Download

1 / 28
290 likes | 452 Views
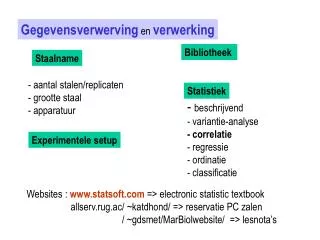
Gegevensverwerving en verwerking. Bibliotheek. Staalname. Statistiek. - aantal stalen/replicaten - grootte staal - apparatuur. - beschrijvend - variantie-analyse - correlatie - regressie Ordinatie DFA - C lassificatie. Experimentele setup.

E N D
Gegevensverwerving enverwerking Bibliotheek Staalname Statistiek - aantal stalen/replicaten - grootte staal - apparatuur • - beschrijvend • - variantie-analyse • - correlatie • - regressie • Ordinatie • DFA • - Classificatie Experimentele setup Websites : www.statsoft.com => electronic statistic textbook allserv.ugent.be/ ~katdhond/ => reservatie PC zalen / ~tdeprez => lesnota’s
E-mail : ann.vanreusel@ugent.be Lessenrooster + practica Excel practicum Diskette meebrengen Bibliotheek 1 sleutel artikel scriptie meebrengen ARC account verlengen of aanvragen ten laatste tegen vrijdag Staalname Zeeleeuw Lijst namen geboortedatum, paspoortnr en te verwittigen personen + coördinaten
Wetenschappelijk onderzoek • Doel Vraagstelling testbaar • Hypothese • Staalname of Experiment => verwerven van data • Verwerking data d.m.v.statistiek => testen van hypothese = > presentatie • Interpretatie => bespreking en vergelijking met literatuur
Statistiek is enkel middel om wetenschappelijke gegevens te interpreteren (is geen doel op zich) Onmogelijk om volledige populaties te onderzoeken. Daarom worden stalen of monsters genomen Niet altijd mogelijk om in situ waarnemingen te doen Daarom worden experimenten uitgevoerd Statistiek is een middel om na te gaan in hoever waarneming betrouwbaar is (opgaat voor totale populatie). Hulpmiddel om patronen te herkennen en te beschrijven
Voorbeelden - Staalname (ad random) gemeenschapsanalysen populatiedynamica ….. In situ - observaties gemeenschapsanalysen gedragsstudies functionele morfologie ……. In situ Labo - experimenten -manipulaties
- type data: variabelen Discreet of continue ? Vb tellingen versus metingen Nominaal Vb Kleur, geslacht, .. - schalen Ratio schaal Constante intervalgrootte, 0 punt (vb 30 cm is helft van 60 cm) • Constante intervalgrootte, geen 0 punt Vb tijdschaal 0 punt is arbitrair Vb 40° is niet twee x zo warm als 20° Interval schaal Ordinale schaal • Ranking • Minder informatie Nominale data Nominale schaal
Voorstellen van data in datamatrix: rijen en kolommen Aan- en afwezigheid Aantallen : densiteiten Procentuele abundanties : frequenties Gekodeerde abundanties (klassen) 1 : 1-10 2 : 11-50 3 : 51 - 100 4 : > 100
1e exploratiedatamatrix Gemeenschappelijke (meestal ongewenste) kenmerken van dataset : - ruis : variatie tgv meetfouten - overlap of redundantie : 2 of meer variabelen geven zelfde informatie - uitbijters : sterk afwijkende data Variatie: - meetfouten - genetische variatie tussen organismen - invloed omgevingsfactoren Measures for central tendency + measures of dispersion Parameters die gemeenschap beschrijven of karakteriseren schatting of statistiek Griekse letters Latijnse letters
Grafische voorstelling van data Samenvatting van data in frequentie tabellen Aantal keren dat een bepaalde meting of telling wordt waargenomen binnen een staal waarbij al dan niet wordt gebruik gemaakt van grootte klassen of intervallen(continue of discrete distributie) 100 500 2000
Normaal verdeling De frequentiedistributie van een grote biologische dataset ziet er meestal*uit als een normale verdeling • niet algemeen zoals oorspronkelijk aangenomen maartoch erg frequent • vooral bruikbaar in statistiek = gekoppeld aan wet van “centrale tendens” : tendens dat meeste observaties symmetrisch rond het gemiddelde liggen
Normale verdeling kan beschreven worden aan de hand van gemiddelde µen standaard deviatie Het populatiegemiddelde is top van de distributie xi µ= ___ N De breedte van de distributie wordt weergegeven door de standaard deviatie = afstand van top waar kurve overgaat van convex naar concaaf => geeft weer hoeveel metingen gemiddeld verschillen van het gemiddelde µ. De standaarddeviatie is de vierkantswortel vanvariantie (xi- µ)2 = ___________ N
SD heeft zelfde eenheid als gemiddelde (xi- µ)2 ² = _______ N Variantie is som van kwadraat * van alle afwijkingen van het gemiddelde, gedeeld door aantal waarnemingen * kwadraat anders zou som 0 zijn In geval van een normaal verdeling vallen 95 % van alle waarnemingen binnen 1.96 maal de standaard deviatie. 95 % betrouwbaarheidsintervallen 99 % valt binnen 3.29 x SD
Schatting van standaarddeviatie Delen door N-1 ipv door N (xi- µ)2 s = _______ N-1 Delen door N zou een onderschatting betekenen, vooral wanneer N klein is N-1 is aantal vrijheidsgraden df van een staal of aantal onafhankelijke eenheden om tot gemiddelde µ te komen. (xi- µ)2 s² = _________ N-1
Hoe ver is gemiddelde een betrouwbare schatting ? Stel we nemen een oneindig aantal stalen voor een populatie Voor elk staal wordt een gemiddelde berekend Deze gemiddelde waarden gaan op hun beurt opnieuw een normaal verdeling vertonen “central limit theorem” Deze normaal verdeling is wel smaller aangezien hoge en lage waarden teniet worden gedaan bij berekening van gemiddelde. De standaard fout of standard error (SE) is maat voor hoeveel gemiddelden gaan verschillen van werkelijk populatiegemiddelde S SE = ______ N
SE is net zoals SD buigpunt van de curve. Opnieuw kunnen betrouwbaarheidsintervallen berekend worden . 95 % van gemiddelden vallen binnen 1.96 x SE De schatting van gemiddelde waarden heeft echter eerder t distributie dan normaal distributie s SE = ______ N Vorm van t distributie is gerelateerd aan aantal vrijheidsgraden. Hoe meer df hoe meer t distributie => normaal distributie
Betrouwbaarheidsintervallen voor populatiegemiddelde daarom berekend aan de hand van getabelleerde kritische waarde voor t distributie 95 % CI = µ ±tN-1,5 % x SE Hoe groter de staalgrootte, hoe kleiner betrouwbaarheidsintervallen. Immers hoe groter N , hoe kleiner SE en hoe kleiner t
Overige maten voor centrale tendens Mediaan : middelste waarneming in een geordende dataset (50 % punt) Mode : meest voorkomende waarde in een dataset
Geometrisch gemiddelde: n x1x2x3 …..xn Antilog 1/n log xi Het geometrisch gemiddelde is steeds kleiner dan het aritmetisch gemiddelde, tenzij alle data dezelfde waarde hebben.
Grafische voorstelling : vervolg Box and whisker plots
Transformaties : log (x+1) - maakt frequentiedistributies minder ‘skewed’ naar rechts => hoogste waarden worden minder hoog Ruwe data densiteiten Log (x+1) getransformeerde data
Transformaties : log (x+1) Om een datamatrix met veel 0 waarden te transformeren, wordt een klein getal aan de oorspronkelijke waarden toegevoegd Voor tellingen voegt men meestal 1 toe zodat b = log (0+1)=0
De varianties worden onafhankelijk van gemiddelden RUW LOG (x+1) • Algemeen gebruikt voor drie redenen : • statistisch aantrekkelijk dat data normaal verdeeld zijn • Om minder gewicht te geven aan dominante soorten en meer gewicht aan kwalitatieve aspecten • Voor omgevingsvariabelen: als weergave van de lineaire respons van soorten tov het logaritme van omgevingsvariabelen
Tweede en vierdemachtswortel transformaties => maakt variantie onafhankelijk van het gemiddelde Vergelijkbaar maar minder drastisch dan de logtransformatie Machtstransformatie p = 0 aan- afwezigheid p = 0.5 vierkantswortel p = 0.25 vierdemachts wortel
Arc sinus (vierkantswortel)transformatie => spreidt grote en kleine waarden meer uit => drukt middelste waarden samen % =(2/3,141592)*ASIN((X/100)^(1/2)) • Deze transformatie wordt aanbevolen voor procentuele data • Data moeten varieren tussen 0 en 1 • The arc sinus (vierkantswortel) wordt vermenigvuldigd met 2/п • Om de resultaten van de arcsinus (x) uit te drukken in radialen van 0 tot 1
Standardisatie van variabelen uitgedrukt in verschillende eenheden Vb een verschil van 1 eenheid in pH is duidelijk verschillend van een verschil van 1 microgram fosfaat • Vervang metingen door een rank nummer • Vervang elke meting door de afwijking tov de gemiddelde waarde berekend over alle metingen (= centring) • Standardiseer naar een gemiddelde van 0 en variantie 1