Download
1 / 2
20 likes | 113 Views
Identification of Small RNAs In Common Bean ( Phaseolus vulgaris ) from 454 transcriptome sequencing data Yaqoob Thurston 1 , Zhanji Liu 2 , Venu Kalavacharla 1,3

E N D
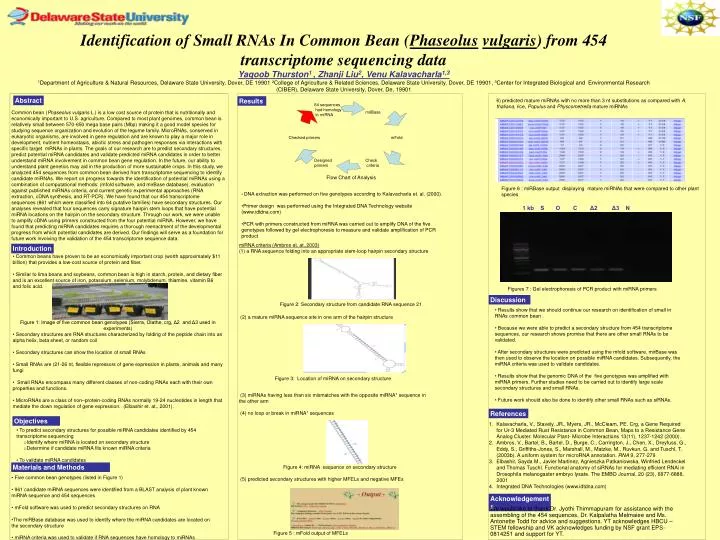
Identification of Small RNAs In Common Bean (Phaseolusvulgaris) from 454 transcriptome sequencing data Yaqoob Thurston1 , Zhanji Liu2, Venu Kalavacharla1,3 1Department of Agriculture & Natural Resources, Delaware State University, Dover, DE 19901 2College of Agriculture & Related Sciences, Delaware State University, Dover, DE 19901, 3Center for Integrated Biological and Environmental Research (CIBER), Delaware State University, Dover, De, 19901 Abstract Results 6) predicted mature miRNAs with no more than 3 nt substitutions as compared with A. thaliana, rice, Populus and Physcometrella mature miRNAs Common bean (Phaseolus vulgaris L.) is a low cost source of protein that is nutritionally and economically important to U.S. agriculture. Compared to most plant genomes, common bean is relatively small between 570-650 mega base pairs (Mbp) making it a good model species for studying sequence organization and evolution of the legume family. MicroRNAs, conserved in eukaryotic organisms, are involved in gene regulation and are known to play a major role in development, nutrient homeostasis, abiotic stress and pathogen responses via interactions with specific target mRNAs in plants. The goals of our research are to predict secondary structures, predict potential miRNA candidates and validate predicted miRNA candidates in order to better understand miRNA involvement in common bean gene regulation. In the future, our ability to understand plant genetics may aid in the production of more sustainable crops. In this study, we analyzed 454 sequences from common bean derived from transcriptome sequencing to identify candidate miRNAs. We report on progress towards the identification of potential miRNAs using a combination of computational methods: (mfold software, and mirBase database), evaluation against published miRNAs criteria, and current genetic experimental approaches (RNA extraction, cDNA synthesis, and RT-PCR). We have found that our 454 transcriptome sequences (861 which were classified into 64 putative families) have secondary structures. Our analyses revealed that four sequences carry signature hairpin stem loops that have potential miRNA locations on the hairpin on the secondary structure. Through our work, we were unable to amplify cDNA using primers constructed from the four potential miRNA. However, we have found that predicting miRNA candidates requires a thorough reenactment of the developmental progress from which potential candidates are derived. Our findings will serve as a foundation for future work involving the validation of the 454 transcriptome sequence data. . Flow Chart of Analysis Figure 6 : miRBase output displaying mature miRNAs that were compared to other plant species • DNA extraction was performed on five genotypes according to Kalavacharla et. al. (2000). • Primer design was performed using the Integrated DNA Technology website (www.idtdna.com) • PCR with primers constructed from miRNA was carried out to amplify DNA of the five genotypes followed by gel electrophoresis to measure and validate amplification of PCR product 1 kb S O C Δ2 Δ3 N • miRNA criteria (Ambros et. at.,2003) • a RNA sequence folding into an appropriate stem-loop hairpin secondary structure • (2) a mature miRNA sequence site in one arm of the hairpin structure • (3) miRNAs having less than six mismatches with the opposite miRNA* sequence in the other arm • (4) no loop or break in miRNA* sequences • Figure 4: miRNA sequence on secondary structure • (5) predicted secondary structures with higher MFELs and negative MFEs • Figure 5 : mFold output of MFELs • ( Introduction • Common beans have proven to be an economically important crop (worth approximately $11 billion) that provides a low-cost source of protein and fiber. • Similar to lima beans and soybeans, common bean is high in starch, protein, and dietary fiber and is an excellent source of iron, potassium, selenium, molybdenum, thiamine, vitamin B6 and folic acid. Figure 1: Image of five common bean genotypes (Sierra, Olathe, crg, Δ2 and Δ3 used in experiments) • Secondary structures are RNA structures characterized by folding of the peptide chain into an alpha helix, beta sheet, or random coil • Secondary structures can show the location of small RNAs • Small RNAs are (21-26 nt, flexiblerepressors of gene expression in plants, animals and many fungi • Small RNAs encompass many different classes of non-coding RNAs each with their own properties and functions. • MicroRNAs are a class of non–protein-coding RNAs normally 19-24 nucleotides in length that mediate the down regulation of gene expression. (Elbashir et. at., 2001). * Figures 7 : Gel electrophoresis of PCR product with miRNA primers Discussion Figure 2: Secondary structure from candidate RNA sequence 21 • Results show that we should continue our research on identification of small in RNAs common bean . • Because we were able to predict a secondary structure from 454 transcriptome sequences, our research shows promise that there are other small RNAs to be validated. • After secondary structures were predicted using the mfold software, mirBase was then used to observe the location on possible miRNA candidates. Subsequently, the miRNA criteria was used to validate candidates. • Results show that the genomic DNA of the five genotypes was amplified with miRNA primers. Further studies need to be carried out to identify large scale secondary structures and small RNAs. • Future work should also be done to identify other small RNAs such as siRNAs. Figure 3: Location of miRNA on secondary structure References Kalavacharla, V., Stavely, JR., Myers, JR., McCleam, PE. Crg, a Gene Required for Ur-3 Mediated Rust Resistance in Common Bean, Maps to a Resistance Gene Analog Cluster. Molecular Plant- Microbe Interactions 13(11), 1237-1242 (2000). Ambros, V., Bartel, B., Bartel, D., Burge, C., Carrington, J., Chen, X., Dreyfuss, G., Eddy, S., Griffiths-Jones, S., Marshall, M., Matzke, M., Ruvkun, G. and Tuschl, T. (2003b). A uniform system for microRNA annotation. RNA 9, 277-279 Elbashir, Sayda M., Javier Martinez, Agnieszka Patkaniowska, Winfried Lendeckel and Thomas Tuschl. Functional anatomy of siRNAs for mediating efficient RNAi in Drosophila melanogaster embryo lysate. The EMBO Journal, 20 (23), 6877-6888, 2001 Integrated DNA Technologies (www.idtdna.com) Objectives • To predict secondary structures for possible miRNA candidates identified by 454 transcriptome sequencing • Identify where miRNA is located on secondary structure • Determine if candidate miRNA fits known miRNA criteria • To validate miRNA candidates Materials and Methods • Five common bean genotypes (listed in Figure 1) • 961 candidate miRNA sequences were identified from a BLAST analysis of plant known miRNA sequence and 454 sequences • mFold software was used to predict secondary structures on RNA • The miRBase database was used to identify where the miRNA candidates are located on the secondary structure • miRNA criteria was used to validate if RNA sequences have homology to miRNAs Acknowledgements We would like to thank Dr. Jyothi Thimmapuram for assistance with the assembling of the 454 sequences, Dr. Kalpalatha Melmaiee and Ms. Antonette Todd for advice and suggestions. YT acknowledges HBCU –STEM fellowship and VK acknowledges funding by NSF grant EPS-0814251 and support for YT.