Download

1 / 14
140 likes | 174 Views
The Clustering technique in Statistical Analysis is used to determine the subsets as clusters in the data using the specified distance measure. However, this technique cannot be applied easily for longitudinal or time-series data. In this blog, I will discuss some of the methods used for modeling longitudinal or panel data using the Clustering Analysis technique as explained in Schmatter (2011). Statswork offers statistical services as per the requirements of the customers. When you Order statistical Services at Statswork, we promise you the following u2013 Always on Time, outstanding customer support, and High-quality Subject Matter Experts.<br>Why Statswork?<br>Plagiarism Free | Unlimited Support | Prompt Turnaround Times | Subject Matter Expertise | Experienced Bio-statisticians & Statisticians | Statistics Across Methodologies | Wide Range Of Tools & Technologies Supports | Tutoring Services | 24/7 Email Support | Recommended by Universities<br>Contact Us:t<br>t<br>Website: www.statswork.com/<br><br>Email: info@statswork.com<br><br>UnitedKingdom: 44-1143520021<br>t<br>India: 91-4448137070t<br>tt<br>WhatsApp: 91-8754446690<br>

E N D
Panel Data Analysis: A Survey onModel-Based Clustering of TimeSeries An Academic presentationby Dr. Nancy Agens, Head, Technical Operations, Statswork Group www.statswork.com Email:info@statswork.com
Outline ofTopics TODAY'SDISCUSSION Dirichlet Prior MCMCSimulation In Brief Longitudinal Data Model BasedClustering Example on Model BasedClustering Conclusion
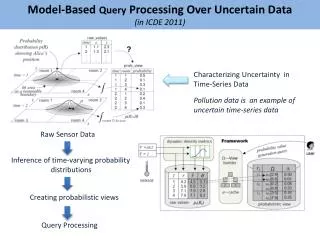
InBrief Clustering technique in Statistical Analysisis used to determine the subsets as clusters in the data using specified distancemeasure. We will discuss about some of the methods used for modeling longitudinal or panel data using Clustering Analysistechnique
Longitudinal data is actually a sample of observations which are measured repeatedly overtime. And, nowadays, longitudinal/repeated measure data or panel data exists in all areas of Applied statisticssuch as finance, psychology, economics and socialsciences. Most studies deals with analyzing homogeneity in such Time seriesdata. The most common method of capturing the heterogeneity is to assume the presence of latent classes and each class are stratified using thecovariates. LongitudinalData
ModelBased Clustering Measuring the distance between time series data is not appropriate thus a cluster based modeling strategy for finite mixture models is adopted using Bayesianrule. Model based clustering considers each time series to a single unit contained in an unknown latentclass. One can see an excellent review of finite mixture models for longitudinal data in Vermunt (2010) especially in the areas of psychology, bio-statistics and other appliedareas.
The data consists of 237 teenagers who use marijuana for the year 1976-1980. The use marijuana is categorized into three types as never, not more than once a month and more than once amonth. The following figure represents the sample of 10 observed response of use of marijuana usage among the 237teenagers. The model considered for analyzing the marijuana usage is based on Generalized transitionmodel. Example on Model Based Clustering
Figure:Model Basedclustering
A Dirichlet prior is chosen in this case since the observed response variable is of categorical innature. Five different kernel classes are considered and evaluated the model using Dirichletprior distribution and the results for the same is presented in the followingtable. The clustering kernel M2 to M5 shows that there exists a common behaviour in marijuana usage. If the value is smaller than one, then one may conclude that the method is overfitting, in this case, H3 class of kernel seems to beoverfitting. Dirichlet Prior
An MCMC simulation is carried out for M3 with H2 and the following figure explains thesample of boxplots of the posterior probabilities for male and femalegroups. Comparing the likelihood results obtained from the above table (598.5) and the previous table (596.5) the stratified Model based clustering reduces to Standard Modelbased clustering andit is clear that the use of marijuana is not associated with the genderclassification. From this results, it is concluded that the use of marijuana among teenagers may beclustered into two with never-use and other being more usergroups. MCMCSimulation
Figure:Boxplots for MCMC Simulation
To sum up, model-based clustering technique along with the Bayesian flavor yields better results since it provides an answer to the most troublesome problems in the clusteranalysis. In longitudinal or Panel datastudies, usage of eculidean distance may be a valid one and hence a kernel based clustering for Time series data Analysisis considered and selectionof the best method is analysed using different informationcriteria. An MCMC simulation is carried out to find the optimal clusteringmethodology. Conclusion
UNITEDKINGDOM +44-1143520021 INDIA +91-4448137070 EMAIL info@statswork.com CONTACTUS