Download

1 / 14
140 likes | 473 Views
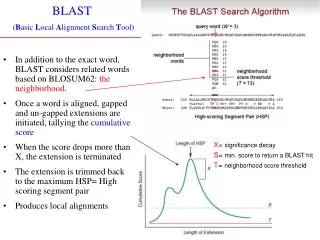
Point Specific Alignment Methods PSI – BLAST & PHI – BLAST. Even using Local Sequence Alignment Techniques and Scoring Matrices such as high powers of PAM or low values of BLOSUM n Database Searching may not find what we want. Many homologous sequences share only limited sequence identity.

E N D
Point Specific Alignment Methods PSI – BLAST & PHI – BLAST
Even using Local Sequence Alignment Techniques and Scoring Matrices such as high powers of PAM or low values of BLOSUMn Database Searching may not find what we want. • Many homologous sequences share only limited sequence identity. • While they may adopt the same three-dimensional structure, they may not have apparent similarity in pair wise alignments. • Cases are known where BLAST and FASTA miss 10 – 20% of “meaningful” hits. • Scoring matrices do not accurately portray the similarity that may exist within a particular family of proteins. They are tied to a more general database.
In an attempt to correct this the idea of a Position Specific Scoring Matrix (PSSM) was developed. In PSI-BLAST the query sequence is subjected to a normal BLAST search. From this a multiple-sequence alignment is made between the query and all “significant” hits. A new scoring matrix of size L rows and 20 columns is derived using the frequency of the proteins within each position of the alignment. (L is the length of the query sequence.)
The previous example was taken from Pevsner, J., Bioinformatics and Functional Genomics, Wiley-LISS, 2003, p139 And involves a search with Query sequence RBP4 (NP_006735) Here is a portion of the PSSM generated by Pevsner’s Search Note Lines 6, 11, 12, 14, 15, 16, and 42 all of which are scores for A against the 20 proteins.
The PSSM is then used as the query (not your original sequence) to the database and another search to the database. The statistical significance of each match is estimated and results are reported. These last three steps are repeated iteratively until no new sequences are reported that fall above the given significance level or the user chooses to terminate the search.
A Schemematic of the PSI-Blast Process Note the original query is not included in loop 2.
Pevsner reported the following data concerning his 2002 search with original query NP_006735 At this point we will do an update of these results by going to http://www.ncbi.nlm.nih.gov/blast and choosing the PSI-BLAST option with the default parameters.
A Dramatic Illustration of the Increased Sensitivity ot PSI-BLAST Searching
PHI-BLAST stands for Pattern-Hit Initiated BLAST Often it is the case that a protein of interest contains a signature pattern of amino acids and residues that help to define it as part of the family. This “signature” may be rather short in terms of its length within the sequence, but it is important in defining a structural of functional domain. It may even be the characteristic of an unknown function as is the case in the following example:
Care must be taken to choose a pattern that is not common within the database. The algorithm only allows patterns that are expected to occur at most once in every 5000 residues. In the previous example the pattern is GXW where the X may be any amino acid. Then we specify candidates for the following amino acids [YF], [EA], or [IVLM]. These choices are based on our observation of the test sequences and our knowledge of the behavior of proteins (common protein substitutions, hydrophobicity, etc.) The database search is then performed looking for sequences that contain the prescribed pattern. Further iterations may be done based on this output using PSI-BLAST which no longer uses the PHI pattern, but the PSSM from the first report.
The output from the PHI-BLAST program is the same as that of the PSI-BLAST program except that the position of the pattern is highlighted in each of the alignments .
The following alignment was obtained from an investigation of immunoglobulin C-Region Domains: We will investigate the conserved sequence: LXCLV using PHI-BLAST. Our starting point is with the Ig 2A C region of the mouse, SwissProt Accession #P01865 We enter this information into the PHI-BLAST page
The first iteration of this search yields 31 new statistically significant hits. One of these is given below. Note the *’s over the location of the pattern LXCLV Subsequent iterations are performed by PSI-BLAST independent of the pattern. This search converged after 13 iterations.