Download

1 / 128
1.29k likes | 1.48k Views
Molecular Biology and Biochemistry. Monica Bianchini Dipartimento di Ingegneria dell’Informazione e Scienze Matematiche monica@diism.unisi.it.

E N D
MolecularBiology and Biochemistry Monica Bianchini Dipartimento di Ingegneria dell’Informazione e Scienze Matematiche monica@diism.unisi.it “Science cannot solve the ultimate mystery of Nature. And that is because, in the last analysis, we ourselves are a part of the mystery that we are trying to solve.” (M. Planck)
Tableofcontents • Introduction • The genetic material • Gene structure and information content • The nature of the chemical bonds • Molecular biology tools • The genome
Introduction 1 • The main feature of living organisms is their ability of saving, using and transmitting information • Bioinformatics aims at: • determining which information is biologically relevant • deciphering how it is used in order to control the chemistry of living organisms
Introduction 2 • Bioinformatics is a discipline that lies at the crossroad of Biology, Computer Science and new technologies • It is characterized by the application of mathematical, statistical, and computational tools for biological, biochemical and biophysical data processing • The main topic in Bioinformatics is the analysis of DNA but, with the wide diffusion of more economic and effective techniques to acquire protein data, also proteins have become available for bioinformatics analysis
Introduction 3 • In Bioinformatics, there are three main subtopics: • Development and implementation of tools to store, manage and analyze biological data • Creation of biobanks, database management • Information extraction via data analysis and interpretation • Data mining • Development of new algorithms to extract/verify relationships among a huge amount of information • Statistical methods, artificial intelligence
Introduction 4 • Therefore, Bioinformatics can be defined as... • …the set of computer science methods and tools which can be applied for processing data in the fields of Biology, Chemistry and Medicine • Bioinformatics covers: • Database building techniques, useful for bio-medical research, and ad hoc query tools • Artificial intelligence and statistical methods, which allow the analysis of such data and the identification/automatic extraction of significant information
Introduction 5 • With the rapid development of sequencing technology, higher throughput of better quality data can now be achieved at a lower cost • These data are being extensively used to decipher the mechanisms of biological systems at the most basic level • However, this huge and growing amount of highquality data, and the information delivered, continue to create challenges for researchers in Bioinformatics
The genetic material 1 • The genetic material is the DNA (deoxyribonucleic acid) • It is actually the information contained in the DNA that allows the organization of inanimate molecules in living cells and organisms, capable of regulating their internal chemical composition and their growth and reproduction • It is also the DNA that gives us the inheritance of our ancestors physical traits, through the transmission of genes
The genetic material 2 • Genes contain the information, in the form of specific nucleotide sequences, which constitute the DNA molecules • DNA molecules use only four nucleobases, guanine, adenine, thymine and cytosine (G, A, T, C), which are attached to a phosphate group (PO4) and to a deoxyribose sugar (C5H10O4), to form a nucleotide Purines Pyrimidines Guanine Adenine Thymine Cytosine
The genetic material 3 • All the information collected in the genes derives from the order in which the four nucleotides are organized along the DNA molecule • Complicated genes may be composed of hundreds of nucleotides • The genetic code “which describes” an organism, known as its genome, is conserved in millions/billions of nucleotides Chemical structure of the Adenosine 5’ monophosphate: each nucleotide is composed of three parts, a phosphate group, a central deoxyribose sugar, and one out of the four nucleobases
The genetic material 4 • Nucleotide strings can be joined together to form long polynucleotide chains and, on a larger scale, a chromosome • The union of two nucleotides occurs through the formation of phosphodiester bonds, which combine the phosphate group of a nucleotide and the deoxyribose sugar of another nucleotide • The ester bonds involve connections mediated by oxygen atoms • The phosphodiester bonds occur when a phosphorus atom of a phosphate group binds two molecules via two ester bonds
The genetic material 5 The DNA nucleotides are joined together by covalent bonds between the hydroxyl groups (OH) in 5’ e 3’: the alternation of the phosphate residues and of the pentoses form the skeleton of nucleic acids
The genetic material 6 • All living organisms form phosphodiester bonds exactly in the same way • To the five carbon atoms in the deoxyribose sugar also called apentose is assigned an order number (from 1’ to 5’) Phosphoric acid Deoxyribose
The genetic material 7 • Phosphate groups of each free nucleotide are always linked to the 5’ carbon of the sugar • Phosphate groups constitute a bridge between the 5’ carbon in the deoxyribose of a new attached nucleotide and the 3’ carbon of a preexisting polynucleotide chain • A nucleotide string always starts with a free 5’ carbon, whereas, at the other end, there is a free 3’ carbon • The orientation of the DNA molecule is crucial for deciphering the information content of the cell
The genetic material 8 • A common theme in all biological systems, and at all levels, is the idea that the structure and the function of such systems are intimately correlated • The discovery of J. Watson andF. Crick(1953) that the DNA molecule, inside the cells, usually exists as a doublestranded molecule provided an invaluable clue on how DNA could act as genetic material J. Watson e F. Crick (Nobel Prize for Medicine with M. Wilkinson, 1962)
The genetic material 9 • Therefore, the DNA is made up of two strands, and the information contained in a single strand is redundant with respect to the information contained in the other • The DNA can be replicated and faithfully transmitted from generations to generations by separating the two strands and using each strand as a template for the synthesis of its companion
The genetic material 10 New strand DNA polymerase Helicase (Single StrandBindingProtein) DNA template New strand During the DNA duplication, the double strand is separated by means of helicase; each DNA strand serves as a template for the synthesis of a new strand, produced thanks to the DNA polymerase
The genetic material 11 • More precisely: the information contained in the two DNA strands is complementary • For each G on one strand, there is a C on the complementary strand and vice versa • For each A on one strand, there is a T on the complementary strand and vice versa • The interaction between G/C, and A/T is specific and stable • In the space between the two DNA strands (11Å), guanine, with its doublering structure, is too large to couple with the double ring of an adenine or of another guanine • Thymine, with its singlering structure, is too small to interact with another nucleobase with a single ring (cytosine or thymine)
The genetic material 12 • However, the space between the two DNA strands does not constitute a barrier for the interaction between G and T, or between A and C but, instead, it is their chemical nature that makes them incompatible Two hydrogen bonds The chemical interaction between the two different types of nucleobases is so stable and energetically favorable, to be responsible for the union of the two complementary strands Adenine Thymine Three hydrogen bonds Guanine Cytosine
The genetic material 13 • The two strands of the DNA molecule do not have the same orientation (5’/3’): they are anti parallel, with the 5’ termination of one strand coupled with the 3’ termination of the other, and vice versa Strand 3’ Strand 5’ Nucleobases
The genetic material 14 • Example If the nucleotide sequence of one strand is 5’GTATCC3’, the complementary strand sequence will be 3’CATAGG5’ (or, by convention, 5’GGATAC3’) • Characteristic sequences placed in position 5’ or 3’ with respect to a given reference point are commonly defined upstream and downstream, respectively
The central dogma of molecular biology 1 • Although the specific nucleotide sequence of a DNA molecule contains fundamental information, actually the enzymes act as catalysts, continually changing and adapting the chemical environment of the cells • Catalysts are molecules that allow specific chemical reactions to proceed faster: they don’t fray, or alter, and can therefore be used repeatedly to catalyze the same reaction
The central dogma of molecular biology 2 • The instructions needed to describe the enzymatic catalysts produced by the cell are contained in the genes • The process of extracting information from the genes for the construction of the enzymes is shared by all living organisms • In detail: the information preserved in the DNA is used to synthesize a transient singlestranded polynucleotide molecule, called RNA (ribonucleic acid) which, in turn, is employed for synthesizing proteins
The central dogma of molecular biology 3 • The process of copying a gene into RNA is called transcription and is realized through the enzymatic activity of an RNA polymerase • A onetoone correspondence is established between the nucleotides G, A, U (uracil), C of the RNA and G, A, T, C of the DNA • The conversion process from the RNA nucleotide sequence to the amino acid sequence, that constitutes the protein, is called translation; it is carried out by an ensemble of proteins and RNA, called ribosomes
The central dogma of molecular biology 4 Transcription from DNA to RNA via RNA polymerase
Gene’s structure 1 • All the cells interpret the genetic instructions in the same way, thanks to the presence of specific signals used as punctuation marks between genes • The DNA code was developed at the beginning of the history of life on the Earth and has undergone a few changes over the course of millions of years • Both prokaryotic organisms (bacteria) and eukaryotes (complex organisms like yeasts, plants, animals and humans) use the same alphabet of nucleotides and almost the same format and methods to store and use genetic information
Gene’s structure 2 Structure of a prokaryotic cell (left) and of a eukaryotic animal cell (right)
Gene’s structure 3 • The gene expressionis the process that uses the information stored in the DNA to construct an RNA molecule that, in turn, encodes a protein • Significant energy waste for the cell • Organisms that express unnecessary proteins compete unfavorably for their subsistence, compared to organisms that regulate their gene expression more effectively • RNA polymerases are responsible for the activation of the gene expression through the synthesis of RNA copies of the gene
Gene’s structure 4 • The RNA polymerase must be able to: • reliably distinguish the beginning of the gene • determine which genes encode for needfull proteins • The RNA polymerase cannot search for a particular nucleotide, because each nucleotide is randomly located in any part of the DNA • The prokaryotic RNA polymerase examines a DNA sequence searching a specific sequence of 13 nucleotides • 1 nucleotide serves as the start site for transcription • 6 nucleotides are located 10 nucleotides upstream of the start site • 6 nucleotides are located 35 nucleotides upstream of the start site • Promoter sequence of the gene
Gene’s structure 5 • Because prokaryotic genomes are long a few million nucleotides, promoter sequences, that can be found randomly only once every 70 million nucleotides, allow RNA polymerase to identify the beginning of a gene in a statistically reliable way • The genome of eukaryotes is several orders of magnitude longer: the RNA polymerase must recognize longer and more complex promoter sequences in order to locate the beginning of a gene
Gene’s structure 6 • In the early ‘60s, F. Jacob and J. Monod two French biochemists were the first to obtain experimental evidence on how cells distinguish between genes that should or should not be transcribed • Their work on the regulation of prokaryotic genes (Nobel 1965) revealed that the expression of the structural genes (coding for proteins involved in cell structure and metabolism) is controlled by specific regulatory genes • Proteins encoded by the regulatory genes are able to bind to cellular DNA only near the promoter sequence and only if it is required by the interaction with the external environment of structural genes whose expression they control
Gene’s structure 7 • When the chemical bond established between DNA and proteins facilitates the initiation of the transcription phase, by the RNA polymerase, it occurs a positive regulation; instead, the regulation is negative when such bond prevents the transcription • The structural genes in prokaryotes are activated/ deactivated by one or two regulatory proteins • Eukaryotes use an esemble of seven (or more) proteins
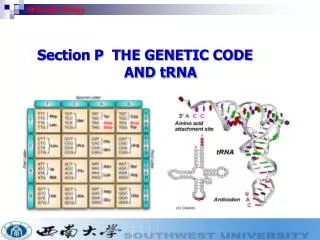
The genetic code 1 • While nucleotides are the basic units used by the cell to maintain the information (DNA) and to build molecules capable of transfer it (RNA), the amino acids are the basic units to build up proteins • The protein function is strongly dependent on the order in which the amino acids are translated and bonded by the ribosomes Chemical structure of an amino acid: the amino group, the carbon, and the carboxyl group are identical for all the amino acids, which differ instead with respect to the Rgroup (side chain)
The genetic code 2 • However, even if in constructing the DNA and RNA molecules only four nucleotides are used, for the proteins’ synthesis, 20 amino acids are needed
The genetic code 3 • Therefore, there cannot be a onetoone relation between the nucleotides and the amino acids that they encode, nor can there be a correspondence between pairs of nucleotides (at most 16 different combinations) and amino acids • Ribosomes must use a code based on triplets • With only three exceptions, each group of three nucleotides, a codon, in an RNA copy of the coding portion of a gene, corresponds to a specific amino acid • The three codons that do not indicate to the ribosomes to insert an amino acid are stop codons
The genetic code 4 For a limited number of bacterial genes, UGA encodes a twenty-first amino acid, selenocysteine; a twenty-second amino acid, pyrrolysine, is encoded by UAG in some bacterial and eukaryotic species
The genetic code 5 • Amino acids are classified into four different categories • Nonpolar Rgroups, hydrophobic: glycine, alanine, valine, leucine, isoleucine, methionine, phenyla-lanine, tryptophan, proline • Polar Rgroups,hydrophilic: serine, threonine, cysteine, tyrosine, asparagine, glutamine • Acid (negatively charged): aspartic acid, glutamic acid • Basic (positively charged): lysine, arginine, histidine
The genetic code 6 Hydrophobic Glycine Aromatic Imino acid Sulfur Subject to Oglycosilation Hydrophilic Positively charged Negatively charged
The genetic code 7 • 18 out of 20 amino acids are encoded by more than one codon: this redundancy of the genetic code is called degeneracy • A single change in a codon is usually insufficient to cause the encoding of an amino acid of a different class • That is, during the replication/transcription of the DNA, mistakes may occur that do not affect the amino acid composition of the protein • The genetic code is very robust and minimize the consequences of possible errors in the nucleotide sequence, avoiding devastating impacts on the encoded protein function
The genetic code 8 • The translation, by the ribosomes, is effected from a start site, located on the RNA copy of a gene, and proceeds until the first stop codon is encountered • The start codonis the triplet AUG (which also encodes for methionine), both in eukaryotes and in prokaryotes • The translation is accurate only when the ribosomes examine the codons contained inside the open reading frame (delimited by the start and the stop codon, respectively) • The alteration of the reading frame changes each amino acid situated downstream with respect to the alteration itself, and usually causes a truncated version of the protein
The genetic code 9 • Most of the genes encode for proteins composed by hundreds of amino acids • In a randomly generated sequence, stop codons will appear approximately every 20 triplets (3 codons out of 64), whereas the reading frames, representing genes, usually are very long sequences not containing stop codons • The Open Reading Frames (ORFs) are a distinctive feature of many genes in both prokaryotes and eukaryotes
Introns and exons 1 • The messenger RNA (mRNA) copies of prokaryotic genes correspond perfectly to the DNA sequences of the genome (with the exception of uracil, which is used in place of thymine), and the steps of transcription and translation are partially overlapped • In eukaryotes, the two phases of gene expression are physically separated by the nuclear membrane: the transcription occurs in the nucleus, whereas the translation starts only after that the mRNA has been transported into the cytoplasm • RNA molecules transcribed by the eukaryotic polymerase may be significantly modified before that ribosomes initiate their translation
Introns and exons 2 • The most striking change that affects the primary transcript of eukaryotic genes is splicing, which involves the introns cutting and the reunification of the exons which border them • Most eukaryotic genes contain a very high number of introns • Example:the gene associated with the human cystic fibrosis has 24 introns and is long more than a million base pairs, while the mRNA trans-lated by the ribosomes is made up of about a thousand nucleobases
Introns and exons 4 • The majority of eukaryotic introns follows the GTAG rule, according to which the introns begin with the dinucleotideGT and end with the dinucleotideAG • A failure in the correct splicing of introns from the primary transcript of eukaryotic RNA can: • introduce a shift of the reading frame • generate the transcription of a premature stop codon • Inoperability of the translated protein
Introns and exons 5 • Pairs of nucleotides are statistically too frequent to be considered as a sufficient signal for the recognition of introns by the splicesome(the ensemble of proteins devoted to splicing) • Six additional nucleotides, at the endpoints 5’ and 3’, are examined, which can be different for different cells • Alternative splicing:increasing of the protein biodiversity caused by the modification of the splicesome and by the presence of accessory proteins responsible for the recognition of the intron/exonneighborhood • A single gene codes for multiple proteins (for instance in different tissues)
Introns and exons 6 Alternative splicing allows the human genome to direct the synthesis of many more proteins than would be expected from its 20,000 proteincoding genes; actually, in humans, ~95% of multiexonic genes are alternatively spliced
The proteins’ function • The functions of proteins are incredibly diversified • Structural proteins, such as collagen, provide support to the bones and to the connective tissues • Enzymes act as biological catalysts, such as pepsin, which regulates the metabolism • Proteins are also responsible for the transport of atoms and molecules through the body (hemo-globin), for signals and intercellular communication (insulin), for the absorption of photons by the visual apparatus (rhodopsin), for the activation of muscles (actin and myosin), etc.
The primary structure 1 • Following the instructions contained in the mRNA, ribosomes translate a linear polymer (chain) of amino acids • The 20 amino acids have a similar chemical structure and differ only according to the Rgroup • The structural region common to all amino acids is called the main chain or the backbone, while the different Rgroups constitute the side chains • The linear, ordered, chain in which the amino acids are assembled in a protein constitutes its primary structure
The primary structure 2 • The protein chain has a direction • At one end of the chain there is a free amino group (NH), while, at the other termination, there is a carboxyl group (COOH) • The chain goes from the aminoterminal(which is the first to be synthesized) to the carboxyterminal Peptide bonds formation Peptide bond Primary structure