Download
1 / 80
810 likes | 903 Views
Learn about the construction, hashing functions, collision resolution, and Java implementation of hash tables for storing distinct integers efficiently.

E N D
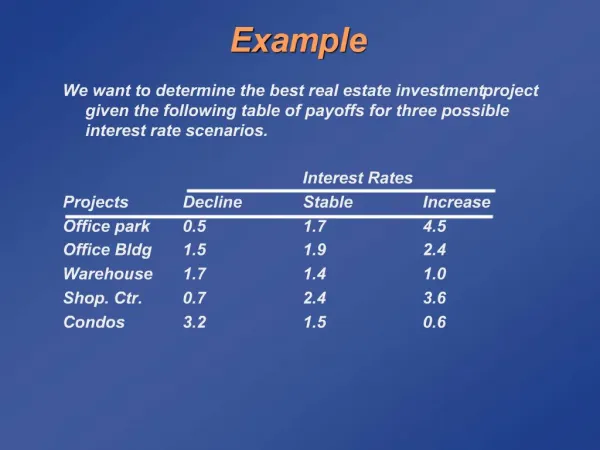
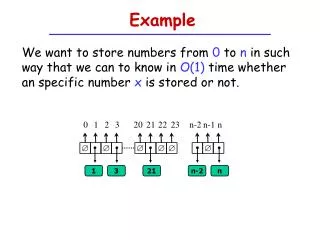
Example We want to store numbers from 0 to n in such way that we can to know in O(1) time whether an specific number x is stored or not. 0 1 2 3 20 21 22 23 n-2 n-1 n 1 3 21 n-2 n
Example What happen if e numbers to be stored are the 7 digit student i.d. ? 0 1 2 0000002 3 If the i.d. were used unmodified, the array would have to have enough room for 10,000,000 student records. 4 0000004 … 7519998 7519998 9999998 7519998 9999999
0 1 6120001 2 1010002 3 4 2290004 … 9997 9998 7519998 9999 Example What if instead, student i.d.’s are “hashed” to produce an integer between, say 1 and 10,000 which indexes into an array. Since a possible 10,000,000 numbers are being compressed into just 10,000 how can we guarantee that no 2 i.d.’s end up stored in the same place?
Hashtables Hashing is one of the most widely-used techniques in computer science Data structures Error detection Security • Hash tables are one of the most useful data structures • store integers • or data that can be converted to integers (via hashCode()) • allow for exact search only • data is either there or its not (e.g., Set, Map)
Construction of the function h(Ki) • Simple to calculate • Uniformly distribute the elements in the table ProblemA AddressGeneration ProblemB CollisionResolution • What strategy to use if two keys map to same location h(Ki)
Hashing with chaining Data is stored in an array of lists (table) Data value x is stored in the list table[hash(x)] table 0 f 1 1 a g b x hash(x) = 1 2 publicclassHashTable<T> extendsAbstractCollection<T> { List<T>[] table; // data goes in these intn; // total number of elements ... } 3 c 4 e a b b 5 d 6 7 a a
Hashtables and hashCode() Hash tables are really designed to store distinct integers. • Java has lots of types that are not integers • Every class has a method • publicinthashCode() that converts an object into an integer. • All classes must guarantee that the methods equals() and hashCode() guarantee: • If x.equals(y) then x.hashCode() = y.hashCode()
The hashing process Java object hashCode() {-231,...,231-1} (32 bits) hash() {0,...,table.length-1}
List size distribution For good performance we need a good hash function • Universal hashing assumption: • if x.hashCode() ≠ y.hashCode() then • Pr{hash(x) = hash(y)} <c/table.size • The expected length of table[hash(x)] is • ≤ k + c(n-k)/table.size • where k is the number of elements y such that x.hashCode() = y.hashCode() Pr{} means “the probability that ”
List size distribution (cont'd) If all hashCode()s are unique then k=1 The expected length of the list table[hash(x)] is at most 1 + c(n-1)/table.length • If we keep table.length > n, then • The expected length of table[hash(x)] is • at most 1 + c n/table.size() is called the occupancy or load factor
Hash table insertion • To add x to a hash table we store x in table[hash(x)] • Takes constant time publicboolean add(T x) { if (n+1 > table.length) grow(); table[hash(x)].add(x); n++; returntrue; }
Hash table search • To find elements equal to x, we search the list table[hash(x)] • Time is O(1 + occupancy) public T find(Object x) { for (T y : table[hash(x)]) if (y.equals(x)) return y; returnnull; } Remember: all elements equal to x have the same hashCode()
Hash table search • We can also find all items equal to x public List<T> findAll(Object x) { List<T> l = newLinkedList<T>(); for (T y : table[hash(x)]) if (y.equals(x)) l.add(y); return l;
Hash table removal • Remove all elements equal to x • takes O(1 + k) time k = # elements equal to x publicintremoveAll(Object x) { int r = 0; Iterator<T> it = table[hash(x)].iterator(); while (it.hasNext()) { T y = it.next(); if (y.equals(x)) { it.remove(); n--; r++; } } return r; }
Hash table removal • Or remove just one element public T removeOne(Object x) { Iterator<T> it = table[hash(x)].iterator(); while (it.hasNext()) { T y = it.next(); if (y.equals(x)) { it.remove(); n--; return y; } } returnnull; }
Growing and shrinking Hash tables grow and shrink in the same manner as ArrayStacks and ArrayDeques allocate new table add elements into new table • Cost is amortized over add/remove operations • constant amortized cost per operation
The hash(x) function • There are many many possible hash functions • In multiplicative hashingwe use • table.size = 2d is a power of 2 • hash(x) = ((x.hashCode() * z) mod 2w) div 2w-dwhere: • w is the number of bits in an integer and • z is a randomly chosen odd integer in {0,...,2w-1} • Equivalently (in Java w = 32): protectedfinalint hash(Object x) { return (x.hashCode() * z) >>> (w-d); }
Example • w=16, d=10 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 (x=22) (z=44139) 1 1 0 1 0 1 1 0 1 1 0 1 0 1 0 0 (x*z=971058) 0 0 0 0 0 0 1 1 0 1 0 0 0 1 0 1 0 0 0 0 1 1 0 0 0 1 0 0 0 0 1 1 (x*z mod 2w=53554) 1 0 0 0 1 0 1 1 0 0 0 1 0 0 1 1 ((x*z mod 2w)div 2w-d=836) 0 1 0 0 0 1 0 1 0 1 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 (x=22) (z=44139) 1 1 0 1 0 1 1 0 1 1 0 1 0 1 0 0 (x*z=53554) 0 0 0 0 0 0 1 1 0 1 0 0 0 1 0 0 0 0 0 1 1 1 0 0 0 1 0 0 0 0 1 1 1 0 0 0 1 0 (x*z >>> (w-d)=836) 1 1 0 0 0 1 0 0 1 1
Multiplicative Hashing Theorem • Theorem 1: With the multiplicative hash function • if x.hashCode() ≠ y.hashCode() then Pr{hash(x) = hash(y)} ≤ 2/table.length} • Proof sketch: • If x != y, then there are at most 2w-d odd values of zϵ{1,...,2w-1} such that hash(x) = hash(y) • we have 2w/2 choices for z • Pr{hash(x) = hash(y)} = 2w-d / (2w/2) = 2/2d
Multiplicative Hash Table Summary • Theorem 2: With a multiplicative hash table • find(x) takes O(1) expected time • add(x) takes O(1) expected amortized time • remove(x) takes O(1) expected amortized time provided that the table stores elements with distinct hashCode()s
Hash tables and the Set interface • The Set interface is easily implemented as a hash. publicclassMultiplicativeHashSet<T> extendsAbstractSet<T> { MultiplicativeHashTable<T> tab; ... } publicboolean add(T x) { if (tab.contains(x)) { returnfalse; } else { returntab.add(x); } } publicboolean contains(Object x) { returntab.find(x) != null; } publicboolean remove(Object x) { returntab.remove(x); }
Hash tables and the Map interface The Map methods are easily implemented using a hash table. • Use a hash table that stores key/value Pairs. • two Pairs are equal if their keys are equal. • the hashCode() of a Pair is the hashCode() of its key.
Map Pairs class Pair<V> { public Object key; public V value; ... publicboolean equals(Object o) { return ((o instanceof Pair) && key.equals(((Pair)o).key)); } publicinthashCode() { returnkey.hashCode(); } }
Hash Maps public V put(K key, V value) { Pair<V> p = new Pair<V>(key, value); Pair<V> r = tab.removeOne(p); tab.add(p); return (r == null) ? null : r.value; } public V remove(Object key) { Pair<V> p = new Pair<V>(key,null); Pair<V> r = tab.removeOne(p); return (r == null) ? null : r.value; } public V get(Object key) { Pair<V> p = new Pair<V>(key, null); Pair<V> r = tab.find(p); return (r == null) ? null : r.value; }
Hash, Maps and Sets Using multiplicative hashing: • Theorem : A MultiplicativeHashSet supports • contains(x) in O(1)expected time • add(x) and remove(x) in O(1)expected amortized time • Theorem : A MultiplicativeHashMap supports • get(k) in O(1)expected time • put(k,v) and remove(k) in O(1)expectedamortized time Both theorems hold under the assumption that all stored objects have distinct hashCode()s
The hashCode() method Default hashCode() and equals() use memory locations a.equals(b) if and only if a and b refer to the same memory location a.hashCode() is the (integer) memory location of a Therefore each object has a unique hashCode() We run into problems when we override the equals() method
Designing a good hashCode() Recall: x.equals(y) →x.hashCode() = y.hashCode() We would like: x.hashCode() = y.hashCode() →x.equals(y) But we can't always have this hashCode() returns a 32 (or 64) bit integer only 232 (or 264) possible return values Many objects can take on more values than this e.g. there are 280 > 232ASCII strings of length 10
Example of a bad hashCode() This code will be very slow to execute The last for loop takes a loooong time - Why? int n = 100000; Map<Integer,Integer> m = newHashMap<Integer,Integer>(); for (inti = 1; i <= n; i++) { m.put(i,i); } Set<Map.Entry<Integer,Integer>> s = newHashSet<Map.Entry<Integer,Integer>>(); for (Map.Entry<Integer,Integer> e : m.entrySet()) { s.add(e); }
Answer From the Map.Entry documentation: e.hashCode() = e.getKey().hashCode()^e.getValue().hashCode() ^ is the bitwise exclusive-or (XOR) operation publicinthashCode() Returns the hash code value for this map entry. The hash code of a map entry e is defined to be: (e.getKey()==null ? 0 : e.getKey().hashCode()) ^ (e.getValue()==null ? 0 : e.getValue().hashCode()) ...
If the key and value are the same, then e.getKey() = e.getValue() so e.getKey().hashCode() = e.getValue().hashCode() The XOR of two equal values is always 0 a XOR a = 0 So all 100,000 elements have the same hashCode() The hash table degenerates into 1 linked list contains(x) takes O(n) time! Creating the Set takes O(n2) time! Answer table 1 n,n 4,4 3,3 2,2 1,1
There are lots of bad ways to combine hashCode()s XOR: x.hashCode() ^ y.hashCode() always gives 0 if x = y Commutative operators addition, multiplication, bitwise operators x.hashCode() + y.hashCode() gives same value even if we swap x and y e.g. (“Craig”, “James”) versus (“James”, “Craig”) Lots of others bad examples Some bad ideas
Look at all the fields that are compared in the equals() method these, and only these, should be used Recursively compute the hashCode() for each field to get 32-bit values a1,a2,...,ak Output (a1z1+a2z2+a3z3+...+ak-1zk-1+akzk) mod 232 z1,...,zkare randomly chosen 32-bit integers A good hashCode() recipe
A good hashCode() recipe publicinthashCode() { long[] z = {0x2058cc50L, 0xcb19137eL, 0x2cb6b6fdL}; // random longzz = 0xbea0107e5067d19dL; // random long h0 = x0.hashCode() & ((1L<<32)-1); // unsigned int to long long h1 = x1.hashCode() & ((1L<<32)-1); long h2 = x2.hashCode() & ((1L<<32)-1); return (int)(((z[0]*h0 + z[1]*h1 + z[2]*h2)*zz) >>> 32); }
If (a1,...,ak) != (b1,...,bk) then Pr{a.hashCode() = b.hashCode()} ≤3/2w In Java, this means that, using the previous recipe, Pr{x.hashCode() = y.hashCode()}≤3/232 =3/4,294,967,296 Good hashCode() theorem
Random numbers z1,...,zkcan be hard to get If our object includes arrays then we might need a variable amount Another recipe The Prime Field Method • Pick a large prime number p and a randomz in {0,...,p-1}. • h(a1,...,ak) = (a1z0 + a2z1 + ... + akzk-1) mod p • Theorem: If(a1,...,ak) != (b1,...,bk) then • Pr{a.hashCode() = b.hashCode()} ≤ k/p
Hash tables allow for implementations of Set and Map where basic operations take constant expected time Requires a goodhash function Multiplicative hashing is efficient and provably good Requires a goodhashCode() method For x ≠ y, Pr{x.hashCode() = y.hashCode()} < c/2w We can find a lot of bad implementations of hash(x) and hashCode() online even in things like the Java Collections Framework! Hash tables summary
Hash tables and hashCode() use random numbers Should we pick these in advance, or at run-time? In advance: Can get real random numbers from random.org for example Doesn't protect us from an adversarial user At run-time: Harder to get real random numbers usually settle for pseudorandom numbers (java.util.Random) Can help protect against adversarial users Hash tables: some perspectives
Coming up • Skiplists • Interfacesimplemented by skiplists • SortedSet • List • Rope
Skiplists • To get a skip list, start with a list L0 • Toss a coin for each element x in L0 • if heads, then promote x to L1 • Repeat with L1 to make L2, and so on • a sentinel node points to head of each list L7 a L6 a L5 a L4 a h L3 a c h L2 a c h L1 a c f h L0 a b c d e f g h
The size of a Skiplists • Let ni be the number of nodes in Li (excluding sentinel) • The probability that a node x appears in Li is 1/2i • The expected size of Li is therefore n0/2i • The expected size of all lists is therefore • n0 + n0/2 + n0/4 + n0/8 + ... = 2n0 • The expected size of a skiplist with n elements is O(n) n0/2r 2n0 n0 + n0/2 + n0/4 + n0/8 + n0/16 + ... + n0/2r
Search paths • The search path for a node x is defined as follows: • Start at sentinel in highest list and repeat: • while we can go right without overstepping x • go right • go down one list L7 a L6 a L5 a L4 a h L3 a c h L2 a c h L1 a c f h L0 a b c d x f g h
Reverse search paths • Reverse search path for x • Start at x in L0 and repeat • while we can go up • go up • go left search path = reverse search path L7 a L6 a L5 a L4 a h L3 a c h L2 a c h L1 a c f h L0 a b c d x f g h
Search path length • We want to know the expected length of the (reverse) search path • Expected number of steps at level i is at most • #(steps left) + 1 step up • #(coin tosses until getting heads) • = 2 head tails
Search path length (cont’d) • So far, we know that • (expected number of steps at level i) £ 2 • Also • (number of steps at level i) £ ni • (expected #steps at level i) £ n0/2i • So expected number of steps (total) • £ 2log n + n/2log n + n/2(log n)+1 + n/2(log n)+2 + ... • = 2log n + 1 + 1/2 + 1/4 + ... • = 2log n + 2 Llog n, L(log n)+1, L(log n)+2,... L0,...,L(log n)-1
Not very big How big is 2log n + 2?
A skiplist that stores n elements has expected size O(n) the search path for any element has expected length at most 2log n + 2 = O(log n) Starting at the sentinel, we can find the search path for x in O(log n) time if we know when to go right and when to go down Skiplist summary
Don't store copies of the data in L0,L1,L2,... Instead, a skiplist node has a data value x an array of next pointers one for each list Li to which it belongs Implementation class Node { T x; Node[] next; } \ a b c d e f g h
Implementation publicclassSkiplist<T> { class Node { T x; Node[] next; ... } protected Node sentinel; // towers over left side intheight; // number of lists intn; // number of elements Random r; // source of coin tosses ... }
To implement SortedSet we Store the elements of L0 in sorted order Do searches using the search path Iterate by iterating through L0 Implement add(x) and remove(x) Application 1: SortedSet
Follow search path decide whether to go right or down based on comparison Searching protected Node findPred(T x) { Node u = sentinel; int l = height - 1; while (l >= 0) { while (u.next[l] != null && u.next[l].x.compareTo(x) < 0) u = u.next[l]; l--; } return u; }