个体间重复次数高度可变。 • 端粒: • 位于染色体末端,具有保护作用。 • TTAGGG 组成的重复序列,往往重复数千倍 variable number of tandem repeats : variable number of tandem repeats, VNTR 6-70 bp, tandem clustered, repeat a few to dozens of times, the repeated number is of highly variable among individuals. Telomere: At the end of chromosome and has a protective effect. The repeat sequences composed of TTAGGG often repeated thousands of times
微卫星 DNAMicrosatellite DNA • 又称短串联重复: • short tandem repeats, STR • 1-4 bp 串联重复。 • 2 bp 重复最常见,一般为 (AC)n 或 (TG)n。 • 重复 10-60。 • 当 n 大于 14 时,个体间重复次数高度可变。 • STR 在基因组分布非常广泛。 • 占约 5%,平均每 30-50 kb 就有一个 STR 序列。 Also known as short tandem repeats: short tandem repeats, STR 1-4 bp tandem repeats. the most common appearance is 2 bp duplication and is usually (AC) n or (TG) n. Repeat 10-60. When n is greater than 14, repeated number among individuals is highly variable. STR are widely distributed in the genome. Accounted for about 5%, there is a STR sequence averaging 30-50 kb.