Download
1 / 2
20 likes | 101 Views
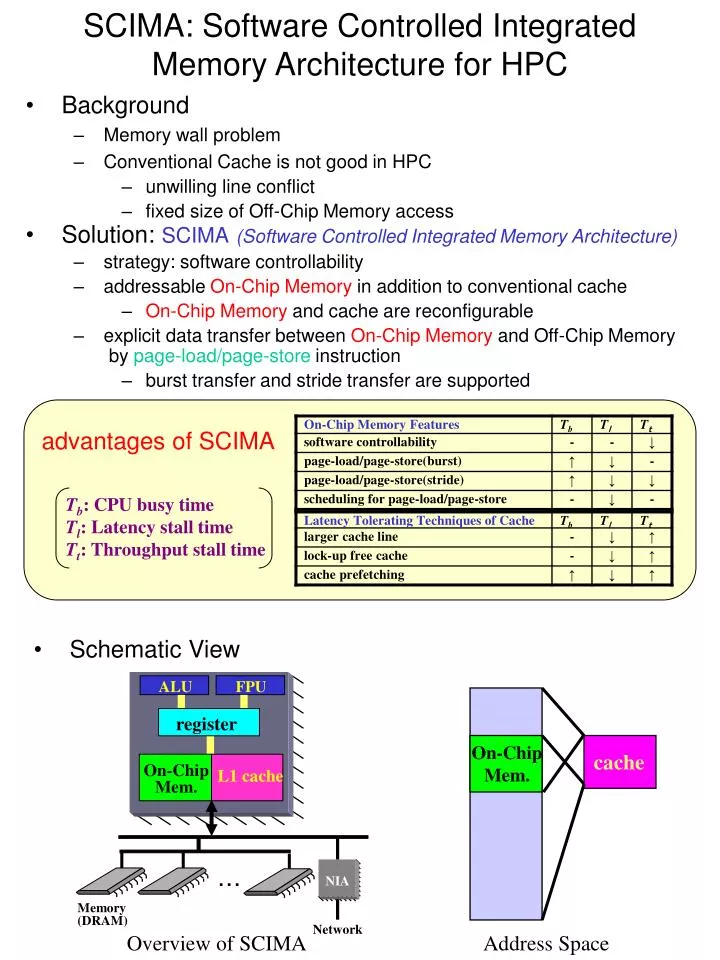
T b : CPU busy time T l : Latency stall time T t : Throughput stall time. NIA. ・・・. Memory. (DRAM). Network. SCIMA: Software Controlled Integrated Memory Architecture for HPC. Background Memory wall problem Conventional Cache is not good in HPC unwilling line conflict

E N D
Tb: CPU busy timeTl: Latency stall timeTt: Throughput stall time NIA ・・・ Memory (DRAM) Network SCIMA: Software Controlled Integrated Memory Architecture for HPC • Background • Memory wall problem • Conventional Cache is not good in HPC • unwilling line conflict • fixed size of Off-Chip Memory access • Solution: SCIMA(Software Controlled Integrated Memory Architecture) • strategy: software controllability • addressableOn-Chip Memoryin addition to conventional cache • On-Chip Memory and cache are reconfigurable • explicit data transfer between On-Chip Memory and Off-Chip Memory by page-load/page-store instruction • burst transfer and stride transfer are supported advantages of SCIMA • Schematic View ALU FPU register On-Chip Mem. cache L1 cache On-ChipMem. Overview of SCIMA Address Space
reusability not-reusable reusable consecutive-ness use On-Chip Mem. as a stream buffer reserve On-ChipMem. for reused data consecutive reserve On-Chip Mem. for reused data stride use On-Chip Mem. as a stream buffer reserve On-Chip Mem. for reused data irregular use cache ::: latency-stall reduction by burst transfer latency & throughput-stall reduction by stride transfer throughput-stall reduction by software controllability Latency/Throughput stall is reduced for wide variety of data access Throughput ratio=2:1Latency=40 Throughput ratio=8:1Latency=160 future technology trend Throughput ratio=2:1Latency=40 Throughput ratio=8:1Latency=160 future technology trend • SCIMA provides various data placement and utilization scheme according to the characteristics of data access SCIMA: Experimental Results • Evaluation Results Throughput Ratio = Ratio between on-chip and off-chip memory throughputLatency = Memory access latency for off-chip memory (latency for the first data) FT QCD SCIMA is robust to large throughput ratio and long memory access latency caused by current technology trend of CPU-memory speed gap






















