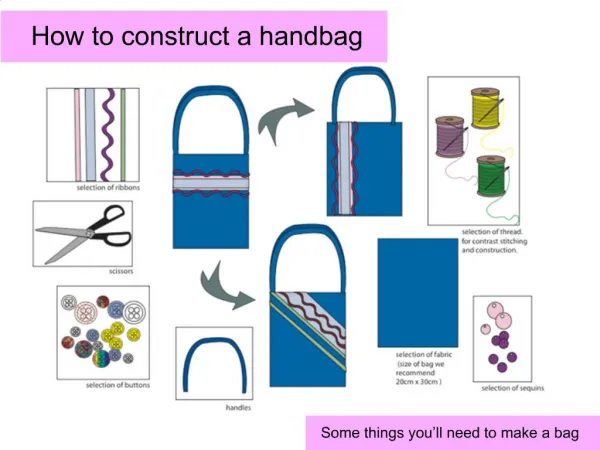
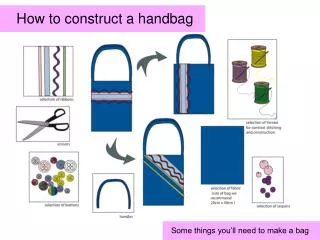
Download

1 / 57
570 likes | 706 Views
Learning to Construct and Reason with a Large KB of Extracted Information. William W. Cohen Machine Learning Dept and Language Technology Dept joint work with: Tom Mitchell, Ni Lao, William Wang, Kathryn Rivard Mazaitis,

E N D
Learning to Construct and Reason with a Large KB of Extracted Information William W. CohenMachine Learning Dept and Language Technology Dept joint work with: Tom Mitchell, Ni Lao, William Wang, Kathryn Rivard Mazaitis, Richard Wang, Frank Lin, Ni Lao, Estevam Hruschka, Jr., Burr Settles, Partha Talukdar, Derry Wijaya, Edith Law, Justin Betteridge, Jayant Krishnamurthy, Bryan Kisiel, Andrew Carlson, Weam Abu Zaki , Bhavana Dalvi, Malcolm Greaves, Lise Getoor, Jay Pujara, Hui Miao, …
Outline • Background: information extraction and NELL • Key ideas in NELL • Coupled learning • Multi-view, multi-strategy learning • Inference in NELL • Inference as another learning strategy • Learning in graphs • Path Ranking Algorithm • ProPPR • Promotion as inference • Conclusions & summary
SimStudent will learn rules to solve a problem step-by-step and guide a student through how solve problems step-by-step
Summary of SimStudent • Possible for a human author (eg middle school teacher) to build an ITS system • by building a GUI, then demonstrating problem solving and having the system learn how from examples • The rules learned by SimStudent can be used to construct a “student model” • with parameter tuning this can predict how well individual students will learn • better than state-of-the-art in some cases! • AI problem solving with a cognitively predictive model … and ILP is a key component!
Information Extraction • Goal: • Extract facts about the world automatically by reading text • IE systems are usually based on learning how to recognize facts in text • .. and then (sometimes) aggregating the results • Latest-generation IE systems need not require large amounts of training • … and IE does not necessarily require subtle analysis of any particular piece of text
Never Ending Language Learning (NELL) • NELL is a broad-coverage IE system • Simultaneously learning 500-600 concepts and relations (person, celebrity, emotion, aquiredBy, locatedIn, capitalCityOf, ..) • Starting point: containment/disjointness relations between concepts, types for relations, and O(10) examples per concept/relation • Uses 500M web page corpus + live queries • Running (almost) continuously for over three years • Has learned over 50M beliefs, over 1M high-confidence ones • about 85% of high-confidence beliefs are correct
Demo • http://rtw.ml.cmu.edu/rtw/
Outline • Background: information extraction and NELL • Key ideas in NELL • Coupled learning • Multi-view, multi-strategy learning • Inference in NELL • Inference as another learning strategy • Learning in graphs • Path Ranking Algorithm • ProPPR • Promotion as inference • Conclusions & summary
Bootstrapped SSL learning of lexical patterns it’s underconstrained!! Extract cities: Paris Pittsburgh Seattle Cupertino San Francisco Austin denial anxiety selfishness Berlin mayor of arg1 live in arg1 arg1 is home of traits such as arg1 Given: four seed examples of the class “city”
One Key to Accurate Semi-Supervised Learning teamPlaysSport(t,s) playsForTeam(a,t) person playsSport(a,s) sport team athlete coach coach(NP) coachesTeam(c,t) NP NP1 NP2 Krzyzewski coaches the Blue Devils. Krzyzewski coaches the Blue Devils. much easier (more constrained) semi-supervised learning problem hard (underconstrained) semi-supervised learning problem Easier to learn manyinterrelated tasks than one isolated task Also easier to learn using many different types of information
Outline • Background: information extraction and NELL • Key ideas in NELL • Coupled learning • Multi-view, multi-strategy learning • Inference in NELL • Inference as another learning strategy • Learning in graphs • Path Ranking Algorithm • ProPPR • Promotion as inference • Conclusions & summary
Another key idea: use multiple types of information evidence integration CBL text extraction patterns SEAL HTML extraction patterns Morph Morphologybased extractor PRA learned inference rules Ontology and populated KB the Web
Outline • Background: information extraction and NELL • Key ideas in NELL • Coupled learning • Multi-view, multi-strategy learning • Inference in NELL • Inference as another learning strategy • Background: Learning in graphs • Path Ranking Algorithm • ProPPR • Promotion as inference • Conclusions & summary
Background: Personal Info Management as Similarity Queries on a Graph [SIGIR 2006, EMNLP 2008, TOIS 2010] NSF Term In Subject Einat Minkov, Univ Haifa Sent To William graph proposal CMU 6/17/07 6/18/07 einat@cs.cmu.edu
Learning about graph similarity • Personalized PageRank aka Random Walk with Restart: • Similarity measure for nodes in a graph, analogous to TFIDF for text in a WHIRL database • natural extension to PageRank • amenable to learning parameters of the walk (gradient search, w/ various optimization metrics): • Toutanova, Manning & NG, ICML2004; Nie et al, WWW2005; Xi et al, SIGIR 2005 • or: reranking, etc • queries: Given type t* and node x, find y:T(y)=t* and y~x Given type t* and nodes X, find y:T(y)=t* and y~X
Many tasks can be reduced to similarity queries Person namedisambiguation [ term “andy”file msgId ] “person” Threading • What are the adjacent messages in this thread? • A proxy for finding “more messages like this one” [ file msgId ] “file” Alias finding What are the email-addresses of Jason ?... [ term Jason ] “email-address” Meeting attendees finder Which email-addresses (persons) should I notify about this meeting? [ meeting mtgId ] “email-address”
Learning about graph similarity:the next generation • Personalized PageRank aka Random Walk with Restart: • Given type t* and nodes X, find y:T(y)=t* and y~X • Ni Lao’s thesis (2012): New, better learning methods • richer parameterization • faster PPR inference • structure learning • Other tasks: • relation-finding in parsed text • information management for biologists • inference in large noisy knowledge bases
Lao: A learned random walk strategy is a weighted set of random-walk “experts”, each of which is a walk constrained by a path (i.e., sequence of relations) Recommending papers to cite in a paper being prepared 1) papers co-cited with on-topic papers 6) approx. standard IR retrieval 7,8) papers cited during the past two years 12-13) papers published during the past two years
Another study:learning inference rules for a noisy KB(Lao, Cohen, Mitchell 2011)(Lao et al, 2012) Random walk interpretation is crucial Synonyms of the query team i.e. 10-15 extra points in MRR
Another key idea: use multiple types of information evidence integration CBL text extraction patterns SEAL HTML extraction patterns Morph Morphologybased extractor PRA learned inference rules Ontology and populated KB the Web
Outline • Background: information extraction and NELL • Key ideas in NELL • Inference in NELL • Inference as another learning strategy • Background: Learning in graphs • Path Ranking Algorithm • PRA + FOL: ProPPR and joint learning for inference • Promotion as inference • Conclusions & summary
How can you extend PRA to • Non-binary predicates? • Paths that include constants? • Recursive rules? • …. ? • Current direction: using ideas from PRA in a general first-order logic: ProPPR
A limitation • Paths are learned separately for each relation type, and one learned rule can’t call another • PRA can learn this…. athletePlaySportViaRule(Athlete,Sport) onTeamViaKB(Athlete,Team), teamPlaysSportViaKB(Team,Sport) teamPlaysSportViaRule(Team,Sport) memberOfViaKB(Team,Conference), hasMemberViaKB(Conference,Team2), playsViaKB(Team2,Sport). teamPlaysSportViaRule(Team,Sport) onTeamViaKB(Athlete,Team), athletePlaysSportViaKB(Athlete,Sport)
A limitation • Paths are learned separately for each relation type, and one learned rule can’t call another • But PRA can’t learn this….. athletePlaySport(Athlete,Sport) onTeam(Athlete,Team), teamPlaysSport(Team,Sport) athletePlaySport(Athlete,Sport) athletePlaySportViaKB(Athlete,Sport) teamPlaysSport(Team,Sport) memberOf(Team,Conference), hasMember(Conference,Team2), plays(Team2,Sport). teamPlaysSport(Team,Sport) onTeam(Athlete,Team), athletePlaysSport(Athlete,Sport) teamPlaysSport(Team,Sport) teamPlaysSportViaKB(Team,Sport)
Solution: a major extension from PRA to include large subset of Prolog athletePlaySport(Athlete,Sport) onTeam(Athlete,Team), teamPlaysSport(Team,Sport) athletePlaySport(Athlete,Sport) athletePlaySportViaKB(Athlete,Sport) teamPlaysSport(Team,Sport) memberOf(Team,Conference), hasMember(Conference,Team2), plays(Team2,Sport). teamPlaysSport(Team,Sport) onTeam(Athlete,Team), athletePlaysSport(Athlete,Sport) teamPlaysSport(Team,Sport) teamPlaysSportViaKB(Team,Sport)
Sample ProPPR program…. features of rules (vars from head ok) Horn rules
.. and search space… D’oh! This is a graph!
Score for a query soln (e.g., “Z=sport” for “about(a,Z)”) depends on probability of reaching a ☐ node* • learn transition probabilities based on features of the rules • implicit “reset” transitions with (p≥α) back to query node • Looking for answers supported by many short proofs *Exactly as in Stochastic Logic Programs [Cussens, 2001] “Grounding” size is O(1/αε) … ie independent of DB size fast approx incremental inference (Reid,Lang,Chung, 08) Learning: supervised variant of personalized PageRank (Backstrom & Leskovic, 2011)
Sample Task: Citation Matching • Task: • citation matching (Alchemy: Poon & Domingos). • Dataset: • CORA dataset, 1295 citations of 132 distinct papers. • Training set: section 1-4. • Test set: section 5. • ProPPR program: • translated from corresponding Markov logic network (dropping non-Horn clauses) • # of rules: 21.
Time: Citation Matchingvs Alchemy “Grounding” is independent of DB size
Accuracy: Citation Matching Our rules UW rules AUC scores: 0.0=low, 1.0=hi w=1 is before learning
It gets better….. • Learning uses many example queries • e.g: sameCitation(c120,X) with X=c123+, X=c124-, … • Each query is grounded to a separate small graph (for its proof) • Goal is to tune weights on these edge features to optimize RWR on the query-graphs. • Can do SGD and run RWR separately on each query-graph • Graphs do share edge features, so there’s some synchronization needed
Learning can be parallelized by splitting on the separate “groundings” of each query
Back to NELL…… evidence integration CBL text extraction patterns SEAL HTML extraction patterns Morph Morphologybased extractor PRA learned inference rules Ontology and populated KB the Web
Experiment: • Take top K paths for each predicate learned by Lao’s PRA • (I don’t know how to do structure learning for ProPPR yet) • Convert to a mutually recursive ProPPR program • Train weights on entire program athletePlaySport(Athlete,Sport) onTeam(Athlete,Team), teamPlaysSport(Team,Sport) athletePlaySport(Athlete,Sport) athletePlaySportViaKB(Athlete,Sport) teamPlaysSport(Team,Sport) memberOf(Team,Conference), hasMember(Conference,Team2), plays(Team2,Sport). teamPlaysSport(Team,Sport) onTeam(Athlete,Team), athletePlaysSport(Athlete,Sport) teamPlaysSport(Team,Sport) teamPlaysSportViaKB(Team,Sport)
More details • Train on NELL’s KB as of iteration 713 • Test on new facts from later iterations • Try three “subdomains” of NELL • pick a seed entity S • pick top M entities nodes in a (simple untyped RWR) from S • project KB to just these M entities • look at three subdomains, six values of M
Outline • Background: information extraction and NELL • Key ideas in NELL • Coupled learning • Multi-view, multi-strategy learning • Inference in NELL • Inference as another learning strategy • Learning in graphs • Path Ranking Algorithm • ProPPR • Promotion as inference • Conclusions & summary
More detail on NELL • For iteration i=1,….,715,…: • For each view (lexical patterns, …, PRA): • Distantly-train for that view using KBi • Propose new “candidate beliefs” based on the learned view-specific classifier • Hueristically find the “best” candidate beliefs and “promote” them into KBi+1 Not obvious how to promote in a principled way …
Promotion: identifying new correct extractions from a pool of noisy extractions • Many types of noise are possible: • co-referent entities • missing or spurious labels • missing or spurious relations • violations of ontology (e.g., an athlete that is not a person) • Identifying true extractions requires joint reasoning, e.g. • Pooling information about co-referent entities • Enforcing mutual exclusion of labels and relations • Problem: How can we integrate extractions from multiple sources in the presence of ontological constraints at the scale of millions of extractions?