Download

1 / 48
480 likes | 571 Views
Learn how to estimate causal effects using the Differences-in-Differences method with relevant examples and approaches. Understand assumptions, estimating equations, and applications in panel data analysis.

E N D
Differences-in-Differencesand A Brief Introduction to Panel Data
The Grand Experiment • Water supplied to households by competing private companies • Sometimes different companies supplied households in same street • In south London two main companies: • Lambeth Company (water supply from Thames Ditton, 22 miles upstream) • Southwark and Vauxhall Company (water supply from Thames)
In 1853/54 cholera outbreak • Death Rates per 10000 people by water company • Lambeth 10 • Southwark and Vauxhall 150 • Might be water but perhaps other factors • Snow compared death rates in 1849 epidemic • Lambeth 150 • Southwark and Vauxhall 125 • In 1852 Lambeth Company had changed supply from Hungerford Bridge
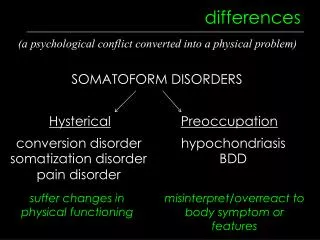
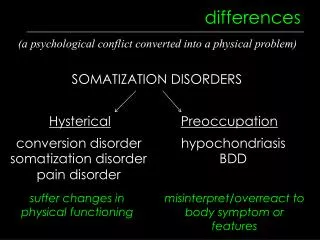
This is basic idea of Differences-in-Differences • Have already seen idea of using differences to estimate causal effects • Treatment/control groups in experimental data • Often would like to find ‘treatment’ and ‘control’ group who can be assumed to be similar in every way except receipt of treatment • This may be very difficult to do
A Weaker Assumption is.. • Assume that, in absence of treatment, difference between ‘treatment’ and ‘control’ group is constant over time • With this assumption can use observations on treatment and control group pre- and post-treatment to estimate causal effect • Idea • Difference pre-treatment is ‘normal’ difference • Difference pre-treatment is ‘normal’ difference + causal effect • Difference-in-difference is causal effect
A Treatment y C B Control Pre- Post- Time A Graphical Representation
What is D-in-D estimate? • Standard differences estimator is AB • But ‘normal’ difference estimated as CB • Hence D-in-D estimate is AC • Note: assumes trends in outcome variables the same for treatment and control groups • This is not testable • with two periods can get no idea of plausibility but can with more periods
Some Notation • Define: μit=E(yit) Where i=0 is control group, i=1 is treatment Where t=0 is pre-period, t=1 is post-period • Standard ‘differences’ estimate of causal effect is estimate of: μ11-μ01 • ‘Differences-in-Differences’ estimate of causal effect is estimate of: (μ11-μ01)-(μ10-μ00)
How to estimate? • Can write D-in-D estimate as: (μ11-μ10)-(μ01 -μ00) • This is simply the difference in the change of treatment and control groups so can estimate as:
This is simply ‘differences’ estimator applied to the difference • To implement this need to have repeat observations on the same individuals • May not have this – individuals observed pre- and post-treatment may be different • What can we do in this case?
In this case can estimate…. • D-in-D estimate is estimate of β3 – why is this?
A Comparison of the Two Methods • Where have repeated observations could use both methods • Will give same parameter estimates • But will give different standard errors • ‘levels’ version will assume residuals are independent – unlikely to be a good assumption • Can deal with this by: • Clustering • Or estimating ‘differences’ version
Other Regressors • Can put in other regressors as before • Perhaps should think about way in which they enter the estimating equation • E.g. if level of W affects level of y then should include ΔW in differences version
Differential Trends in Treatment and Control Groups • Key assumption underlying validity of D-in-D estimate is that differences between treatment and control group would have remained constant in absence of treatment • Can never test this • With only two periods can get no idea of plausibility • But can with more than two periods
An Example:“Vertical Relationships and Competition in Retail Gasoline Markets”, by Justine Hastings, American Economic Review, 2004 • Interested in effect of vertical integration on retail petrol prices • Investigates take-over in CA of independent ‘Thrifty’ chain of petrol stations by ARCO (more integrated) • Defines treatment group as petrol stations which had a ‘Thrifty’ within 1 mile • Control group those that did not • Lots of reasons why these groups might be different so D-in-D approach seems a good idea
This picture contains relevant information… • Can see D-in-D estimate of +5c per gallon • Also can see trends before and after change very similar – D-in-D assumption valid
A Case which does not look so good…..Ashenfelter’s Dip • Interested in effect of government-sponsored training (MDTA) on earnings • Treatment group are those who received training in 1964 • Control group are random sample of population as a whole
Things to Note.. • Earnings for trainees very low in 1964 as training not working in that year – should ignore this year • Simple D-in-D approach would compare earnings in 1965 with 1963 • But earnings of trainees in 1963 seem to show a ‘dip’ – so D-in-D assumption probably not valid • Probably because those who enter training are those who had a bad shock (e.g. job loss)
Differences-in-Differences:Summary • A very useful and widespread approach • Validity does depend on assumption that trends would have been the same in absence of treatment • Can use other periods to see if this assumption is plausible or not • Uses 2 observations on same individual – most rudimentary form of panel data
A Brief Introduction to Panel Data • Panel Data has both time-series and cross-section dimension – N individuals over T periods • Will restrict attention to balanced panels – same number of observations on each individuals • Whole books written about but basics can be understood very simply and not very different from what we have seen before • Asymptotics typically done on large N, small T • Use yit to denote variable for individual i at time t
The Pooled Model • Can simply ignore panel nature of data and estimate: yit=β’xit+εit • This will be consistent if E(εit|xit)=0 or plim(X’ ε/N)=0 • But computed standard errors will only be consistent if errors uncorrelated across observations • This is unlikely: • Correlation between residuals of same individual in different time periods • Correlation between residuals of different individuals in same time period (aggregate shocks)
A More Plausible Model • Should recognise this as model with ‘group-level’ dummies or residuals • Here, individual is a ‘group’
Three Models • Fixed Effects Model • Treats θi as parameter to be estimated (like β) • Consistency does not require anything about correlation with xit • Random Effects Model • Treats θi as part of residual (like θ) • Consistency does require no correlation between θi and xit • Between-Groups Model • Runs regression on averages for each individual
Proposition 5.2The fixed effect estimator of β will be consistent if: • E(εit|xit)=0 • Rank(X,D)=N+K • Proof: Simple application of what you should know about linear regression model
Intuition • First condition should be obvious – regressors uncorrelated with residuals • Second condition requires regressors to be of full rank • Main way in which this is likely to fail in fixed effects model is if some regressors vary only across individuals and not over time • Such a variable perfectly multicollinear with individual fixed effect
Estimating the Fixed Effects Model • Can estimate by ‘brute force’ - include separate dummy variable for every individual – but may be a lot of them • Can also estimate in mean-deviation form:
How does de-meaning work? • Can do simple OLS on de-meaned variables • STATA command is like: . xtreg y x, fe i(id)
Problems with fixed effect estimator • Only uses variation within individuals – sometimes called ‘within-group’ estimator • This variation may be small part of total (so low precision) and more prone to measurement error (so more attenuation bias) • Cannot use it to estimate effect of regressor that is constant for an individual
Random Effects Estimator • Treats θi as part of residual (like θ) • Consistency does require no correlation between θi and xit • Should recognise as like model with clustered standard errors • But random effects estimator is feasible GLS estimator
More on RE Estimator • Will not describe how we compute Ω-hat – see Wooldridge • STATA command . xtreg y x, re i(id)
Proposition 5.3The random effects estimator of β will be consistent if: • E(εit|xi1,..xit,.. xiT)=0 • E(θi|xi1,..xit,.. xiT)=0 • Rank(X’Ω-1X)=k • Proof: RE estimator a special case of the feasible GLS estimator so conditions for consistency are the same. • Error has two components so need a. and b.
Comments • Assumption about exogeneity of errors is stronger than for FE model – need to assume εit uncorrelated with whole history of x – this is called strong exogeneity • Assumption about rank condition weaker than for FE model e.g. can estimate effect variables that are constant for a given individual
Another reason why may prefer RE to FE model • If exogeneity assumptions are satisfied RE estimate will be more efficient than FE estimator • Application of general principle that imposing true restriction on data leads to efficiency gain.
Another Useful Result • Can show that RE estimator can be thought of as an OLS regression of: • On: • Where: • This is sometimes called quasi-time demeaning • See Wooldridge (ch10, pp286-7) if want to know more
Between-Groups Estimator • This takes individual means and estimates the regression by OLS: • Stata command is xtreg y x, be i(id) • Condition for consistency the same as for RE estimator • But BE estimator less efficient as does not exploit variation in regressors for a given individual • And cannot estimate variables like time trends whose average values do not vary across individuals • So why would anyone ever use it – lets think about measurement error
Measurement Error in Panel Data Models • Assume true model is: • Where x is one-dimensional • Assume E(εit|xi1,..xit,.. xiT)=0 and E(θi|xi1,..xit,.. xiT)=0 so that RE and BE estimators are consistent
Measurement Error Model • Assume: • where uit is classical measurement error, x*iis average value of x* for individual i and ηit is variation around the true value which is assumed to be uncorrelated with and uit and iid. • We know this measurement error is likely to cause attenuation bias but this will vary between FE, RE and BE estimators.
Proposition 5.4 • For FE model we have: • For BE model we have: • For RE model we have: • Where:
What should we learn from this? • All rather complicated – don’t worry too much about details • But intuition is simple • Attenuation bias largest for FE estimator – Var(x*) does not appear in denominator – FE estimator does not use this variation in data
Attenuation bias larger for RE than BE estimator as T>1>κ • The averaging in the BE estimator reduces the importance of measurement error. • Important to note that these results are dependent on the particular assumption about the measurement error process and the nature of the variation in xit – things would be very different if measurement error for a given individual did not vary over time • But general point is the measurement error considerations could affect choice of model to estimate with panel data
Time Effects • Have treated time and individual dimensions asymmetrically – no good reason for this • Errors likely to be correlated for different individuals in same time period – most common way to deal with this is to include set of time dummies:
Estimating Fixed Effects Model in Differences • Can also get rid of fixed effect by differencing:
Comparison of two methods • Estimate parameters by OLS on differenced data • If only 2 observations then get same estimates as ‘de-meaning’ method • But standard errors different • Why?: assumption about autocorrelation in residuals
What Are these assumptions? • For de-meaned model: • For differenced model: • These are not consistent:
This leads to time series… • Which is ‘better’ depends on which assumption is right – how can we decide this? • We are not going to cover this in this course.