Download
1 / 23
230 likes | 247 Views
Harness the power of Big Vertical Data with the innovative PTreeSet for efficient querying and datamining capabilities in the Big Data realm. Learn about the advanced data structure model and methods for both horizontal and vertical operations.

E N D
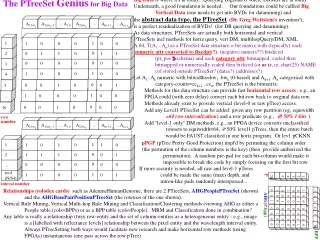
The PTreeSet Genius for Big Data Big Data is where it's at today! Querying BigData is where DBMSs are at today. Underneath, a good foundation is needed. Our foundations could be callled Big Vertical Data (one needs to get into BVDs for datamining) and the abstract data type, the PTreeSet (Dr. Greg Wettstein's invention!), is a perfect residualization of BVDs! (for DB querying and datamining). As data structures, PTreeSets are actually both horizontal and vertical. PTreeSets incl methods for horiz query, vert DM, multihopQuery/DM, XML A tbl, T(A1...An) as a PTreeSet data structure = bit matrix with (typically) each numeric attr converted to fixedpt(?), (negative numers??) bitsliced (pt_posschema) and each category attr bitmapped; coded then bitmapped or numerically coded then bisliced (or as is, ie, char(25) NAME col stored outside PTreeSet? (dates?) (addresses?) Let A1..Ak numeric with bitwidths=bw1..bwk (0-based) and Ak+1..An categorical with category-counts=cck+1...ccn, the PTreeSet is the bitmatrix: 1 A1,bw1 A1,bw1-1 ... A1,0 A2,bw2 ... Ak+1,c1 ...An,ccn 2 3 4 1 0 0 0 1 0 0 1 5 ... 0 1 1 0 0 1 1 2 7B 0 0 0 0 0 0 0 P 3 1 0 0 0 1 0 0 4 0 0 1 0 0 0 1 5 1 0 0 0 1 0 0 ... 0 0 1 0 0 0 0 N A1,bw1 A1,bw1-1 ... A1,0 A2,bw2 ... Ak+1,c1 ...An,ccn row number 1 0 1 0 1 1 0 1 1 1 1 0 0 0 1 2 0 0 0 0 0 0 0 ... 1 0 0 0 1 0 1 roof (N/64) BPP 1 2 3 4 5 ... 3B inteval number 1 0 0 0 1 0 0 0 1 1 0 0 1 1 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 0 0 0 1 1 0 0 0 1 0 0 0 0 1 0 0 0 0 AHG(P,bpp) Methods for this data structure can provide fast horizontal row access , e.g., an FPGA could (with zero delay) convert each bit-row back to original data row. Methods already exist to provide vertical (level-0 or raw pTree) access. Add any Level1 PTreeSet can be added: given any row partition (eg, equiwidth =64 row intervalization) and a row predicate (e.g., 50% 1-bits ). Add "level-1 only" DM methods, e.g., an FPGA device converts unclassified rowsets to equiwidth=64, 50% level1 pTrees, then the entire batch would be FAUST classified in one horiz program. Or lev1 pCKNN. pPGP (pTree Pretty Good Protection) impl'd by permuting the column order (the permution of the column numbers is the key) (then provide authorized the permutation). A random pre-pad for each bit-column would make it impossible to break the code by simply focusing on the first bit row. If more security is needed, all raw and level-1 pTrees could be made the same (max) depth, and intron-like pads randomly interspersed... Relationships (rolodex cards) such as AdenineHumanGenome, there are 2 PTreeSets, AHGPeoplePTreeSet (shown) and the AHGBasePairPositionPTreeSet (the rotation of the one shown). Vertical Rule Mining, Vertical Multi-hop Rule Mining and Classification/Clustering methods (viewing AHG as either a People table (cols=BPPs) or as a BPP table (cols=People). MRM and Classification done in combination? Any table is really a relationship (twix row-entity and the set of column-entities as a heterogeneous entity - e.g., image is a [labelled with reflectance levels] relationship between the pixel entity and the wavelength interval entity. Always PTreeSetting both ways would facilitate new research and make horizontal row methods (using FPGAs) instantaneous (one pass across the row pTree)
Separate class R using midpoint of means (mom) method: Calc a vomV vomR d-line d v2 v1 std of distances, vod, from origin along the d-line FAUST Oblique (our best classifier?) PR=P(X o dR ) < aR1 pass gives classR pTree D≡ mRmV d=D/|D| (mR+(mV-mR)/2)od = a = (mR+mV)/2od(works also if D=mVmR, Training≡placingcut-hyper-plane(s) (CHP) (= n-1 dim hyperplane cutting space in two). Classification is 1 horizontal program (AND/OR) across pTrees, giving a mask pTree for each entire predicted class (all unclassifieds at-a-time) Accuracy improvement? Consider the dispersion within classes when placing the CHP. E.g., use the 1. vectors_of_median, vom, to represent each class, not the meanmV, where vomV ≡(median{v1|vV}, 2. mom_std, vom_std methods: project each class on d-line; then calculate std (one horizontal formula per class using Md's method); then use the std ratio to place CHP (No longer at the midpoint between mr and mv median{v2|vV}, ...) dim 2 Note:training (finding a and d) is a one-time process. If we don’t have training pTrees, we can use horizontal data for a,d (one time) then apply the formula to test data (as pTrees) r r vv r mR r v v v r r v mV v r v v r v dim 1
static void ObliqueFunction(int X[][DTS_LEN],int D[],int a,PTree &mask){ unsigned long int len, att_num, bit_num; int i,j,k; att_num = ATT_NUM; len = DTS_LEN; bit_num = BIT_NUM; PTreeSet x,r,s,t; PTree dmy(len); dmy.clearall(); for (i=0;i<bit_num;i++) x.add(dmy); for (i=0;i<2*bit_num+att_num+1;i++){ r.add(dmy); s.add(dmy); t.add(dmy); } for (k=0 ; k<att_num; k++){ /* Convert Attr X[k] to pTree and store in pTree set x*/ for ( i = 0; i < len; i++ ) { unsigned int bit = 1; Md: My implementation of Oblique Faust. I have used the LandSat data from UCI repository. We have taken four attributes from that data set namely Red band, Green band, Infrared 1 and infra red 2. It has six classes (1,2,3,4,5 and 7 No 6). In my implementation is in FaustObliqueLanSat.C file where I am using Dr. Wettstein's PTree.H, PTreeSet.H and my PTreeOp.H header files. Four attributes are sliced into the R.txt, G.txt, IR1.txt and IR2.txt files. There are two data files - the training and test. The class means (mn's), direction vectors (D's) and cutpoints (a's) are calculated from training data. When the ObliqueFunction function is called it takes the data points, the D's and a's and returns a mask pTree. If mean 1 and 2 are used, D12 and a12 are given the mask pTree contains 0 for class 1 and 1 for class 2 and could be 1 or 0 (X) for others //fprintf(stdout,"Converting Value %d\n",X[k][i]); for ( j = 0; j < bit_num; j++ ) { if ( bit & X[k][i] ) x[j].setbit(i); else x[j].clearbit(i); bit <<= 1; } } /* Show attributes in decimal values */ /*if (k==0){fprintf(stdout,"Attribute %d\n",k+1); ToValue(x,bit_num,len,false);}*/ /* Multiply this attribute by D[k] */ for (i=0;i<2*bit_num+att_num+1;i++){ r[i].clearall(); //reset r} if (D[k]<0){ MultiplyByValue(r,x,-D[k],bit_num,bit_num); Make2sComplement(r,r,2*bit_num+att_num,len);} else{ MultiplyByValue(r,x,D[k],bit_num,bit_num); } /* Show Attributes multiplied by D's in decimal vals */ /*fprintf(stdout,"Multiplied by %d\n",D[k]); ToValue(r,2*bit_num+1,len,true);*/ /* Add r with s */ AddPTrees(t,s,r,(2*bit_num+att_num),len); for (i=0;i<2*bit_num+att_num;i++) s[i]=t[i]; /* Show attributes in decimal values */ /*fprintf(stdout,"Added w sum\n"); ToValue(s,2*bit_num+att_num,len,true);*/ } int a_back; a_back = a; if (a<0){ Make2sComplement(s,s,2*bit_num+att_num,len); a = -a; } FAUST OBLIQUE LANDSAT.C #include "PTree.H" #include "PTreeSet.H" #include "PTreeOp.H" #include <math.h> #define BIT_NUM 8 #define ATT_NUM 4 #define DTS_LEN 2000 #define TRN_LEN 10 int readfile(int A[], int n, char *fname){FILE *fp; if((fp=fopen(fname,"rt"))==NULL){fprintf(stderr, "File open error %s\n",fname); return -1;} for(int i=0;i<n;i++)fscanf(fp,"%d",&A[i]);return 1;} static void ToValue(PTreeSet &p,int bit,int len,bool sign) {int i,j,w,v; w=bit-1; for(i=0;i<len;i++) {v=0; for(j=0;j<w;j++){if(p[j].is_set(i)){v+=pow(2,j);} }if(p[w].is_set(i)) {if (sign) v=-1*(pow(2,w)-v);else v+=pow(2,w);} fprintf(stdout,"%d ",v); }fprintf(stdout,"\n"); }
FAUST OBLIQUE LANDSAT.C (2) GreaterThanValue(mask,s,a,(2*bit_num+att_num)); mask = mask & (~s[2*bit_num + att_num -1]); if (a_back>=0) mask = ~mask; //fprintf(stdout,"\n#of pTrees in s: %d\n",s.size()); } extern int main(int argc, char *argv[]); int main(int argc, char **argv) { /* Dataset having three attributes */ char DataSetName[ATT_NUM][30] = {"LanSat/R.txt","LanSat/G.txt","LanSat/IR1.txt","LanSat/IR2.txt"}; int A[ATT_NUM][DTS_LEN]; int Class[DTS_LEN]; int i,j; for (i=0;i<ATT_NUM;i++){readfile(A[i],DTS_LEN,DataSetName[i]);} /* PTree objects */ PTree m12(DTS_LEN),m13(DTS_LEN),m14(DTS_LEN),m15(DTS_LEN),m17(DTS_LEN), m23(DTS_LEN),m24(DTS_LEN),m25(DTS_LEN),m27(DTS_LEN), m34(DTS_LEN),m35(DTS_LEN),m37(DTS_LEN), m45(DTS_LEN),m47(DTS_LEN), m57(DTS_LEN), m1(DTS_LEN),m2(DTS_LEN),m3(DTS_LEN),m4(DTS_LEN), m5(DTS_LEN),m7(DTS_LEN), cl1(DTS_LEN),cl2(DTS_LEN),cl3(DTS_LEN),cl4(DTS_LEN), cl5(DTS_LEN),cl7(DTS_LEN); /* Calculation of D */ int mC1[ATT_NUM]={63, 95, 108, 89}, mC2[ATT_NUM]={49, 40, 114,118}, mC3[ATT_NUM]={87,105, 111, 87},mC4[ATT_NUM]={77, 91, 96, 75}, mC5[ATT_NUM]={60, 62, 83, 70},mC7[ATT_NUM]={69, 77, 82, 64}; int d12[ATT_NUM],d13[ATT_NUM],d14[ATT_NUM],d15[ATT_NUM],d17[ATT_NUM], d23[ATT_NUM],d24[ATT_NUM],d25[ATT_NUM],d27[ATT_NUM], d34[ATT_NUM],d35[ATT_NUM],d37[ATT_NUM], d45[ATT_NUM],d47[ATT_NUM], d57[ATT_NUM]; int sum; int a12=0,a13=0,a14=0,a15=0,a17=0, a23=0,a24=0,a25=0,a27=0, a34=0,a35=0,a37=0, a45=0,a47=0, a57=0; double mn,dd=0.0; for(i=0;i<ATT_NUM;i++){ d12[i] = mC1[i] -mC2[i]; d13[i] = mC1[i] -mC3[i]; d14[i] = mC1[i] -mC4[i]; d15[i] = mC1[i] -mC5[i]; d17[i] = mC1[i] -mC7[i]; d23[i] = mC2[i] -mC3[i]; d24[i] = mC2[i] -mC4[i]; d25[i] = mC2[i] -mC5[i]; d27[i] = mC2[i] -mC7[i]; d34[i] = mC3[i] -mC4[i]; d35[i] = mC3[i] -mC5[i]; d37[i] = mC3[i] -mC7[i]; d45[i] = mC4[i] -mC5[i]; d47[i] = mC4[i] -mC7[i]; d57[i] = mC5[i] -mC7[i]; } /* Calculation of a */ for(i=0;i<ATT_NUM;i++){ a12+=(mC1[i]+mC2[i])*d12[i];a13+=(mC1[i]+mC3[i])*d13[i]; a14+=(mC1[i]+mC4[i])*d14[i];a15+=(mC1[i]+mC5[i])*d15[i]; a17+=(mC1[i]+mC7[i])*d17[i];a23+=(mC2[i]+mC3[i])*d23[i]; a24+=(mC2[i]+mC4[i])*d24[i];a25+=(mC2[i]+mC5[i])*d25[i]; a27+=(mC2[i]+mC7[i])*d27[i];a34+=(mC3[i]+mC4[i])*d34[i]; a35+=(mC3[i]+mC5[i])*d35[i];a37+=(mC3[i]+mC7[i])*d37[i]; a45+=(mC4[i]+mC5[i])*d45[i];a47+=(mC4[i]+mC7[i])*d47[i]; a57+=(mC5[i]+mC7[i])*d57[i];} a12 /=2; a13 /=2; a14 /=2; a15 /=2; a17 /=2; a23 /=2; a24 /=2; a25 /=2; a27 /=2; a34 /=2; a35 /=2; a37 /=2; a45 /=2; a47 /=2; a57 /=2; /*Pnt val*/fprintf(stdout,"Faust Oblique Classification\n"); /* fprintf(stdout,"Mean value of Class 1: "); for (i=0;i<ATT_NUM;i++) fprintf(stdout,"%d ",mC1[i]); fprintf(stdout,"\nMean value of Class 2: "); for (i=0;i<ATT_NUM;i++) fprintf(stdout,"%d ",mC2[i]); fprintf(stdout,"\nMean value of Class 3: "); for (i=0;i<ATT_NUM;i++) fprintf(stdout,"%d ",mC3[i]); fprintf(stdout,"\nMean value of Class 4: "); for (i=0;i<ATT_NUM;i++) fprintf(stdout,"%d ",mC4[i]); fprintf(stdout,"\nMean value of Class 5: "); for (i=0;i<ATT_NUM;i++) fprintf(stdout,"%d ",mC5[i]); fprintf(stdout,"\nMean value of Class 7: "); /*for(i=0;i<ATT_NUM;i++){sum=0;for(j=0;j<TRN_LEN;j++) {sum+=C1[i][j];} mn=(double) sum/TRN_LEN; mC1[i]=(int) mn;sum=0;for(j=0;j<TRN_LEN;j++){sum+=C2[i][j];} mC2[i]=sum/TRN_LEN;sum=0;for(j=0;j<TRN_LEN;j++){sum+=C3[i][j];} mC3[i]=sum/TRN_LEN; //mn-=(double) sum/TRN_LEN;}*/
FAUST OBLIQUE LANDSAT.C (3) for(i=0;i<ATT_NUM;i++)fprintf(stdout,"%d ",mC7[i]);fprintf(stdout,"\nDirection Vector D12: "); for(i=0;i<ATT_NUM;i++)fprintf(stdout,"%d ",d12[i]);fprintf(stdout,"\nValue of a12=%d \n",a12);fprintf(stdout,"\nDir Vector D13: "); for(i=0;i<ATT_NUM;i++)fprintf(stdout,"%d ",d13[i]);fprintf(stdout,"\nValue of a13=%d \n",a13);fprintf(stdout,"\nDir Vector D14: "); for(i=0;i<ATT_NUM;i++)fprintf(stdout,"%d ",d14[i]);fprintf(stdout,"\nValue of a14=%d \n",a14);fprintf(stdout,"\nDir Vector D15: "); for(i=0;i<ATT_NUM;i++)fprintf(stdout,"%d ",d15[i]);fprintf(stdout,"\nValue of a15=%d \n",a15);fprintf(stdout,"\nDir Vector D17: "); for(i=0;i<ATT_NUM;i++)fprintf(stdout,"%d ",d17[i]);fprintf(stdout,"\nValue of a17=%d \n",a17);fprintf(stdout,"\nDir Vector D23: "); for(i=0;i<ATT_NUM;i++)fprintf(stdout,"%d ",d23[i]);fprintf(stdout,"\nValue of a23=%d \n",a23);fprintf(stdout,"\nDir Vector D24: "); for(i=0;i<ATT_NUM;i++)fprintf(stdout,"%d ",d24[i]);fprintf(stdout,"\nValue of a24=%d \n",a24);fprintf(stdout,"\nDir Vector D25: "); for(i=0;i<ATT_NUM;i++)fprintf(stdout,"%d ",d25[i]);fprintf(stdout,"\nValue of a25=%d \n",a25);fprintf(stdout,"\nDir Vector D27: "); for(i=0;i<ATT_NUM;i++)fprintf(stdout,"%d ",d27[i]);fprintf(stdout,"\nValue of a27=%d \n",a27);fprintf(stdout,"\nDir Vector D34: "); for(i=0;i<ATT_NUM;i++)fprintf(stdout,"%d ",d34[i]);fprintf(stdout,"\nValue of a34=%d \n",a34);fprintf(stdout,"\nDir Vector D35: "); for(i=0;i<ATT_NUM;i++)fprintf(stdout,"%d ",d35[i]);fprintf(stdout,"\nValue of a35=%d \n",a35);fprintf(stdout,"\nDir Vector D37: "); for(i=0;i<ATT_NUM;i++)fprintf(stdout,"%d ",d37[i]);fprintf(stdout,"\nValue of a37=%d \n",a37);fprintf(stdout,"\nDir Vector D45: "); for(i=0;i<ATT_NUM;i++)fprintf(stdout,"%d ",d45[i]);fprintf(stdout,"\nValue of a45=%d \n",a45);fprintf(stdout,"\nDir Vector D47: "); for(i=0;i<ATT_NUM;i++)fprintf(stdout,"%d ",d47[i]);fprintf(stdout,"\nValue of a47=%d \n",a47);fprintf(stdout,"\nDir Vector D57: "); for(i=0;i<ATT_NUM;i++)fprintf(stdout,"%d ",d57[i]);fprintf(stdout,"\nValue of a57=%d \n",a57); */ /* call the oblique functions */ ObliqueFunction(A,d12,a12,m12);//m12=0C1m12=1C2000111xxx ObliqueFunction(A,d13,a13,m13);//m13=0C1m13=1C3000xxx111 ObliqueFunction(A,d14,a14,m14);//m14=0C1m12=1C2000111xxx ObliqueFunction(A,d15,a15,m15);//m15=0C1m13=1C3000xxx111 ObliqueFunction(A,d17,a17,m17);//m17=0C1m13=1C3000xxx111 ObliqueFunction(A,d23,a23,m23);//m13=0C1m13=1C3000xxx111 ObliqueFunction(A,d24,a24,m24);//m12=0C1m12=1C2000111xxx ObliqueFunction(A,d25,a25,m25);//m13=0C1m13=1C3000xxx111 ObliqueFunction(A,d27,a27,m27);//m13=0C1m13=1C3000xxx111 ObliqueFunction(A,d34,a34,m34);//m12=0C1m12=1C2000111xxx ObliqueFunction(A,d35,a35,m35);//m13=0C1m13=1C3000xxx111 ObliqueFunction(A,d37,a37,m37);//m13=0C1m13=1C3000xxx111 ObliqueFunction(A,d45,a45,m45);//m13=0C1m13=1C3000xxx111 ObliqueFunction(A,d47,a47,m47);//m13=0C1m13=1C3000xxx111 ObliqueFunction(A,d57,a57,m57);//m13=0C1m13=1C3000xxx111 fprintf(stdout,"\nm12:\n");m12.dump(stdout);fprintf(stdout,"\nm13:\n");m13.dump(stdout);fprintf(stdout,"\nm14:\n");m14.dump(stdout); fprintf(stdout,"\nm15:\n");m15.dump(stdout);fprintf(stdout,"\nm17:\n");m17.dump(stdout);fprintf(stdout,"\nm23:\n");m23.dump(stdout); m1=(~(m12))&(~(m13))&(~(m14))&(~(m15))&(~(m17)); m2=(m12)&(~(m23))&(~(m24))&(~(m25))&(~(m27)); m3=(m13)&(m23)&(~(m34))&(~(m35))&(~(m37)); m4=(m14)&(m24)&(m34)&(~(m45))&(~(m47)); m5=(m15)&(m25)&(m35)&(m45)&(~(m57)); m7=(m17)&(m27)&(m37)&(m47)&(m57); //m1.dump(stdout); PTreeSet p; PTree dmm(DTS_LEN),t1(DTS_LEN),t2(DTS_LEN), t3(DTS_LEN); dmm.clearall(); for(i=0;i<3;i++) p.add(dmm); readfile(Class,DTS_LEN,"LanSat/Class.txt"); for(i=0;i<DTS_LEN;i++){unsigned int bit=1; for(j=0; j<3; j++){if(bit&Class[i]) p[j].setbit(i); else p[j].clearbit(i); bit <<= 1;}} cl1=(~(p[2]))&(~(p[1]))&((p[0]))&m1; cl2=(~(p[2]))&((p[1]))&(~(p[0]))&m2; cl3=(~(p[2]))&( (p[1]))&((p[0]))&m3; cl4=((p[2]))&(~(p[1]))&(~(p[0]))&m4; cl5=( p[2]))&(~(p[1]))&((p[0]))&m5; cl7=( (p[2]))&((p[1]))&((p[0]))& m7; //fprintf(stdout,"\nm13 we got: \n"); m13.dump(stdout); fprintf(stdout,"\nOne of the Accurate m13: \n"); cl2.dump(stdout); /* t1=cl1|cl2; t2=~(m13^cl2); t3=t1& t2; */ float acc=0.0; int tp=cl1.count()+cl2.count()+cl3.count()+cl4.count()+ cl5.count()+cl7.count(); //int tp = t3.count(); fprintf(stdout,"\nNumber True Positive in = %ld\n", tp); acc = (float) tp / DTS_LEN; fprintf(stdout,"\nClassification Accuracy = %f\n", acc); fprintf(stdout,"\nNumber of True Pos in Class 1 = %ld\n", cl1.count()); fprintf(stdout,"\nNumTruePosinClass2 = %ld\n", cl2.count()); fprintf(stdout,"\nNumTruePosinCls3= %ld\n", cl3.count()); fprintf(stdout,"\nNumTruePosinCls4= %ld\n", cl4.count()); fprintf(stdout,"\nNumTruePosinCls5= %ld\n", cl5.count()); fprintf(stdout,"\nNumTruePosinCls7= %ld\n", cl7.count()); return(0); } FAUST OBLIQUE LANDSAT.C end
PTreeOp.H #include "PTree.H" #include "PTreeSet.H" #define N 5 PTreeSet inq,outq; int pin=0,pout=0; void pushin(PTree &p){inq[pin]=p;pin++;return;} void popout(PTree &p){pout--;p=outq[pout];return;} void swapq(void){int i;for(i=0;i<pin;i++){outq[i]=inq[i];}pout=pin;pin=0;} static void MultiplyByValue(PTreeSet &s,PTreeSet &p,int v,int n,int m){//r=v*p /*fctn mults ptree_arrays p (#ptrees=n) by v (#bits_v=m)m+n ptrees stored in s array ptrees*/ int i,j,k,x[50],y; PTree t1,sum,carry,dmy; pin=0; pout=0; //Convert v into bits y=v; for (j=0;j<m; j++){ x[j] = y%2; y/=2; } //return; dmy.clearall(); for(i=0;i<100;i++){inq.add(dmy);outq.add(dmy);} for(i=0;i<m+n;i++) {if(pout!=0){popout(t1);s[i]=t1;}else{t1.setall();s[i].clearall();} //s[i] = t1;s[i].clearall();return; while(pout>0){popout(t1);sum=s[i]^t1;carry=s[i]&t1;s[i]=sum;pushin(carry);} for(j=0;(j<m)&&(j<=i);j++){k=i-j;if(k>n-1)continue; if(x[j]!=0){sum=s[i]^p[k];carry=s[i]&p[k];s[i]=sum;pushin(carry);} }swapq(); }return; } static void AddPTrees(PTreeSet &ss,PTreeSet &aa,PTreeSet &bb,int end,int len) { PTree sum(len),carry(len),t1(len),t2(len);int i;ss[0]=aa[0]^bb[0];carry=aa[0]&bb[0]; for (i=1;i<end;i++){sum=aa[i]^bb[i]; t1=aa[i]&bb[i];ss[i]=sum^carry;t2=sum&carry;carry=t1|t2;} ss[end]=carry; } static void Make2sComplement(PTreeSet &a, PTreeSet &bb,int n, int len) { /*a=2sComp(b)*/ int i;PTree s(len),c(len),t(len);PTreeSet b; //b=bb; 1's complement t.clearall(); for(i=0;i<n;i++){b.add(t); b[i]=~bb[i];} /*+1 for 2s comp*/ a[0]=~b[0];c=b[0]; for(i=1;i<n;i++){a[i]=b[i]^c;c=b[i]&c;} } static void GreaterThanValue(PTree &mask,PTreeSet &p,int value,int nn){//P(A>v), mask=1 p>val int i,x,r;x=value; i=0; do {r=x%2; x/=2;i++;}while (r!=0); mask = p[i-1]; while (i<nn){r=x%2; if(r==1){mask=mask&p[i];}else{mask=mask|p[i];}x/=2;i++;} }
PTree.C #include <stdio.h> #include <stdint.h> #include <stdlib.h> #include <time.h> #include <netinet/in.h> #include "PTree.H" /* Variables static to this module. */ const char * const ascii_header="# ASCII PTree v1.0"; static size_t _base,_offset; /* Private fctn impl conv of bit# to base and value offset in tree. Validity check verifies specified * bit is within context of tree. Fctn updates _base _offset vars to this methods class. * \param bit #bit whose location is to be determined. \param bitcnt #bits in the tree. * \return Boolean val indicates whether offset calculation is valid.*/ static bool _get_position(unsigned long long int bit,unsigned long long int bitcnt, unsigned int bits_per_word) {if (bit>(bitcnt-1))return false;_ base=bit/bits_per_word; _offset=bit % bits_per_word; return true; } /*Private fctn impl counting #bits in word. Used by ct,load,op meths to set onecnt * of the object during any of the method calls.*/ static inline int _count_word(size_t *word) { auto int bitcnt=0; auto uint8_t *byte_ptr=(uint8_t *) word; /*Array impl tbl for 8bit wide lookup based counting.*/ static int lookup[256]= { \ 0,1,1,2,1,2,2,3,1,2,2,3,2,3,3,4,1,2,2,3,2,3,3,4,2,3,3,4,3,4,4,5, 1,2,2,3,2,3,3,4,2,3,3,4,3,4,4,5,2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6, 1,2,2,3,2,3,3,4,2,3,3,4,3,4,4,5,2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6, 2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6,3,4,4,5,4,5,5,6,4,5,5,6,5,6,6,7, 1,2,2,3,2,3,3,4,2,3,3,4,3,4,4,5,2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6, 2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6,3,4,4,5,4,5,5,6,4,5,5,6,5,6,6,7, 2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6,3,4,4,5,4,5,5,6,4,5,5,6,5,6,6,7, 3,4,4,5,4,5,5,6,4,5,5,6,5,6,6,7,4,5,5,6,5,6,6,7,5,6,6,7,6,7,7,8}; for(size_t byte=0;byte<sizeof(size_t);++byte) {bitcnt+=lookup[*byte_ptr];++byte_ptr;}return bitcnt;} /*Priv fctn impl ctg #1bits in wd. \param word ptr to wd ctd. \return 1bits in wd*/ static inline int _count_sparse_word(size_t *word) {auto int setbit,bitcnt=0; auto size_t tword=*word; /*Wd cntg lp. If wordNot=0 >1bit set so bitct impld. 1st used to create mask to clear wd*/ while(tword!=0){++bitcnt; setbit=__builtin_ffsl(tword)-1;tword&=~(1UL<<setbit);}return bitcnt; } /*Private method computes relevant sizes for PTree. False val returned errors*/ bool PTree::_init(unsigned long long int bits) { bits_per_word=sizeof(size_t)*CHAR_BIT;if((bits==0)||(bits>(bits_per_word*MAXINT))) return false;
PTree.C continued (2) /* et number of bits represented and word count*/ bitcnt=bits; wordcnt=bits/bits_per_word; if((bitcnt % bits_per_word)!=0)++wordcnt; /* alloc done thru posix_memalign to align mem on 16byte bddy to opt XMM register load.*/ if((tree=(size_t *) malloc(sizeof(size_t)*wordcnt))==NULL) {printf("Memory allocation failed.\n");return false;} memset(tree,'\0',wordcnt*sizeof(size_t));return true; } /* No argument constructor.*/ PTree::PTree(void) { tree=NULL; index_list=NULL; reset(); return; } /* Copy constructor.*/ PTree::PTree(const PTree &incoming){if(!_init(incoming.bitcnt)) return; index_list=NULL; memcpy(tree, incoming.tree, wordcnt*sizeof(size_t)); count(); loaded=true; return;} /* Single arg construct used to init in-memory PTree. Fctn arg is #bits supported tree. 64bit int used even * 2-bit machines - #bits manageable is > physical word size of machine.*/ PTree::PTree(unsigned long long int bits){tree=NULL;index_list=NULL;reset(); loaded=_init(bits);return;} /* Operator: assignment implements a deep copy of an object for assignment purposes.*/ const PTree & PTree::operator= (const PTree &incoming) { if(&incoming==this) return*this; if(bitcnt!=incoming.bitcnt){reset(); if(!_init(incoming.bitcnt)) return *this;} memcpy(tree,incoming.tree,wordcnt*sizeof(size_t)); onecnt=incoming.onecnt;loaded=true;return *this; } /* Operator: AND method impl ANDing an incoming PTree with the current PTree.*/ PTree PTree::operator& (const PTree &incoming) { auto size_t word=0; auto PTree tmp(incoming.bitcnt); while(word<wordcnt){ tmp.tree[word]=this->tree[word]&incoming.tree[word];++word;} tmp.count(); return tmp; } /* Operator: XOR impl XOR incoming PTree with current PTree.*/ PTree PTree::operator^ (const PTree &incoming) { auto size_t word=0; auto PTree tmp(incoming.bitcnt); while(word<wordcnt){tmp.tree[word]=this->tree[word]^incoming.tree[word];++word;} tmp.count(); return tmp; } /* Operator: OR impl OR incoming PTree with current PTree.*/ PTree PTree::operator| (const PTree &incoming) { auto size_t word=0; auto PTree tmp(incoming.bitcnt); while(word<wordcnt){tmp.tree[word]=this->tree[word]|incoming.tree[word];++word;} tmp.count(); return tmp; }
PTree.C continued (3) /* Op: EQUIV checks eq: Eq bits each tree. Same 1cts 2 trees. 1cts equiv pos in 2 trees*/ bool PTree::operator==(const PTree &incoming) {if(bitcnt!=incoming.bitcnt) return false; if(onecnt!=incoming.onecnt) return false; for(size_t word=0;word<wordcnt;++word)if(tree[word]!=incoming.tree[word])return false; return true;} /*Op:NEGATION gens inv incoming PTree. Each cleared bit pos gens 1bit and vice-versa*/ PTree PTree::operator~ () { auto size_t words,residual_bits; auto unsigned long long int bitpos; auto PTree tmp(this->bitcnt); /* Since ope on full-int wds, can only do neg on full wds. After, brute force*/ words=wordcnt; residual_bits=bitcnt % bits_per_word; if(residual_bits!=0) --words; for(size_t word=0;word<words;++word) {tmp.tree[word]=~tree[word];tmp.onecnt+= count_word(&tmp.tree[word]);} if(residual_bits==0) return tmp; bitpos=(wordcnt-1)* bits_per_word; for(size_t bit=0;bit<residual_bits;++bit){ if(is_set(bitpos))tmp.clearbit(bitpos); else tmp.setbit(bitpos); ++bitpos; } return tmp; } /* Destr fctn wrapper for reset call. sets private vars to 0, frees mem for data tree.*/ PTree::~PTree(void) {reset(); return;} /* Pub impl ret bitpos set. \param bit #bit. \return Bool ret bit=true (bit set)*/ bool PTree::is_set(unsigned long long int bit) { if(!_get_position(bit, bitcnt, bits_per_word)) return false; if(tree[_base]&(1UL<<_offset)) return true; return false; } /* method sets single bit in tree. Note that bit postions are 0 counted.*/ void PTree::setbit(unsigned long long int bit) { auto bool was_clear; if(!_get_position(bit,bitcnt,bits_per_word))return; was_clear=is_clear(bit);tree[_base]|=(1UL<<_offset); if(was_clear)++onecnt; return; } /* clears a single bit in the tree. Note that bit positions are zero counted.*/ void PTree::clearbit(unsigned long long int bit) { auto bool was_set; if(!_get_position(bit,bitcnt,bits_per_word)) return; was_set=is_set(bit); tree[_base]&=~(1UL<<_offset); if(was_set) --onecnt; return; } /* Ext pub: cts # 1bits; retained in 1ct*/ unsigned long long int PTree::count(void){onecnt=0;for(size_t word=0;word<wordcnt;++word)onecnt+=_count_word(&tree[word]);return onecnt;} /* initializes/clears the contents of the PTree represented by object.*/ void PTree::reset(void) { loaded =false; bitcnt=0; wordcnt=0; onecnt=0; if(tree!=NULL){free(tree); tree=NULL;} if(index_list!=NULL){free(index_list);index_list=NULL;}return; }
PTree.C continued (4) /*Pub:impl get index lists corres to bits set. Subs calls overwrite array. \return ptr*/ unsigned long long int *PTree::get_indexes(void) { auto int firstbit,bitbase=0;auto unsigned long long int entry=0;auto size_t tword, allocate; /* Things are simple if no bits are set. */ if(bitcnt==0)return NULL; /* Calculate array size eeded and allocate memory for array.*/ allocate=onecnt*sizeof(unsigned long long int); index_list=(unsigned long long int *)realloc(index_list,allocate); if(index_list==NULL) return NULL; /*outer lp thru wds-any bits set, reduct select strategy for list elts wd.*/ for (size_t word=0; word<wordcnt;++word) { tword=tree[word]; while(tword!=0) { firstbit=__builtin_ffsl(tword)-1;index_list[entry++]=bitbase+firstbit; tword&=~(1UL<<firstbit);}if(entry==onecnt)return index_list; bitbase+=bits_per_word; } return index_list; } /* method loads ASCII rep of PTree into current object.*/ bool PTree::load(FILE *input) { auto char *p,bufr[80]; auto unsigned long long int bits; /* Read 1st line and verify a PTree ASCII header.*/ if(fgets(bufr, sizeof(bufr), input)==NULL ) return false; if((p = strrchr(bufr, '\n'))!=NULL) *p='\0'; if(strcmp(bufr, ascii_header) != 0) return false; /* Read the bitcnt and set up the PTree sizes. */ if(fgets(bufr,sizeof(bufr),input)==NULL) return false; if((p=strrchr(bufr,'\n'))!=NULL) *p='\0'; #if 0 bits = strtoull(bufr, NULL, 16); #else bits = strtoul(bufr, NULL, 16); #endif if ( !_init(bits) ) return false; for (size_t word=0;word<wordcnt;++word) { auto size_t value; auto unsigned int lp; tree[word]=0; for(lp=0;lp<sizeof(size_t)/sizeof(uint32_t);++lp) { if(fgets(bufr,sizeof(bufr),input)==NULL) return false; if((p=strrchr(bufr,'\n'))!=NULL)*p='\0'; value=ntohl(strtoul(bufr,NULL,16)); tree[word]|=(value<<(lp*sizeof(uint32_t)*CHAR_BIT)); } onecnt+=_count_word(&tree[word]); } loaded=true; return true; }
PTree.C continued (5) /* load bin PTree, for trans pathyway to new ASCII format files.*/ bool PTree::load_binary(FILE *input) { auto size_t bytes; auto unsigned long long int bits, blocks; /* Supps flat bin PTree read when subsequent hve no header info. #bits 1st 8B.*/ if(this->bitcnt==0){ if(fread(&bits,sizeof(unsigned long long int),1,input)!=1)return false; if(!_init(bits)) return false; if(fread(&blocks,sizeof(blocks),1,input)!=1) return false; if(sizeof(blocks)==4)blocks*=2; } bytes=bitcnt/CHAR_BIT; if((bitcnt % CHAR_BIT)!=0)++bytes;while((bytes % sizeof(blocks))!=0)++bytes; if(fread(tree,sizeof(char),bytes,input)!=bytes){reset();return false;} count(); loaded=true; return true; } /* method saves ASCII rep of PTree.*/ bool PTree::save(FILE *outfile) { if(!loaded) return false; /* Output file header then bitcount. */ fprintf(outfile,"%s\n",ascii_header);fprintf(outfile,"%llx\n",bitcnt); /* outpt format hex in network byte order*/ for(size_t word=0; word<wordcnt;++word) { unsigned int lp; for(lp=0;lp<(sizeof(size_t)/sizeof(uint32_t));++lp) { auto uint32_t output; output=tree[word]>>(lp*sizeof(uint32_t)*CHAR_BIT); fprintf(outfile,"%08x\n",htonl(output)); } } return true; } /* prints ASCII rep of PTree*/ void PTree::dump(FILE *output) { if(!loaded){fputs("PTree not loaded.\n", output); return;} fprintf(output,"%s: %s\n",__FILE__,__FUNCTION__); fprintf(output,"\tBit count:\t%llu\n",bitcnt); fprintf(output, "\tWord count:\t%zu\n",wordcnt); fprintf(output, "\tOne count:\t%llu\n\n",onecnt); /* Output Ptree word by word w bit pos denoted*/ auto unsigned long long int bitpos=0; for(size_t word=0;word<wordcnt;++word) { fprintf(output,"%6llu: ",bitpos); for(unsigned int bit=0;bit<bits_per_word;++bit) {if(bitpos>=bitcnt){fputs("_",output);continue;} if(tree[word]&(1UL<<bit)) fputs("1",output); else fputs("0",output); ++bitpos; } fprintf(output,": %llu\n",bitpos-1); } return; }
PTree.H #if !defined(PTREE_H) #define PTREE_H #include <stdlib.h> #include <stdio.h> #include <limits.h> #include <values.h> #include <string.h> class PTree {private: unsigned int bits_per_word;/*#bits in wd*/ bool loaded;/*Guardval:PTreeloaded?*/ unsigned long long int bitcnt;/*#bits*/ size_t wordcnt;/*#wds*/ unsigned long long int onecnt;/*1ct*/ size_t *tree;/*TreeMemPtr*/ unsigned long long int *index_list;/*indexPtr*/ bool _init(unsigned long long int);/*Priv meth calc, set sz*/ public: PTree(void);/*Void const*/ PTree(const PTree &);/*Copy const*/ PTree(unsigned long long int);/* Constr to init in-mem tree*/ ~PTree(void);/*Destr*/ const PTree & operator=(const PTree &);/*Op: assignment*/ PTree operator& (const PTree &); PTree operator| (const PTree &);/*Op: OR*/ PTree operator^ (const PTree &); bool operator==(const PTree &);/*Op:EQ*/ PTree operator~ ();/*Op:NEG*/ bool is_loaded(void) {return loaded;}/*Pub inline met check ldd*/ void clearall(void){memset(tree,'\0',sizeof(size_t)*wordcnt);onecnt=0;}/*Pub inline clear bits in tree*/ unsigned long long int size(void) {return bitcnt;};/*get PTree sz in bits*/ bool is_clear(unsigned long long int bit) {return !is_set(bit);}/*det if bit clear*/ unsigned long long int get_count(void) {return onecnt;}/*get cur bitct*/ void setall(void){for (unsigned long long int lp=0; lp<bitcnt;++lp)setbit(lp);return;}/*set all*/ bool is_set(unsigned long long int);/*chk bit set*/ void setbit(unsigned long long int);/*set single*/ oid clearbit(unsigned long long int);/*clr single*/ unsigned long long int count();/*ct/set 1bits*/ void reset();/*clr PTree contents*/ unsigned long long int * get_indexes(void);/*gt index lst set bits*/ bool load(FILE *);/*ld ASCII PTree*/ bool load_binary(FILE *);/*ld bin PTree-deprecated interface*/ bool save(FILE *);/*save ASCII PTree*/oid dump(FILE *);/*prt bin rep PTree*/ }; #endif
PTreeSet.C /* \file=impl of PTreeSet obj - stores/manipulates set of related PTrees*/ #include <stdio.h>/*Stand includes*/ #include "PTreeSet.H"/*Loc includes*/ const char * const ascii_header = "# ASCII PTreeSet v1.0";/*Vars static to mod*/ /* Priv meth. impls alloc for array of objs holding PTree. \param ptree_cnt #PTrees. \return allc?*/ bool PTreeSet::allocate_ptreeset(size_t ptree_cnt) { auto size_t allocate=sizeof(PTree **)*ptree_cnt; ptree_set=(PTree **) realloc(ptree_set,allocate);if(ptree_set==NULL )return false;return true; } /* No arg constr*/ PTreeSet::PTreeSet(void){ptree_setsize=0; ptree_set=NULL;return;}/*Cpy const*/ PTreeSet::PTreeSet(const PTreeSet &incoming){return;} /* Destr. After lp array em alloc releaed*/ PTreeSet::~PTreeSet(void) {for(size_t ptree=0; ptree<ptree_setsize;++ptree)delete ptree_set[ptree];free(ptree_set);return;} PTree & PTreeSet::operator[] (size_t element)/*Pub op: array deref: set refd via array syntax. ptr ret*/ {if(element>ptree_setsize){fputs("Element error\n",stderr);return *ptree_set[0];}return *ptree_set[element];} PTreeSet & PTreeSet::operator[][] (size_t element,size_t element1) {if(element>ptree_setsize){fputs("Element error\n",stderr);return *ptree_set[0];}return *ptree_set[element];} /* PubMeth. add PTree to set. re-alloc array \param ptree ref to PTree added. \return boolval ret*/ bool PTreeSet::add(PTree & ptree) { auto PTree *pt_ptr; if(!allocate_ptreeset(ptree_setsize+1))return false; if((pt_ptr=new PTree())==NULL)return false;*pt_ptr=ptree;ptree_set[ptree_setsize++]=pt_ptr;return true; } /* PubMeth: reads PTrees ASCII file. \param input open file desc which PTrees read from. \return*/ bool PTreeSet::load(FILE *input) { auto char *p, bufr[80]; auto size_t number_to_load=0; auto PTree *pt_ptr;/*Read/verify 1st line*/ if(fgets(bufr, sizeof(bufr),input)==NULL) return false; if((p=strrchr(bufr,'\n'))!=NULL)*p='\0'; if(strcmp(bufr,ascii_header)!=0) return false; if(fgets(bufr, sizeof(bufr),input)==NULL) return false;/*Read tree set PTree sz*/ if((p=strrchr(bufr,'\n'))!=NULL) *p='\0';number_to_load=strtoul(bufr,NULL,16); if(!allocate_ptreeset(number_to_load)) return false; /* Read remainder of input for the rest of the trees. */ do{if((pt_ptr=new PTree())==NULL)return false;ptree_set[ptree_setsize++]=pt_ptr; if(!pt_ptr->load(input))return false; if(ptree_setsize==number_to_load)return true;} while(!feof(input)); if(ptree_setsize!=number_to_load)return false;return true; }
PTreeSet.C (2) /*PubMeth. rds PTree set from bin file. \param input \return*/ bool PTreeSet::load_binary(FILE *input, size_t number_to_load) { auto unsigned long long int bitcnt; auto PTree *pt_ptr; if(!allocate_ptreeset(number_to_load))return false;/*Alloc array for PTree ptrs*/ if((pt_ptr=new PTree())==NULL)return false; ptree_set[ptree_setsize++]=pt_ptr; if(!pt_ptr->load_binary(input)) return false; if ptree_setsize==number_to_load)return true; bitcnt=pt_ptr->size(); do { if((pt_ptr=new PTree(bitcnt))==NULL)return false; ptree_set[ptree_setsize++]=pt_ptr; if(!pt_ptr->load_binary(input) )return false; if(ptree_setsize==number_to_load)return true; } while (!feof(input)); if(ptree_setsize!=number_to_load) return false; return true; } /* PubMeth reads 1 binPTree, by PTree::load_binary. Adds to current set \param input \return*/ bool PTreeSet::load_binary_file(FILE *input) { auto PTree *pt_ptr; /*Update array to hold an additional PTree*/ if(!allocate_ptreeset(ptree_setsize+1))return false;++ptree_setsize; /* Load binPTree, return status*/ if((pt_ptr=new PTree())==NULL) return false; ptree_set[ptree_setsize-1]=pt_ptr; if(!pt_ptr->load_binary(input))return false; return true; } /* PubMeth saves PTree set in ASCII by PTree::save (lps thru array PTrees). Header is output at start. * #PTrees in set incl in header to allow opt alloc. \param input \return*/ bool PTreeSet::save(FILE *output) { if(ptree_setsize==0 )return false; /*Output file header and bitcount*/ if(fprintf(output,"%s\n",ascii_header)==-1)return false; if(fprintf(output,"%zx\n",ptree_setsize)==-1)return false; /* The output format is hexadecimal in network byte order*/ for(size_t ptree=0;ptree<ptree_setsize;++ptree) if(!ptree_set[ptree]->save(output))return false;return true; } #if !defined(PTREESET_H) #define PTREESET_H /* Standard include files. Local include files. */ #include "PTree.H" class PTreeSet { private: size_t ptree_setsize; PTree **ptree_set;/*Ptr PTree array which form set*/ bool allocate_ptreeset(size_t);/*Private meth to alloc array for PTree set*/ public: PTreeSet(void); PTreeSet(const PTreeSet &); ~PTreeSet(void); PTree & operator[](size_t); size_t size(void) {return ptree_setsize;} bool add(PTree &); bool load(FILE *); bool load_binary(FILE *,size_t); bool load_binary_file(FILE *); bool save(FILE *); }; #endif
Mark S. said "Faust is fast... takes ~15 sec on the same dataset that takes over 9 hours with knn and 40 min with pTree knn. I’m ready to take on oblique, need better accuracy (still working on that with cut method ("best gap" method)." FAUST isthis manytimes faster than, Horizontal KNN2160taking 9.000 hours = 540.00 minutes = 32,400 sec. pCKNN: 160 taking .670 hours = 40.00 minutes = 2,400 sec. while Mdpt FAUST takes .004 hours = .25 minutes = 15 sec. "Doing experiments on faust to assess cutting off classification when gaps got too small (with an eye towards using knn or something from there). Results are pretty darn good… for faust this is still single gap, working on total gap (max of (min of prev and next gaps)) Here’s a new data sheet I’ve been working on focused on gov’t clients." Bill P: BestClsAttrGap-FAUST using all gaps meeting criteria (e.g., sum of 2 stds < gap width), AND all mask pTrees. Oblique FAUST is more accurate and faster. Md will send what he has and please interact with him on quadratics - he will help you with the implementation. Could get datasets for your performance analysis (with code of competitor algorithms etc.?) It would help us a lot in writing papers Work together on Oblique FAUST performance analysis using your benchmarks. You'd be co-author. My students crunch numbers... Mark S: Vendor opp: Provides data mining solutions to telecom operators for call analysis, etc - using faust in an unsupervised mode - thots on that for anomaly detection. Bill P: FAUST should be great for that.
Multi-hop Data Mining (MDM): relationship1 (Buys= B(P,I) ties table1 Category color size wt store city state country 2 2 3 3 4 4 5 5 P 2 3 0 1 0 1 1 0 1 0 0 1 0 0 0 0 1 1 4 5 ct(|pAPpAND&iCPi)>mncf ct(|pAPp) friend of any in A will buy C if any in A buy C. ct(|pAPpAND |iCPi)>mncf ct(|pAPp) Change to "friend of any in A will buy something in C if any in A buy C. pc bc lc cc pe age ht wt (People=P=an axis with descriptive features columns) to table2 (Items), which is tied by relationship2 (Friends=F(P,P) ) to table3 (also P)... Can we do interesting clustering and/or classification on one of the tables using the relationships to define "close" or to define the other notions? Find all strong, AC, AP, CI Frequent iff ct(PA)>minsup and Confident iff ct(&pAPpAND &iCPi) > minconf ct(&pAPp) Says: "A friend of all A will buy C if all A buy C." (the AND is always AND) Closures: A freq then A+ freq. AC not conf, then AC- not conf I=Items F(P,P)=Friends 0 0 0 1 0 1 0 0 0 0 0 0 0 0 1 0 B(P,I)=Buys P=People Define the NearestNeighborVoterSet of {f} using strong R-rules with F in the consequent? A correlation is a relationship. A strong cluster based on several self-relationships (but different relationships, so it's not just strong implication both ways) is a set that strongly implies itself (or strongly implies itself after several hops (or when closing a loop). Dear Amal, We looked at 2012 cup too and, yes, it would form a good testbed for social media data mining work. Ya Zhu in our Sat gp is leading on "contests" and is looking at 2012 KDD Cup as well as Heritage Provider Network Health Prize (see kaggle.com). Hoping also for a nice test bed involving the our Netflix datasets (which you and then Dr. Wettstein prepared as pTrees and all have worked on extensively - Matt and Tingda Lu...). Hoping to find (in the netflix contest related literature) a real-life social network (a social relationship between two copies of the netflix customers such as maybe, facebook friends, that we can use inconjunction with the netflix "rates" relationship between netflix customers and netflix movies. We would be able to do something with that set up (all as PTreeSet both ways).For those new to dataSURG Dr. Amal Shehan Perera is a Senior Professor in Sri Lanka and was a lead researcher in our group for many yrs. He is the architect of using GAs to win the KDD Cup in both 2002 and 2006. He gets most of the credit for those wins, as it was definitely GA work in both cases that pushed us over the top (I believe anyway). He's the best!! You would be wise to stay in touch with him. Sat, Mar 24, Amal Shehan Perera <shehan@uom.lk: Just had a peek into the slides last week and saw a request for social media data. Just wanted to point out that the 2012 KDD Cup is on social media data. I haven't had a chance to explore data yet. If I do I will update you. Rgds,-amal
1 0 0 0 1 0 0 bpp 1 2 3 4 5 ... 3B 0 1 1 0 0 1 1 0 0 0 0 0 0 0 1 0 0 0 1 0 0 1 1 2 2 0 0 1 0 0 0 1 3 3 1 0 0 0 1 0 0 4 4 0 0 1 0 0 0 0 5 5 AHG(P,bpp) ... ... 7B 7B P P gene chromosome bpp 1 2 3 4 5 ... 3B pc bc lc cc pe age ht wt 1 0 0 0 1 0 0 0 1 1 0 0 1 1 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 0 0 0 1 1 0 0 0 1 0 0 0 0 1 0 0 0 0 AHG(P,bpp) Bioinformatics Data Mining: Most bioinformatics done so far is not really data mining but is more toward the database querying side. (e.g., a BLAST search). What would be real Bioinformatics Data Mining (BDM)? A radical approach View whole Human Genome as 4 binary relationships between People and base-pair-positions (ordered by chromosome first, then gene region?). AHG is the relationship between People and adenine (A) (1/0 for yes/no) THG is the relationship between People and thymine (T) (1/0 for yes/no) GHG is the relationship between People and guanine (G) (1/0 for yes/no) CHG is the relationship between People and cytosine (C) (1/0 for yes/no) Order bpp? By chromosome and by gene or region (level2 is chromosome, level1 is gene within chromosome.) Do it to facilitate cross-organism bioinformatics data mining? This is a comprehensive view of the human genome (plus other genomes). Create both a People-PTreeSet and PTreeSet vertical human genome DB with a human health records feature table associated with the people entity. Then use that as a training set for both classification and multi-hop ARM. A challenge would be to use some comprehensive decomposition (ordering of bpps) so that cross species genomic data mining would be facilitated. On the other hand, if we have separate PTreeSets for each chrmomsome (or even each regioin - gene, intron exon...) then we can may be able to dataming horizontally across the all of these vertical pTree databases. The red person features used to define classes. AHGp pTrees for data mining. We can look for similarity (near neighbors) in a particular chromosome, a particular gene sequence, of overall or anything else.
APPENDIX: Facebook-Buys: A facebook Member, m, purchases Item, x, tells all friends. Let's make everyone a friend of him/her self. Each friend responds back with the Items, y, she/he bought and liked. I≡Items I≡Items I≡Items F≡Friends(M,M) Members F≡Friends(K,B) F≡Friends(K,B) Buddies Buddies 1 0 1 1 4 1 1 0 0 1 1 1 1 4 4 0 1 0 0 3 0 0 1 1 0 0 0 0 3 3 1 0 0 1 2 1 1 0 0 0 0 1 1 2 2 0 0 1 0 1 0 0 0 0 1 1 0 0 1 1 P≡Purchase(M,I) P≡Purchase(B,I) P≡Purchase(B,I) Kiddos Kiddos 2 4 4 4 2 2 3 3 3 3 3 3 2 2 4 4 2 4 1 5 5 5 1 1 Members Groupies Groupies 4 4 1 1 0 0 1 1 1 1 4 4 1 2 4 2 2 2 4 1 3 3 0 0 1 1 0 0 0 0 3 3 2 2 1 1 0 0 0 0 1 1 2 2 0 0 1 1 0 1 0 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 0 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 0 0 0 0 0 1 1 1 4 4 4 3 3 3 2 2 2 1 1 1 4 4 4 0 0 0 0 1 1 0 0 1 1 1 0 0 0 0 0 0 0 Others(G,K) Compatriots (G,K) 1 1 1 1 1 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 2 2 2 1 0 0 0 1 1 0 0 Kx=OR Ogx frequent if Kx large (tractable- one x at a time and OR. gORbPxFb XI MX≡&xXPx People that purchased everything in X. FX≡ORmMXFb = Friends of a MX person. So, X={x}, is Mx Purchases x strong" Mx=ORmPxFmx frequent if Mx large. This is a tractable calculation. Take one x at a time and do the OR. K2 = {1,2,4} P2 = {2,4} ct(K2) = 3 ct(K2&P2)/ct(K2) = 2/3 Mx=ORmPxFmx confident if Mx large. ct( Mx Px ) / ct(Mx) > minconf To mine X, start with X={x}. If not confident then no superset is. Closure: X={x.y} for x and y forming confident rules themselves.... ct(ORmPxFm & Px)/ct(ORmPxFm)>mncnf Fcbk buddy, b, purchases x, tells friends. Friend tells all friends. Strong purchase poss? Intersect rather than union (AND rather than OR). Ad to friends of friends K2={2,4} P2={2,4} ct(K2) = 2 ct(K2&P2)/ct(K2) = 2/2 K2={1,2,3,4} P2={2,4} ct(K2) = 4 ct(K2&P2)/ct(K2)=2/4
Multi-level pTrees for data tables: n-row table, row predicate (e.g., a bit slice pred, or a category map) and row ordering (e.g., asc on key; spatial data, col/row-raster, Z=Peano, Hilbert), sequence of pred truth bits (1/0) is raw or level-0predicate map (pMap) for table, pred, row order. gte75% str=5 pMC=red 0 0 1 gte50% str=5 pMC=red 0 0 1 pure1 str=5 pMC=red 0 0 0 gte25% str=5 pMC=red 1 1 1 0 1 1 1 0 1 0 1 0 0 level-2 gte50% stride=2 1 1 pMgte50%,s=4,SL,0 0 1 1 1 level-1 gt50 stride=4 pMap level-1 gt50 stride=2 pMap IRIS Table NameSLSWPLPWColor setosa 38 38 14 2 red setosa 50 38 15 2 blue setosa 50 34 16 2 red setosa 48 42 15 2 white setosa 50 34 12 2 blue versicolor 51 24 45 15 red versicolor 56 30 45 14 red versicolor 57 28 32 14 white versicolor 54 26 45 13 blue versicolor 57 30 42 12 white virginica 73 29 58 17 white virginica 64 26 51 22 red virginica 72 28 49 16 blue virginica 74 30 48 22 red virginica 67 26 50 19 red pred: rem(div(SL/2)/2)=1 order: given order gte50% stride=5 pMSL,1 1 0 0 pure1 str=5 pMSL,1 0 0 0 gte25% str=5 pMSL,1 1 1 1 gte75% str=5 pMSL,1 1 0 0 pMSL,0 0 0 0 0 0 1 0 1 1 1 1 0 0 0 1 pMColor=red 1 0 1 0 0 1 1 0 0 0 0 1 0 1 1 pMSL,1 1 1 1 0 1 1 0 0 1 0 0 0 0 1 1 predicate: remainder(SL/2)=1 order: the given table order pred: Color='red' order: given ord Raw pMap, pM, decomp to mutual excl, coll exh bit ints, bit-inte-pred, bip (e.g., pure1, pure0, gte50%One), bip stride=m level-1 pMap of pM is the string of bip truths gened by bip to consec ints of decomp. Decomp equiwidth, int seq is fully determined by width=m>1, AKA, stride=m gte50% stride=5 pMPW<7 1 0 0 pred: PW<7 order: given gte50% st=5 pMap predicts setosa. pMgte50%,s=4,SL,0≡ gte50% stride=4 pMSL,0 0 1 1 1 gte50% stride=8 pMSL,0 0 1 gte50% stride=4 pMSL,0 0 1 1 1 rem(SL/2)=1 ord: given pred: rem(SL/2)=1 ord: given order pM all its lev1 pMaps=pTree of same name as pM pMPW<7 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 pMSL,0 0 0 0 0 0 1 0 1 1 1 1 0 0 0 1 1 pMSL,0 0 0 0 0 0 1 0 1 1 1 1 0 0 0 1 1 gte50%; es=4,8,16; SL,0 pTree: R11 1 0 0 0 1 0 1 1 pTgte50%_s=4,8,16_SL,0 lev2 pMap= lev1 pMap on a lev1. (1col tbl) raw level-0 pMap gte50_pTrees11 1 gte50% stride=16 pMSL,0 0
gte50 Satlog-Landsat stride=64, classes: redsoil cotton greysoil dampgreysoil stubble verydampgreysoil R G ir1 ir2 class WL band 1 [w1,w2) w1 w1 2 w2 w2 [w2,w3) ... [w3,w4) ... ... 4436 [w4,w5) w5000 w5000 WLs WLs pixels WLs 21 43 110 160 3 18 21 21 21 21 43 43 43 43 110 110 110 110 0 0 0 0 0 0 2 1 1 1 1 1 ... ... ... ... ... ... 255 255 255 255 255 255 202 14 0 160 160 160 160 3 3 3 3 18 18 18 18 r r r r c c c c g g g g d d d d s s s s v v v v 29 152 230 cl cl cl cl 202 202 202 202 14 14 14 14 0 0 0 0 1 1 1 1 0 0 0 0 0 0 0 0 10 0 0 10 0 0 0 0 1 10 10 0 10 0 0 0 0 0 1 29 29 29 29 152 152 152 152 230 230 230 230 0 0 0 0 0 0 0 0 0 0 0 0 0 78 4 78 78 78 0 1 4 78 1 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 155 0 1 7 1 0 155 155 155 155 1 0 0 0 0 7 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 54 0 0 0 54 54 54 0 54 0 0 2 0 0 Rclass ir2class Gclass ir1class ir2 G ir1 ir2 ir1 ir2 class Given a relationship, it generates 2 dual tables 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 1 1 0 1 0 1 0 0 w1 1 2 w2 1 2 1 1 1 1 1 1 2 1 2 2 1 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... 0 1 1 1 0 0 0 1 1 0 0 0 1 1 0 1 0 0 1 0 0 0 1 0 4436 4436 w5000 255 4436 255 255 255 255 4436 255 4436 255 255 255 255 1 0 0 1 0 0 0 0 0 1 1 1 0 1 0 0 0 0 0 1 0 0 0 0 R G G pixels pixels R ir1 ir2 pixels ir1 R G R WLs pixels pixels Gir1 Rir2 Rir1 Gir2 RG ir1ir2 gte50 Satlog-Landsat stride=320, get: 320-bit strides start end cls cls 320 strd 2 1073 1 1 2 321 1074 1552 2 1 322 641 1553 2513 3 1 642 961 2514 2928 4 2 1074 1393 2929 3398 5 3 1553 1872 3399 4435 _7 3 1873 2192 4436 3 2193 2512 4 2514 2833 5 2929 3248 7 3399 3718 7 3719 4038 7 4039 4358 Note: stride=320, means are way off and will produce inaccurate classification.. lev0 pVector is a bit string w 1bit/rec. lev1 pVector=bit string wbit/rec/stride, =pred_truth applied to record stride. levN pTree = levK pVec (K=0...N-1) all with same predicate and s.t each levK stride contained within 1 levK-1 stride. R G ir1 ir2 cls means stds means stds means stds means stds 1 64.33 6.80 104.33 3.77 112.67 0.94 100.00 16.31 2 46.00 0.00 35.00 0.00 98.00 0.00 66.00 0.00 3 89.33 1.89 101.67 3.77 101.33 3.77 85.33 3.77 4 78.00 0.00 91.00 0.00 96.00 0.00 78.00 0.00 5 57.00 0.00 53.00 0.00 66.00 0.00 57.00 0.00 7 67.67 1.70 76.33 1.89 74.00 0.00 67.67 1.70 The table is (and it generates the [labeled by value] relationships):
R G ir1 ir2 std 8 15 13 9 1 8 13 13 19 2 5 7 7 6 3 6 8 8 7 4 6 12 13 13 5 5 8 9 7 7 R G ir1 ir2 mn 62.83 95.29 108.12 89.50 1 48.84 39.91 113.89 118.31 2 87.48 105.50 110.60 87.46 3 77.41 90.94 95.61 75.35 4 59.59 62.27 83.02 69.95 5 69.01 77.42 81.59 64.13 7 FAUST Satlog evaluation 1 2 3 4 5 7 tot 461 224 397 211 237 470 2000 TP actual 99 193 325 130 151 257 1155 TP nonOb L0 pure1 212 183 314 103 157 330 1037 TP nonOblique 14 1 42 103 36 189 385 FP level-1 50% 322 199 344 145 174 353 1537 TP Obl level-0 28 3 80 171 107 74 463 FP MeansMidPoint 359 205 332 144 175 324 1539 TP Obl level-0 29 18 47 156 131 58 439 FP s1/(s1+s2) 410 212 277 179 199 324 1601 TP 2s1/(2s1+s2) 114 40 113 259 235 58 819 FP Ob L0 no elim 309 212 277 154 163 248 1363 TP 2s1/(2s1+s2) 22 40 65 211 196 27 561 FP Ob L0 234571 329 189 277 154 164 307 1420 TP 2s1/(2s1+s2) 25 1 113 211 121 33 504 FP Ob L0 347512 355 189 277 154 164 307 1446 TP 2s1/(2s1+s2) 37 18 14 259 121 33 482 FPOb L0425713 2 33 56 58 6 18 173 TP BandClass rule 0 0 24 46 0 193 263 FP mining (below) red green ir1 ir2 abv below abv below abv below abv below avg 1 4.33 2.10 5.29 2.16 1.68 8.09 13.11 0.94 4.71 2 1.30 1.12 6.07 0.94 2.36 3 1.09 2.16 8.09 6.07 1.07 13.11 5.27 4 1.31 1.09 1.18 5.29 1.67 1.68 3.70 1.07 2.12 5 1.30 4.33 1.12 1.32 15.37 1.67 3.43 3.70 4.03 7 2.10 1.31 1.32 1.18 15.37 3.43 4.12 pmr*pstdv + pmv*2pstdr 2pstdr a = pmr + (pmv-pmr) = pstdr +2pstdv pstdv+2pstdr G[0,46]2 G[47,64]5 G[65,81]7 G[81,94]4 G[94,255]{1,3} R[0,48]{1,2} R[49,62]{1,5} above=(std+stdup)/gap below=(std+stddn)/gapdn suggest ord 425713 cls avg 4 2.12 2 2.36 5 4.03 7 4.12 1 4.71 3 5.27 R[82,255]3 ir1[0,88]{5,7} ir2[0,52]5 NonOblique lev-0 1's 2's 3's 4's 5's 7's True Positives: 99 193 325 130 151 257 Class actual-> 461 224 397 211 237 470 2s1, # of FPs reduced and TPs somewhat reduced. Better? Parameterize the 2 to max TPs, min FPs. Best parameter? NonOblq lev1 gt50 1's 2's 3's 4's 5's 7's True Positives: 212 183 314 103 157 330 False Positives: 14 1 42 103 36 189 Oblique level-0 using midpoint of means 1's 2's 3's 4's 5's 7's True Positives: 322 199 344 145 174 353 False Positives: 28 3 80 171 107 74 Oblique level-0 using means and stds of projections (w/o cls elim) 1's 2's 3's 4's 5's 7's True Positives: 359 205 332 144 175 324 False Positives: 29 18 47 156 131 58 Oblique lev-0, means, stds of projections (w cls elim in 2345671 order)Note that none occurs 1's 2's 3's 4's 5's 7's True Positives: 359 205 332 144 175 324 False Positives: 29 18 47 156 131 58 Oblique level-0 using means and stds of projections, doubling pstd No elimination! 1's 2's 3's 4's 5's 7's True Positives: 410 212 277 179 199 324 False Positives: 114 40 113 259 235 58 Oblique lev-0, means, stds of projs,doubling pstdr, classify, eliminate in 2,3,4,5,7,1 ord 1's 2's 3's 4's 5's 7's True Positives: 309 212 277 154 163 248 False Positives: 22 40 65 211 196 27 Oblique lev-0, means,stds of projs,doubling pstdr, classify, elim 3,4,7,5,1,2 ord 1's 2's 3's 4's 5's 7's True Positives: 329 189 277 154 164 307 False Positives: 25 1 113 211 121 33 2s1/(2s1+s2) elim ord: 425713 TP: 355 205 224 179 172 307 FP: 37 18 14 259 121 33 Conclusion? MeansMidPoint and Oblique std1/(std1+std2) are best with the Oblique version slightly better. I wonder how these two methods would work on Netflix? Two ways: UTbl(User, M1,...,M17,770) (u,m); umTrainingTbl = SubUTbl(Support(m), Support(u), m) MTbl(Movie, U1,...,U480189) (m,u); muTrainingTbl = SubMTbl(Support(u), Support(m), u)
kmurph2@clemson.edu Mar 06 Yes, pTREES for med informatics, Bill! We could work so many miracles.. data we can generate requires robust informatics, comp. bio. would put resources into this. Keith Murphy, Chair Genetics/Biochem Dir, Clemson U Genomics Inst. WP: 3/6 Wave applied pTrees to Bioinformatics too (took second in 2002 ACM KDD-cup in bioinformaticsand took first in the 2006 ACM KDD-cup in medical informatics. 2006 ACM KDD Cup Winning Team Leader Task 3. http://www.cs.unm.edu/kdd_cup_2006, http://www.cs.unm.edu/files/kdd-cup-2006-task-spec-final.pdf . 2002 ACM KDD Cup, Task 2. Yeast Gene Regulation Prediction: See http://www.acm.org/sigs/sigkdd/kddcup/index.php?section=2002&method=res Mark Silverman Feb 29: tweaking Greg's faust impl and look at gap split (looks for max gap, not max gap on both side of mean -should be?) WP: looks like 50%ones impure pTrees can give cut-hyperplanes (for FAUST) as good as raw pTrees. what's the advantage? Since FAUST training is a 1-time process, it isn't speed critical. Very fast impure pTree batch classification (after training) would be very exciting. Once the cut-hyper-planes identified (e.g., FPGA spits out 50%ones impure pTrees for incoming unclassified datasets (e.g., satellite images) and sends them thro (FPGA) for "Md's "One-Pass-Across-Columns = OPAC" batch classification - all happening on-the-fly with nearly zero delay... For PINE (nearest neighbor), we don't even train a model, so the 50%ones impure pTree classification-phase could be very significantly better. Business Intelligence= "What does this customer want next, based on histories?": FAUST is model-based (training phase=build model of 1 hyperplane for Oblique or up to 1-per-col for non-Oblique). Use the model to classify. In Bus-Intel, with every new unclassified sample, a different vector space appears. (every customer rates a different set of items). So to use FAUST-PINE, there's the non-vector-space problem to solve. non-Oblique FAUST better than Oblique, since cols have different cardinalities (not a vector space to calculate oblique hyperplanes). In general, we're attempting is to marry MYRRH multi-hop Relationship or Rule Mining with FAUST-PINE Classification or Table Mining. On Social Network Mining: We have some social network mining research threads percolating: 1. facebook-friends multi-hopped with buying-preference relationships (or multi-hopped with security threat relationships or with?) 2. implications of twitter blooms for event prediction (e.g., commod/stock changes, events, political trends, bubbles/bursts, purchasing patterns ... I would like to tie image classification with social networks somehow too ;-) WP: 3/1/12 Note on "...very excited about the discussions on MYRRH and applying it to classification problems, seems hugely innovative..." I want to try to view Images as relationships, rather than as tables, each row = a pixel and each cols is "the photon count in a frequency band". Any table=relationship (AKA, a matrix, rolodex card) w 2 entity axes: 1. usual row entity (e.g., pixels), 2. col entity(s) (e.g., wavlen interval). Any matrix is a dual pair of tables (via rotation). Cust-Item Rating matrix is rating tbl pair: Custs(Items) and its rotated dual, Item(Custs). When sufficient #of fine-band, hyper-spectral sensors in the air (plus on/in the ground), there will be a sufficient # of separate columns to do MYRRH on the relationship between pixels and wavelengths multi-hopped with the relationship between classes and pixels (...nearly every measurement is a summarization or a intervalization (even a pixel is a 2-D intervalization of an infinite set of points in space), so viewing wavelength as an intervalization of a continuous phenomenon is just as valid, right?). What if we do FAUST-PINE on the rotated image relationship, Wavelength(pixel_photon_count) instead of, Pixel(Wavelength_photon_count)? Note that classes which are not convex in Pix(WL) (that are spread out spatially all over the image) might be convex in WL(Pix)? tried prelims - disappointing for classification (tried applying concept on SatLogLandsat(R,G,ir1,ir2,class). too few bands or classes? Still, I'm hoping for "Wow! Look at this!" when, e.g., classes aren't known/clear and there are thousands of them and millions of bands...) e.g., 2 huge square-ish relationships to multi-hop. difficult (curse of dim = too many cols which are the relevant?) rule mining comes into its own. One last thought: regarding " the curse of dimensionality = too many columns - which are the relevant ones? ", FAUST automatically filters irrelevant cols to find those that reveal [convex] classes (all good classes are convex in proper feature space. e.g., Class=yellow_car may round-ish in Pix(RedWaveLen,GreenWaveLen, BlueWaveLen, OtherWaveLens), once R,G,B are isolated as relevant ones. Class=pavement is fragmented in Pix(RWL,GWL,BWL,OWLs) but may be convex in WL(pix_x, pix_y) (because pavement is color consistent?) Last point: We have to get you a FAUST implementation! It almost has to be orders of magnitude faster than pknn! The speedup should be very sublinear - almost constant (nearly independent of cardinality) - because it is a bulk classifier (one horizontal pass gains us a class_mask_pTree, distinguishing all points predicted to be in that class). So, not only is it model-based, but it is a batch classifier. Model-based classifiers that require scanning horizontal datasets cannot compete! Mark 3/2/12:Very close on faust. WP: it's important the classification step be done in bulk lest you lose the main huge benefit of FAUST. What happens at the end if you've peeled off all the classes and there are still some unclassified points left? have “mixed”/“default” (e.g., SatLog class=6=“mixed”) potential interest from some folks who have close relationship with Arbitron. Seems like a netflix story to me...
Netflix data{mk}k=1..17770 UPTreeSet 3*17770 bitslices wide UserTable(uID,m1,...,m17770) m0,2 . . . m17769,0 u1 : uk . . . u480189 m1 ... mh ... m17770 u1 : uk . . . u480189 mk(u,r,d) avg:5655u/m m 1 2 4 5 5 m 1 2 4 5 5 uIDrating date u i1rmk,u dmk,u ui2 . . . ui n k 1/0 rmhuk u 324513?45 u 324513?45 Main:(m,u,r,d) avg:209m/u mIDuIDrating date m1 u 1 rm,u dm,u m1 u2 . . . m17770 u480189 r17770,480189 d17770,480189 or U2649429 -------- 100,480,507 -------- 47B 47B MTbl(mID,u1...u480189) MPTreeSet 3*480189 bitslices wide u1 uk u480189 m1 : m h : m17770 u0,2 u480189,0 m1 : m h : m17770 0/1 rmhuk 47B 47B (u,m) to be predicted, form umTrainingTbl=SubUTbl(Support(m),Support(u),m) Lots of 0s in vector sp, umTraningTbl). Want the largest subtable without zeros. How? SubUTbl( nSup(u)mSup(n), Sup(u),m)? Using Coordinate-wise FAUST (not Oblique), in each coordinate, nSup(u), divide up all users vSup(n)Sup(m) into their rating classes, rating(m,v). then: 1. calculate the class means and stds. Sort means. 2. calculate gaps 3. choose best gap and define cutpoint using stds. Coord FAUST, in each coord, vSup(m), divide up all movies nSup(v)Sup(u) to rating classes 1. calculate the class means and stds. Sort means. 2. calculate gaps 3. choose best gap and define cutpoint using stds. Of course, the two supports won't be tight together like that but they are put that way for clarity. This of course may be slow. How can we speed it up? Gaps alone not best (especially since the sum of the gaps is no more than 4 and there are 4 gaps). Weighting (correlation(m,n)-based) useful (higher the correlation the more significant the gap??) Ctpts constructed for just this one prediction, rating(u,m). Make sense to find all of them. Should just find, e,g, which n-class-mean(s) rating(u,n) is closest to and make those the votes? (u,m) to be predicted, from umTrainingTbl = SubUTbl(Support(m), Support(u),m)





















