Download

1 / 11
150 likes | 357 Views
Building a Predictive Parsing Table. The table is built by adding each production A ::= α to one or more cells M(A, a) if a is a terminal in FIRST(α) if a is a terminal in FOLLOW(A) and ε is in FIRST(α) if a = $ and ε is in FIRST(α) and $ is in FOLLOW(A)

E N D
Building a Predictive Parsing Table • The table is built by adding each production A ::= α to one or more cells M(A, a) • if a is a terminal in FIRST(α) • if a is a terminal in FOLLOW(A) and ε is in FIRST(α) • if a = $ and ε is in FIRST(α) and $ is in FOLLOW(A) • If there is more than one production in any cell, it is because the grammar is ambiguous and therefore is not LL(1) • If there is no production in some cell M(B, b), a parser should report a syntax error if it seeks nonterminal B and b is the next token. http://csiweb.ucd.ie/staff/acater/comp30330.html Compiler Construction
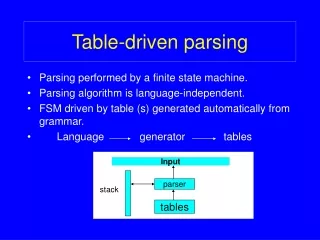
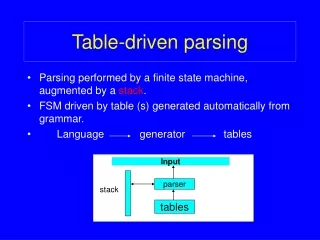
Predictive Parsing without Recursive Descent • A predictive parser need not operate by recursive descent. It may be written to operate non-recursively, with an explicit stack push $ onto stack; push start symbol S onto stack; let a be the first symbol of w; let T be the top stack symbol; while (T /= $) { if (T = a) {pop stack; let a be next symbol of w} elseif (X is a terminal) {error()} elseif (M[T,a] iserror entry) {error()} elseif (M[T,a]=‘T::=U1U2…Uk’) { {output the production ‘T::=U1U2…Uk’; pop stack; push Uk, Uk-1, …U2, U1 onto stack} let T be the top stack symbol} input “w” a + b $ stack X Predictive Parsing Program Y Output Z $ Parsing Table M http://csiweb.ucd.ie/staff/acater/comp30330.html Compiler Construction
Rules for happy recursion • A recursive routine should always have a simple case that does not involve recursion • A recursive routine should never call itself recursively without changing something involved in the test for the simple case, e.g. • the arguments • an input buffer pointer • some global data structure http://csiweb.ucd.ie/staff/acater/comp30330.html Compiler Construction
Panic Mode Error Recovery in a Predictive Parser If the parser is looking for a nonterminal A and finds empty cell • (Usual) skip tokens in the input until finding one in a “synchronising set” • Effectiveness depends on choosing a good synchronising set. • Should recover quickly from those errors likely to arise in practice • Heuristics for selecting synchronising sets for A, and then parser responses • all of FOLLOW(A) … and then pop A • also all of FIRST(B) if A typically embedded in B … and then pop A • as EXPR is typically embedded in STMT, for example • If A ε, then the (unique) responsible production can be used as a default • Just pop A from parser stack, report an A has been inserted, and continue http://csiweb.ucd.ie/staff/acater/comp30330.html Compiler Construction
Phrase Level Error Recovery in a Predictive Parser • Each cell can be filled with a special-purpose error routine • Such routines typically remove tokens from the input, and/or pop an item from the stack • It is ill-advised to modify the input stream or the stack without removing items, because it is then hard to guarantee that error recovery will always terminate http://csiweb.ucd.ie/staff/acater/comp30330.html Compiler Construction
Bottom-Up Parser • A bottom-up parser works from leaves of a tree up to a root node • It progressively reduces many terminals (input tokens) to a single S nonterminal • It builds a derivation in reverse order • specifically, a rightmost derivation when parsing left-to-right • Each step it takes involves recognising and reducing a so-called handle in the input http://csiweb.ucd.ie/staff/acater/comp30330.html Compiler Construction
Handles • A handle is, strictly speaking, a production of the grammar which is involved in a derivation step of a rightmost derivation of a sentential form • If S αAw αβw then the production A ::= β in the position after α is a handle • A more convenient, somewhat incorrect usage is that this RHS – β– is a handle • If the grammar is unambiguous, every right sentential form has exactly one handle • To the right of a handle, there can be only terminals – because if there were any nonterminals the sentential form would not be part of a rightmost derivation rm rm http://csiweb.ucd.ie/staff/acater/comp30330.html Compiler Construction
Handle Pruning • The steps of a rightmost derivation can be found in reverse order by handle pruning • NB the reverse of a rightmost derivation is not the same as a leftmost derivation • all derivations naturally proceed through sentential forms from top to bottom, • the reverse of a derivation proceeds through them from bottom to top E E + T E + T • Successive handles are found in a left-to-right sweep of input, and “pruned” • A deterministic “Shift-Reduce Parser” can be built provided the grammar is LR – that is, LR(k) for some k. • Automatic parser generators make it practical to build deterministic shift-reduce parsers T * F T F F id F id id id http://csiweb.ucd.ie/staff/acater/comp30330.html Compiler Construction
Shift-Reduce Parser • A Shift-Reduce Parser uses an input buffer and a stack of grammar symbols • It repeatedly chooses among four operations • shift a symbol from input to stack • reduce handle seen at top of stack • accept (when stack=‘$S’, input=‘$’) • error • It uses the stack contents and up to k symbols of input buffer to choose its action • must resolve shift/reduce conflicts • must resolve reduce/reduce conflicts • hence LR Parsing uses a parsing table id + id + id * id $ id Shift/Reduce Parser Output + E state $ Parsing Table http://csiweb.ucd.ie/staff/acater/comp30330.html Compiler Construction
LR Parsing benefits • LR grammars are proper superset of LL grammars • enough descriptive power for all typical programming language constructs • non-LR constructs can be avoided in programming language design • No backtracking is required: therefore efficiently implementable • Errors can be detected as soon as is theoretically possible on left-to-right scan • The major disadvantage, that LR parsers are very difficult to write by hand, can be overcome using parser-generator programs – such as YACC http://csiweb.ucd.ie/staff/acater/comp30330.html Compiler Construction
Automaton states for sets of ‘items’ • Each item is a partially-complete grammar production • From A ::= B C D get items • A ::= • B C D • A ::= B • C D • A ::= B C • D • A ::= B C D • • The dots in items indicate how much of the RHS of a production could have been recognised • Parsing table associates actions and transitions with lookahead symbols http://csiweb.ucd.ie/staff/acater/comp30330.html Compiler Construction