Download

1 / 27
280 likes | 449 Views
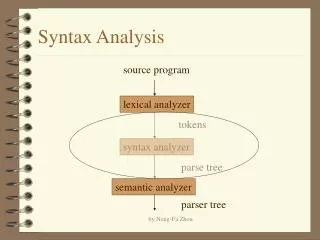
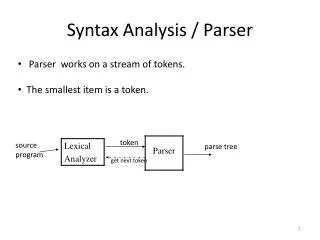
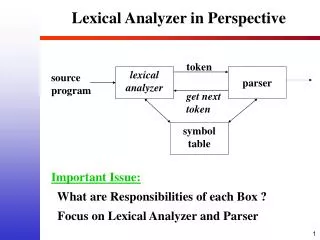
Syntax Analyzer (Parser). Lexical Analyzer and Parser. Parser. Accepts string of tokens from lexical analyzer (one token at a time) Verifies whether or not string can be generated by grammar Reports syntax errors (recovers if possible). Errors. Lexical errors (e.g. misspelled word)

E N D
Parser • Accepts string of tokens from lexical analyzer (one token at a time) • Verifies whether or not string can be generated by grammar • Reports syntax errors (recovers if possible)
Errors • Lexical errors (e.g. misspelled word) • Syntax errors (e.g. unbalanced parentheses, missing semicolon) • Semantic errors (e.g. type errors) • Logical errors (e.g. infinite loop)
Error Handling • Report errors clearly and accurately • Recover quickly if possible • Poor error recover may lead to bunch of errors • Very poor programming style if source code does not handle errors!!
Context Free Grammars • CFGs can represent recursive constructs that regular expressions can not • A CFG consists of: • A finite set of terminals (in our case, this will be the set of tokens) • A finite set of non-terminals (syntactic-variables) • A finite set of productions rules in the following form: A where A is a non-terminal and is a string of terminals and non-terminals (including the empty string) • A start symbol (one of the non-terminal symbol)
Derivations (Part 1) • One definition of language: the set of strings that have valid parse trees • Another definition: the set of strings that can be derived from the start symbol E E + E | E * E | (E) | – E | id E => -E (read E derives –E) E => -E => -(E) => -(id) (read E derives –(id))
Derivations (Part 2) • αAβ => αγβif A γis a production and α and β are arbitrary strings of grammar symbols • If a1 => a2 => … => an, we say a1 derives an • => means derives in one step • *=> means derives in zero or more steps • +=> means derives in one or more steps
Sentences and Languages • Let L(G) be the language generated by the grammar G with start symbol S: • Strings in L(G) may contain only tokens of G • A string w is in L(G) if and only if S +=> w • Such a string w is a sentence of G • Any language that can be generated by a CFG is said to be a context-free language • If two grammars generate the same language, they are said to be equivalent
Sentential and Sentences let S *=> - If contains non-terminals, it is called as a sentential form of G. - If does not contain non-terminals, it is called as a sentence of G.
Leftmost and rightmost Derivations • Leftmost Derivations -- Only the leftmost nonterminal in any sentential form is replaced at each step • If α derives β by a leftmost derivation, then we write αlm*=> β • Rightmost Derivations -- Only the rightmost nonterminal in any sentential form is replaced at each step • If α derives β by a rightmost derivation, then we write αrm*=> β
Example Left-Most Derivation E -E -(E) -(E+E) -(id+E) -(id+id) Right-Most Derivation E -E -(E) -(E+E) -(E+id) -(id+id) lm lm lm lm lm rm rm rm rm rm
E E E - E - E - E ( E ) ( E ) E + E E E - E - E ( E ) ( E ) E E + E + E id id id Parse Tree • A parse tree can be seen as a graphical representation of a derivation. • -Inner nodes are non-terminal symbols. • -The leaves of a parse tree are terminal symbols. E -E -(E) -(E+E) -(id+E) -(id+id)
E E + E id * E E id id E * E E E + E id id id Ambiguity A grammar produces more than one parse tree for a sentence is called as an ambiguous grammar. E E+E id+E id+E*E id+id*E id+id*id E E*E E+E*E id+E*E id+id*E id+id*id
Ambiguity (cont.) • For the most parsers, the grammar must be unambiguous. • unambiguous grammar unique selection of the parse tree for a sentence • We should eliminate the ambiguity in the grammar during the design phase of the compiler. • We have to prefer one of the parse trees of a sentence (generated by an ambiguous grammar) to disambiguate that grammar to restrict to this choice.
Ambiguity (cont.) stmt if expr then stmt | if expr then stmt else stmt | otherstmts if E1then if E2then S1else S2 stmt if expr then stmt else stmt E1if expr then stmt S2 E2 S1 stmt if expr then stmt E1if expr then stmt else stmt E2 S1 S2 2 1
Ambiguity (cont.) • We prefer the second parse tree • (else matches with closest if) • So, we have to disambiguate our grammar to reflect this choice. • The unambiguous grammar will be: stmt matchedstmt | unmatchedstmt matchedstmt ifexprthenmatchedstmtelsematchedstmt | otherstmt unmatched ifexprthenstmt | ifexprthenmatchedstmelseunmatchedstm
Ambiguity – Operator Precedence • Ambiguous grammars (because of ambiguous operators) can be disambiguated according to the precedence rules. E E+E | E*E | E^E | id | (E) disambiguate the grammar precedence: ^ (right to left) * (left to right) + (left to right) E E+T | T T T*F | F F G^F | G G id | (E)
Left Recursion • A grammar is left recursion if it has a non-terminal A such that there is a derivation A +=> Aαfor some string • Most top-down parsing methods can not handle left-recursive grammars
Eliminate Left-Recursion A A | where does not start with A eliminate left recursion A A’ A’ A’ | an equivalent grammar In general, A Aα1 | Aα2 | … | Aαm | β1 | β2 | … | βn A β1A’| β2A’ | … | βnA’ A’ α1A’ | α2A’ | … | αmA’ | ε
Eliminate Left-Recursion -- Example E E+T | T T T*F | F F id | (E) eliminate left recursion E T E’ E’ +T E’ | T F T’ T’ *F T’ | F id | (E)
Left-Recursion -- Problem • S Aa | b • A Sc | d • This grammar is not immediately left-recursive, but it is still left-recursive. • So, we have to eliminate all left-recursions from our grammar by following some kind of algorithm!!
Eliminate Left-Recursion -- Algorithm - Arrange non-terminals in some order: A1 ... An - for i from 1 to n do { - for j from 1 to i-1 do { replace each production Ai Aj by Ai 1 | ... | k where Aj 1 | ... | k } // eliminate immediate left-recursions among Ai productions }
Eliminate Left-Recursion -- Example S Aa | b A Ac | Sd | f - Replace A Sd with A Aad | bd So, we will have A Ac | Aad | bd | f - Eliminate the immediate left-recursion in A A bdA’ | fA’ A’ cA’ | adA’ | So, the resulting equivalent grammar which is not left-recursive is: S Aa | b A bdA’ | fA’ A’ cA’ | adA’ |
Eliminate Left-Recursion – Example2 S Aa | b A Ac | Sd | f - Eliminate the immediate left-recursion in A A SdA’ | fA’ A’ cA’ | - Replace S Aa with S SdA’a | fA’a - So, we will have S SdA’a | fA’a | b - Eliminate the immediate left-recursion in S S fA’aS’ | bS’ S’ dA’aS’ | So, the resulting equivalent grammar which is not left-recursive is: S fA’aS’ | bS’ S’ dA’aS’ | A SdA’ | fA’ A’ cA’ |
Left Factoring stmt if expr then stmt else stmt | if expr then stmt • when we see if, we cannot know which production rule to choose to re-write stmt in the derivation. In general, A αβ1 | αβ2 A αA’ A’ β1 | β2
Limitations of CFGs • There are some language constructions in the programming languages which are not context-free. • Example: L1 = {wcw | w is in (a|b)*} • CFG can not verify repeated strings • Example: L2 = {anbmcndm | n≥1 & m≥1} • Can not verify repeated counts • Therefore, some checks put off until semantic analysis