Download

1 / 68
680 likes | 804 Views
Steepest Decent and Conjugate Gradients (CG). Steepest Decent and Conjugate Gradients (CG). Solving of the linear equation system. Steepest Decent and Conjugate Gradients (CG). Solving of the linear equation system Problem : dimension n too big, or not enough time for gauss elimination

E N D
Steepest Decent and Conjugate Gradients (CG) • Solving of the linear equation system
Steepest Decent and Conjugate Gradients (CG) • Solving of the linear equation system • Problem: dimension n too big, or not enough time for gauss elimination Iterative methods are used to get an approximate solution.
Steepest Decent and Conjugate Gradients (CG) • Solving of the linear equation system • Problem: dimension n too big, or not enough time for gauss elimination Iterative methods are used to get an approximate solution. • Definition Iterative method: given starting point , do steps hopefully converge to the right solution
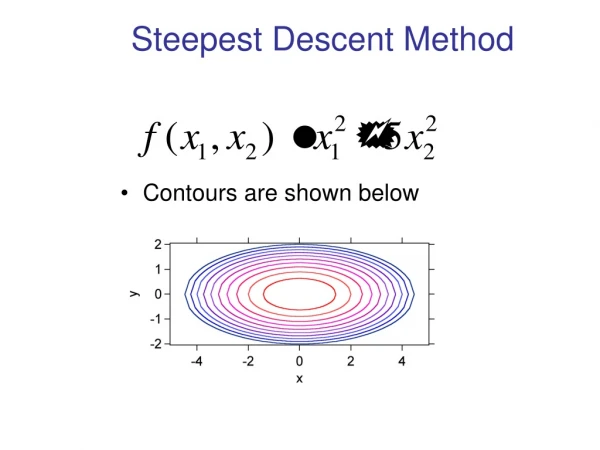
starting issues • Solving is equivalent to minimizing
starting issues • Solving is equivalent to minimizing • A has to be symmetric positive definite:
starting issues • If A is also positive definite the solution of is the minimum
starting issues • If A is also positive definite the solution of is the minimum
starting issues • error: The norm of the error shows how far we are away from the exact solution, but can’t be computed without knowing of the exact solution .
starting issues • error: The norm of the error shows how far we are away from the exact solution, but can’t be computed without knowing of the exact solution . • residual: can be calculated
Steepest Decent • We are at the point . How do we reach ?
Steepest Decent • We are at the point . How do we reach ? • Idea: go into the direction in which decreases most quickly ( )
Steepest Decent • We are at the point . How do we reach ? • Idea: go into the direction in which decreases most quickly ( ) • how far should we go?
Steepest Decent • We are at the point . How do we reach ? • Idea: go into the direction in which decreases most quickly ( ) • how far should we go? Choose so that is minimized:
Steepest Decent • We are at the point . How do we reach ? • Idea: go into the direction in which decreases most quickly ( ) • how far should we go? Choose so that is minimized:
Steepest Decent • We are at the point . How do we reach ? • Idea: go into the direction in which decreases most quickly ( ) • how far should we go? Choose so that is minimized:
Steepest Decent • We are at the point . How do we reach ? • Idea: go into the direction in which decreases most quickly ( ) • how far should we go? Choose so that is minimized:
Steepest Decent • We are at the point . How do we reach ? • Idea: go into the direction in which decreases most quickly ( ) • how far should we go? Choose so that is minimized:
Steepest Decent • We are at the point . How do we reach ? • Idea: go into the direction in which decreases most quickly ( ) • how far should we go? Choose so that is minimized:
Steepest Decent one step of steepest decent can be calculated as follows:
Steepest Decent one step of steepest decent can be calculated as follows: • stopping criterion: or with an given small It would be better to use the error instead of the residual, but you can’t calculate the error.
Steepest Decent Method of steepest decent:
Steepest Decent • As you can see the starting point is important!
Steepest Decent • As you can see the starting point is important! When you know anything about the solution use it to guess a good starting point. Otherwise you can choose a starting point you want e.g. .
Steepest Decent - Convergence • Definition energy norm:
Steepest Decent - Convergence • Definition energy norm: • Definition condition: ( is the largest and the smallest eigenvalue of A)
Steepest Decent - Convergence • Definition energy norm: • Definition condition: ( is the largest and the smallest eigenvalue of A) convergence gets worse when the condition gets larger
Conjugate Gradients • is there a better direction?
Conjugate Gradients • is there a better direction? • Idea: orthogonal search directions
Conjugate Gradients • is there a better direction? • Idea: orthogonal search directions
Conjugate Gradients • is there a better direction? • Idea: orthogonal search directions • only walk once in each direction and minimize
Conjugate Gradients • is there a better direction? • Idea: orthogonal search directions • only walk once in each direction and minimize maximal n steps are needed to reach the exact solution
Conjugate Gradients • is there a better direction? • Idea: orthogonal search directions • only walk once in each direction and minimize maximal n steps are needed to reach the exact solution has to be orthogonal to
Conjugate Gradients • example with the coordinate axes as orthogonal search directions:
Conjugate Gradients • example with the coordinate axes as orthogonal search directions: Problem: can’t be computed because (you don’t know !)
Conjugate Gradients • new idea: A-orthogonal
Conjugate Gradients • new idea: A-orthogonal • Definition A-orthogonal: A-orthogonal (reminder: orthogonal: )
Conjugate Gradients • new idea: A-orthogonal • Definition A-orthogonal: A-orthogonal (reminder: orthogonal: ) • now has to be A-orthogonal to
Conjugate Gradients • new idea: A-orthogonal • Definition A-orthogonal: A-orthogonal (reminder: orthogonal: ) • now has to be A-orthogonal to
Conjugate Gradients • new idea: A-orthogonal • Definition A-orthogonal: A-orthogonal (reminder: orthogonal: ) • now has to be A-orthogonal to can be computed!
Conjugate Gradients • A set of A-orthogonal directions can be found with n linearly independent vectors and conjugate Gram-Schmidt (same idea as Gram-Schmidt).
Conjugate Gradients • Gram-Schmidt: linearly independent vectors
Conjugate Gradients • Gram-Schmidt: linearly independent vectors
Conjugate Gradients • Gram-Schmidt: linearly independent vectors • conjugate Gram-Schmidt:
Conjugate Gradients • A set of A-orthogonal directions can be found with n linearly independent vectors and conjugate Gram-Schmidt (same idea as Gram-Schmidt). • CG works by setting (makes conjugate Gram-Schmidt easy)