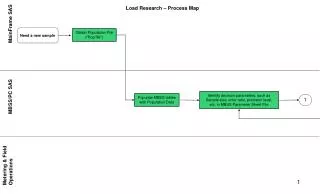
Download
1 / 22
230 likes | 466 Views
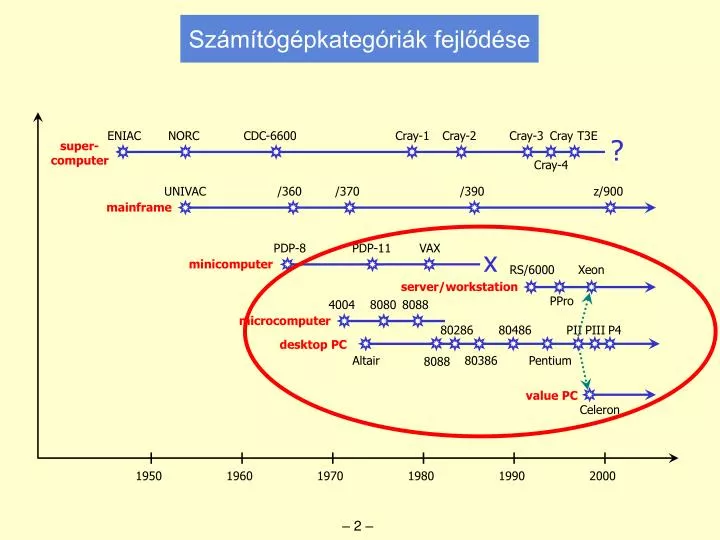
Számítógépkategóriák fejlődése. ENIAC. NORC. CDC-6600. Cray-1. Cray-2. Cray-3. Cray T3E. ?. super- computer. Cray-4. UNIVAC. /360. /370. /390. z/900. mainframe. PDP-8. PDP-11. VAX. x. minicomputer. RS/6000. Xeon. server/workstation. PPro. 4004. 8080. 8088.

E N D
Számítógépkategóriák fejlődése ENIAC NORC CDC-6600 Cray-1 Cray-2 Cray-3 Cray T3E ? super- computer Cray-4 UNIVAC /360 /370 /390 z/900 mainframe PDP-8 PDP-11 VAX x minicomputer RS/6000 Xeon server/workstation PPro 4004 8080 8088 microcomputer 80286 80486 PII PIII P4 desktop PC Altair 80386 Pentium 8088 value PC Celeron 1950 1960 1970 1980 1990 2000 – 2 –
1. A fejlődés áttekintése az Intel x86 processzorcsaládja esetén (1) 1. ábra: Az x86 alapú Intel processzorok fixpontos teljesítménye
Figure 22: Performance increase of RISC processors Source: Microprocessor Report Jan. 23, 1995
1. A fejlődés áttekintése az Intel x86 processzorcsaládja esetén (2) 2. ábra: Az x86 alapú Intel processzorok órafrekvenciája
1. A fejlődés áttekintése az Intel x86 processzorcsaládja esetén (3) 3/a. ábra: Az x86 alapú processzorok közelítő hatékonysága (az 1. és a 2. ábrák közelítéseiből levezetve)
Utasításon belülipárhuzamosműveletvégzés Szuperskalárfeldolgozás elve VLIWfeldolgozás elve Párhuzamoskibocsátás Időben átlapoltfeldolgozás utasítások független utasítások(statikus függőségkezelés) függő utasítások dinamikusfüggőség kezelés Futószalagprocesszorok VLIW (EPIC)processzorok Szuperskalárprocesszorok SIMDkiterjesztés F E F E F E F E F E F E Processzor Processzor VLIW: Very Large Instruction Word SIMD: Single Instruction / Multiple Data 2. Az utasításszinten párhuzamos feldolgozás (ILP) Feldolgozási alternatívák Új ISA! Kompatibilis ISA – 4 –
Abszolut teljesítmény Ideális esetben Valós esetben Soros Futószalag Szuperskalár/VLIW SIMD kiterjesztéssel 2.1 Az ILP processzorok teljesítménye – 6 –
A processzor szintű architektúra hatékonysága (ISA- és mikroarchitektúra) Elsődlegesen technológiafüggő f c ILP processzorok abszolut teljesítményének összetevői 1 = * * * P O Időben átlapoltfeldolgozás (Időbeni párhuzamosság) Órajelfrekvencia Utasításon belülipárh. műveletvégzés (Utasításon belüli párhuzamosság) Párhuzamoskibocsátás (Kibocsátási párhuzamosság) – 7 –
Szuperskalár MM/3D támogatással Szuperskalár Futószalag Soros ILP processzorok mikroarchitektúrájának fejlődése Fő vonulat – 5 –
Az időbeli párhuzamosság megvalósításának fontosabb alternatívái (F: fetch cycle, D: decode cycle, E: execute cycle, W: write cycle) – 16 –
VLIW (EPIC)utasítás kibocsátás (Statikus függőségfeloldás) Szuperskalárutasítás kibocsátás (Dinamikus függőségfeloldás) Kompatibilis Új ISA 2.4 A kibocsátási párhuzamosság bevezetése Párhuzamos utasításkibocsátás Futószalag feldolgozás – 24 –
Első generációs„keskeny” szuperskalárok Jellemzők: Szélesség: • 2-3 RISC utasítás/ciklus vagy2 CISC utasítás/ciklus „széles” Proc. mag: • Statikus elágazásbecslés Gyorsítótár: • Egyportos, blokkoló L1 adat-gyorsítótár • Processzor buszon keresztül csatolt L2 gyorsítótár • Alpha 21064 Példák: • PA 7100 • Pentium – 26 –
A kibocsátási párhuzamosság bevezetésénekkezdeti megvalósítása (direkt kibocsátás) Elve: (a): Simplified structure of the mikroarchitekture assuming direct issue (b): The issue process A kibocsátási párhuzamosság miatt megjelenő szűk keresztmetszetek • A direkt kibocsátás miatt kialakuló kibocsátási szűk keresztmetszet – 27 –
Kiegészítő technikák megjelenése a fellépő szűk keresztmetszetek kiküszöbölésére Második generációs (széles) szuperskalárok – 28 –
Szuperskalár processzorok Első generációs„keskeny” szuperskalárok Második generációs „széles” szuperskalárok Jellemzők: Szélesség: • 2-3 RISC utasítás/ciklus vagy2 CISC utasítás/ciklus „széles” • 4 RISC utasítás/ciklus vagy3 CISC utasítás/ciklus „széles” Proc. mag: • Statikus elágazásbecslés • Elődekódolás • Dinamikus elágazásbecslés • Pufferelt kibocsátás • Reg. átnevezés • ROB Gyorsítótár: • Egyportos, blokkoló L1 adat-gyorsítótár • Processzor buszon keresztül csatolt L2 gyorsítótár • Kétportos, nem blokkoló L1adat-gyorsítótár • Közvetlen csatolású L2 gyorsítótár • Alpha 21064 Példák: • Alpha 21264 • PA 7100 • PA 8000 • Pentium • Pentium Pro • K6 – 29 –
A második generációs szuperskalárokkal zömében kiaknázhatóvá vált az általános célú programokban rendelkezésre álló párhuzamosság. – 30 –
2.5 Az utasításon belüli párhuzamosság bevezetése Szuperskalár feldolgozás Utasításon belülipárhuzamos műveletvégzés(SIMD utasítások) SIMD: Single Instructions Multiple Data – 31 –
Az FX-SIMD és FP-SIMD utasítások megjelenése mikroprocesszorokban – 33 –
2.6. Az ILP processzorok fejlődésének áttekintése(Összegzés) • Az ILP processzorok fejlődése három szakaszban ment végbe, ahol minden egyes szakasz • a párhuzamosság egy-egy lehetséges dimenziójának bevezetéséből, • a bevezetésből adódó feldolgozási szűk keresztmetszetek megszüntetése érdekében kiegészítő technikák kifejlesztéséből és alkalmazásából, és ezáltal • az adott dimenzióban rendelkezésre álló párhuzamosítási lehetőségek kimerüléséből áll. • A mikroprocesszorok fejlődésének folyamata lényeges vonásaiban eleve determinált volt! – 37 –