Download

1 / 59
590 likes | 693 Views
Vocab@Western. Broad v. Narrow Band Lexical Frequency Profiling (LFP) Tom Cobb Université du Québec à Montréal F riday, 21 Oct 2016, 14:00. http :// lextutor.ca/vocab@tokyo.pptx. A talk in which I attempt to…. Expand the success of LFP in the zone of learner production

E N D
Vocab@Western Broad v. Narrow Band Lexical Frequency Profiling(LFP) Tom Cobb Université du Québec à Montréal Friday, 21 Oct 2016, 14:00 http://lextutor.ca/vocab@tokyo.pptx
A talk in which I attempt to… • Expand the success of LFP • in the zone of learner production • Continue putting research to use • Maybe before it’s ready? • Complement the recent outward-looking LFP work ~ • 25k lists | 8000-word target | mid-freq vocab ~ with a look INWARD
LFP briefly reviewedGoal is to provide a frequency analysis of whole texts,with words grouped into families and families grouped into 1,000-family sets • “The cat sat on the mat” • The 1k • Cat 1k • Sat 1k • On 1k • The 1k • Mat 4k • Six words = 100% of text • 1k items = 5/6 of text = 83% So the profile is: • 1k=83% • 2k=0% • 3k=0% • 4k=17% • So 1k gives 83% coveragein this text • Or “accounts for” 83% of the tokens” 3
Where does “1k” come from? Families are summedby member frequencies So at 228,689 occurrences‘go’ family is in K1
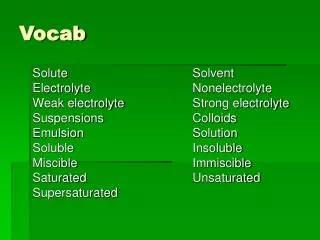
Definitions • Broad-band LFP • Carving up texts by 1,000 family sets • Narrow-band LFP • Carving up texts by smaller frequency groups • To be treated here: • 100 families • Individual word (token) frequencies
LFP main research uses • Build frequency tests • Receptive and productive • Visibly connected to the language at large • Investigate coverage • establish principled goals for instruction • 8,000 families give average 98%, etc • Schmitt Ziang & Grabe (2011) • Assess learner production • Laufer & Nation, 1995 • Ovtcharov, Cobb & Halter, 2006 • Morris & Cobb, 2004
LFP main practical uses At long last a framework for managing lexis in language instruction • Create rough-tuned, lexically appropriate learning materials • Graded readers, control on examination lexis • Find/Modify authentic texts for particular learners • Raise Ts’/Ss’ language awareness • A framework for lexical expansion • Clear, objective, communicable, visual
Backgrounder for the story • AAAL 2011, I was “commentator” for a colloquium on LFP-like text analysis tools • All quite math heavy • Of varying potential utility • Few heard from since • With one exception: • Scott Crossley’s adaptation of Coh-Metrix • My Comment: “Since LFP is already working well for researchers & practitioners, what do we get for all the extra math”? • To compensate for the loss of practitioners
Crossley’s Challenge • LFP vs Coh-Metrix • for ability to distinguish between levels in 130 US learner ‘freewrites’ • Beginner (by TOEFL score) • Intermediate • Advanced • Native speaker • The specific Coh-Metrix tool used here was the COUNT INDEX, an averaged Celex frequency for every word in a text • Basically a replication of Laufer & Nation (1995)
Coh-Metrix should be a finer measure • The writer is ‘rewarded’ for using She goes rather than She go • Both are equal in LFP • But far apart by Count method • All grouping involves information loss • inasmuch as “Information = distinctions” • (Does this way of counting introduce a grammar confound? • But isn’t this all lexico-grammar anyway?)
To cut to the chase ~ • Coh-Metrix predicted learner level from writing sample accurately in 58% of cases • LFP (BNC version) predicted 48% of cases • Paper in System, 2013
… by using a complex prediction model involving DFA • Which I assumed could be made practitioner-friendly on Lextutor later, if warranted • My main contribution: to emphasize that while Count-Based LFP is slightly more accurate • Band-Based LFP is a lot more useful • With its communicable result • History of practitioner acceptance • Comprehensible diagnostic
We thus proposed methods integration:“There is a tool for every purpose unto heaven” • Thus, both methods have their advantages and, just as it is common enough for different grain sizes to be needed for different parts of a task (like cooking, where cup measures are adequate for making stew but half-teaspoons needed for the baking soda in cake), we suggest the incorporation of both methods. • For instance, one can easily imagine a language learning situation where learners are… placement tested with a band-based measure (Meara and Buxton, 1987; Beglar and Nation, 2007)… • … then enter a course of study comprising authentic materials that are either selected by a count-based frequency measure (Crossley et al. 2011, 2008) or adapted by a band measure (Cobb, 2007), or both… …all supported by a band-based vocabulary course matched to placement level, …with progress tallied at the end by a count-based measure that picks up small differences in lexical deployment.
And Yet: any practical deployment of a Count-Based measure is not obvious • … as I quickly learned when adapting some of this for Lextutor • Let’s have a go with two potential bandwidth issues in LFP
LFP Problem 1: No sig. diffs at 1k in LCsClassic problem that all learner writing is 1k But 1k comparisons do not yield sig. differences lexis cannot be used to place, assess, or publish • Using LFP • Example: A trio of 50k-word Learner Corpora that I could never get significant differ-ences out of despite ‘knowing’ they must be there (in about 2005) • Nothing at 1k • Differences at 2-3k but so few items involved…
Since these Learner Corpora will feature later… About 50,000 words each, written as part of placement measure, on same topic, by: • TESL-teachers • Non-native-speaking Quebec ESL teacher in training • Mid-ESL • Students placed in a intermediate first ESL course based partly on writing sample • Low-ESL • Students placed in Beginner class
Same ten 200-wd samples from each corpus compared by k-levels Sig Diffs after 1k but not at 1k (where 90% of the action is)
Interesting patterns, but, without a sigDiff or Effect Size>1, “No Sale” A promising inversion, however TESL group uses fewer K1, more K2 and K3 k1 k2 k3 k4
LFP Problem 2:Deriving learning materials from VP (Not what VP was designed to do, but that’s how it gets used)How do you derive a vocabulary syllabus from a 1,000-families based scheme? Sets of 1,000 flashcards?
Bronson Hui’s letter • Feb 4, 2016 • > Dear Prof. Cobb • > My name is Bronson Hui, and I am currently an EFL teacher from Hong Kong. I am eager to bridge research and practice after my Master's in SLA at Oxford a couple of years ago. Because I am teaching in a school with very weak learners in terms of proficiency, I firmly believe that vocabulary is their first step to move on. Once reading comprehension happens, life will be easier for them. These learners come into our school as Year 7 students with fewer than 1k of receptive vocabulary size. With tremendous effort, I have finally persuaded the management to move more towards a vocabulary-based teaching approach (as opposed to grammar-based). But we are facing some great difficulty now.
Bronson Hui’s letter (2) • Because comprehension is not so possible due their vocabulary size, we attempted to let them study K1-K2 words. But we did it in a decontextualised manner in form of vocabulary recognition / recall. Some students could do well, but some start to struggle after the first 500 content words. Worse still, when we provide a context which requires students to fill in a target word. They feel totally lost because they are used to decontextualised practice. At the same time, teachers complain about the lack of a context. As a result, many have suggested moving back to grammar-based teaching. But my opinion is that we can try to improve our vocabulary teaching by providing richer contexts for students to learn the item in context.
Bronson Hui’s letter (3) • > I have been using the vocabulary profile for research myself, and have tried to use it for my teaching. I quite like how we can idenitfy words at a specific frequency band in a reading passage (so we can give focused vocabulary instruction), and then we can use the VP cloze as exercise. But a thousand word at each level scares everyone at my school; even the second-500 K1 content words is too much of a scope of my students (because that could well be a double of their existing vocabulary size after 6 years of primary).
Bronson Hui’s letter (4) • > I was thinking if we could have user-defined schemes for the VP as well as the VP cloze generator, we could have more flexibility. I thought if I could give a scope of 50 or 100 words in a word list defined by our teachers, they can identify those target words in any passage and make cloze exercise the students, using a user defined scheme. In that case, I hope they may be more happy to keep on following this vocabulary approach. I am not super proficient in IT, but I imagine that involves user defining a list for the programme to search words from, and of course the programme that does the identification. I also realise there are problems with word families where users need to input the head-word. I would be truly grateful if you could offer some expert advice. • > I look forward to hearing from you. • > Bronson Hui
In other words… • Teachers are trying to use LFP framework not just for research + testing purposes • but to integrate vocab into their syllabus • Including learning targets • …for which, k-levels are not ideal • A “strong” growth is probably 550 words/year • Most are well under that
Can the “Count” Approach be used to solve either of these problems? Each problem in turn
[Prob 1]The old “No diffs @ 1k” problem in my Learner Corpora • First Guess ata user-friendlyCount tool: • Set up VP to calculate a Celex Count Index • See if it can make those Learner Corpora yield a Sig Diff or decent E.S.
First, how to “count” Celexed BNC-COCA Profile • TEXT:Well, it was (a) narrow escape. But we did it. Canadians have preserved their liberties and independence against the always rapacious American beast. • We knew there were powerful elements in the United States that wanted us to kowtow and genuflect to a simplistic worldview, that knuckle-dragging Good-versus-Evil script they have been remorselessly propagandizing all over the world since 9/11. • They have been trying to drag Canada into this simpleton's game for years, mauling truth and banishing nuance with a continuous stream of invective posing as reason, and caricature passing itself off as accuracy. • It's a difficult thing to resist the mighty United States at any time, and especially difficult in all the dust and storm of a national election. But we did it. (EXCERPT, 122 wds)
Which looks like this With some rounding-off supplied by Excel unless stretched several metres down
Then set up for whole-corpus comparisons Which involves scrolling the whole columnWhich Excel 2013 can handle(1,048,576 rows max) v.2003 it was 65,536 100,000rows down 50,000rows down
So, maybe run t-tests on log(10)s rather than full celex word counts ? Bingo! But is this legit statistically? Do those “shades of sixiness” communicate anything to practitioners?
So applying this method to those problematic Learner Corpora…
Ten 200 wd. random samples from each corpus compared irrespective of k-levels ! POST WESTERN:So this is a “sort of” solution the K1 problem has disappeared (since the k-levels have disappeared) TO DO: See if this gives a sifDiff at 1k specifically
TO DO • Lextutor upload routine for two-text significance comparison • Count comparison at K1 • Honestly cannot predict • Problem is, even if we do that we have lost the useful LFP levels framework
[Prob 2 – deriving learning materials] Back to Bronson Hui’s situation • 1000-family units are too big for his purposes • Assigning individual Celex Frequencies (or logs(10) thereof) will not give him his cloze passages • But maybe a combination of the two? • Within the BNC-Coca LFP framework • Use CELEX ratings to carve K-lists into smaller lists • For example, 10 “C”-lists
How to use Celex to change a K to 10 C’s:(1) Get family totals for each k (2) Sort. (3) Cut into 10 C’s
Fifty 100-headword sets on mobile + Y E S N O T E S T S