Download

1 / 20
200 likes | 302 Views
High Performance Direct Pairwise Comparison of Genomic Sequences. Christopher Mueller, Mehmet Dalkilic, Andrew Lumsdaine HiCOMB April 4, 2005 Denver, Colorado. Introduction. Goals Generate data for large format visualization Exploit parallel features present in commodity hardware

E N D
High Performance Direct Pairwise Comparison of Genomic Sequences Christopher Mueller, Mehmet Dalkilic, Andrew Lumsdaine HiCOMB April 4, 2005 Denver, Colorado
Introduction • Goals • Generate data for large format visualization • Exploit parallel features present in commodity hardware • SIMD/vector processors • SMP/multiple processors per machine • Clusters • Genome Comparison • Dot plot is the only complete method for comparing genomes • Often ruled out due to quadratic running time • Size of data has an upper bound and modern hardware is approaching the point where this bound is (almost) within reach • Target Data • DNA sequences, one direction (5’ to 3’) • Target Platform • Apple dual processor G5, Altivec vector processor High-Performance Direct Pairwise Comparison of Large Genomic Sequences
Related Work • BLAST • Apple and Genentech (AGBLAST), 5x speedup using Altivec • Smith-Waterman • Rognes and Seeberg, 6x speedup using MMX • HMMER • Erik Lindahl, 30% improvement using Altivec • Hardware Solutions • Various commercial FPGA solutions exist for different algorithms (e.g., TimeLogic’s DeCypher platform offers BLAST, HMM, SW) High-Performance Direct Pairwise Comparison of Large Genomic Sequences
Normal SIMD 3 3 2 1 4 + 2 2 4 5 9 5 5 6 6 13 SIMD Overview • Single Instruction, Multiple Data • Perform the same operation on many data items at once • Vector registers can be divided according to the data type • The Altivec registers in the G5 are 128 bits wide. • Vector programming using gcc on Apple G5s is one step removed from assembly programming • Functions are thin wrappers around assembly calls • The optimizer does not cover vector operations • Memory loads and stores are handled by the programmer and must be properly byte aligned Image from http://developer.apple.com/hardware/ve High-Performance Direct Pairwise Comparison of Large Genomic Sequences
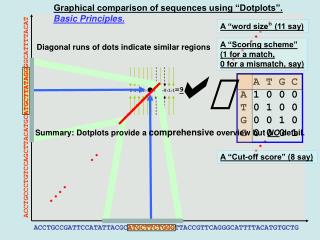
The Dot Plot qseq NAÏVE_DOTPLOT(qseq, sseq, win, strig): // qseq - column sequence // sseq - row sequence // win - number of elements to compare // for each point // strig - number of matches required // for a point for each q in qseq: for each s in sseq: score = 0 for each (q’, s’) in (qseq[q:q+win], s[s:s+win]): if q’ == s’: score += 1 end if q’ end for each (q’,s’) if score > strig: AddDot(q, s) end if score end for each s end for each q sseq win = 3 strig = 2 Dotplot comparing the human and fly mitochondrial genomes (generated by DOTTER) High-Performance Direct Pairwise Comparison of Large Genomic Sequences
The Standard Algorithm STD_DOTPLOT(qScores, s, win, strig): dotvec = zeros(len(q)) for each char c in s: dotvec = shift(dotvec, 1) dotvec += qScores[c] if index(c) > win: delchar = s[index(c) - win] dotvec -= shift(qScores[delchar], win) for each dot in dotvec > strig: display(dot) end for each dot end for i end DOTPLOT High-Performance Direct Pairwise Comparison of Large Genomic Sequences
Data Parallel Dot Plot VECTOR_DOTPLOT(qScores, s, win, strig): // Group diagonals by the upper and lower // triangular sections of the martix for each vector diagonal D: runningScore = vector(0) for each char c in s: score = VecLoad(qScores[c]) runningScore = VecAdd(score, r_score) if index(c) > win: delChar = s[index(c) - win] delscore = VecLoad(qScores[delChar]) runningScore = VecSub(score, delscore) ifVecAnyElementGte(runningScore, strig): scores = VectorUnpack(runningScore) for each score in scores > strig: Output(row(c), col(score), score) end for each score end if VecGte() end for each c end for each D end VECTOR_DOTPLOT High-Performance Direct Pairwise Comparison of Large Genomic Sequences
Coarse Grained Parallelism • Block Level Parallelism • Block the matrix into columns • Overlap by the number of characters in the window • Single Machine • Run one thread per processor • Create one memory mapped file per processor • Cluster • Run one instance per machine and one thread per processor. • Store results locally (e.g. /tmp) High-Performance Direct Pairwise Comparison of Large Genomic Sequences
Model-driven Implementation Goal: Break the algorithm into basic operations that can be modeled independently to understand the performance issues at each step. Data Streams (data read speed) Vector Operations (instruction throughput) Sparse Matrix Format Data output (data write speed) High-Performance Direct Pairwise Comparison of Large Genomic Sequences
Data Stream Models Data Stream Performance (Mops) • Single stream pointer is similar to indexing, but a little slower • For the four score streams, indexed 1/4 of the time, maintaining the pointers costs more than lookup • Pointer vs. Index numbers varied based on the compiler version // Base case // S-sequence is one stream pointer s++; // Q-sequence is four streams uchar *qScore[4]; // Option 1: Four Pointers // Keep pointers to the current // position in the score vectors qScore[0]++; qScore[1]++; qScore[2]++; qScore[3]++; score = *qScore[*s]; // Option 2: Index // Index the score vectors with // a counter i++; score = qScore[*s][i]; High-Performance Direct Pairwise Comparison of Large Genomic Sequences
Vector Performance Models // Model Variables uchar *data = randseq(), out[16]; long i = 0, l = len(data); vector uchar sum = 0, value; // VecAdd for(i = 0; i < l - 16; i++) { value = VecLoad(data[i]); sum = VecAdd(value, sum); } // StoreAll for(i = 0; i < l - 16; i++) { value = VecLoad(data[i]); sum = VecAdd(value, sum); out = VecStore(sum); Save(out); } // StoreFreq int freq = l * alpha; for(i = 0; i < l - 16; i++) { value = VecLoad(data[i]); sum = VecAdd(value, sum); if(i % freq) { // Pipeline stall! out = VecStore(sum); Save(out); } } Vector Model Performance (Mops) • Attempts to model infrequent write operations were unsuccessful • Storing all dots yields high performance, but this is not practical for large comparisons • StoreFreq provides a lower bound on performance High-Performance Direct Pairwise Comparison of Large Genomic Sequences
Pipeline Management // Sequence of Vector Operations // score = VecLoad(qScores[c]) score1 = vec_ld(0, ptemp); // unalgined score2 = vec_ld(16, ptemp); // loads vperm = vec_lvsl(0, ptemp); score = vec_perm(score1, score2, vperm); runningScore = vec_add(score, r_score); // delscore = VecLoad(qScores[delChar]) score1 = vec_ld(0, ptemp); score2 = vec_ld(16, ptemp); vperm = vec_lvsl(0, ptemp); delscore = vec_perm(score1, score2, vperm); runningScore = vec_sub(score, delscore); if(vec_any_ge(runningScore, strig)) { scores = vec_st(runningScore) // Main processor for(i = 0; i < 16; i++) { if(hit[i] > ustrig ) { dm.AddDot(y, x + i, hit[i]); } } } Cycle-accurate Plots of the Instructions in Flight Each line shows each cycle for one instruction. Instructions are offset (x-axis) based on starting time. Time flows from top to bottom (y-axis). The left plot shows a series of add/delete steps with no dots generated. The bottom plot shows the pipeline being interrupted when a dot is generated. High-Performance Direct Pairwise Comparison of Large Genomic Sequences
Sparse Matrix Format Sparse Matrix Format Performance (Mops) • Both approaches required some maintenance to avoid exhausting main memory • mmap avoids a second pass through the data during the save step // Option 1 // std::vector CSR-eqse Sparse Matrix struct Dot { int col; int value; }; struct Row { int num; vector<Dot> cols; }; typedefvector<Row*> DotMatrixVec; // Option 2 // Memory Mapped Coordinate-wise // Sparse Matrix struct RowDot { int row; int col; int value; }; RowDot *out = (RowDot*)mmap(…); 6.78x 3.85x 1.0x High-Performance Direct Pairwise Comparison of Large Genomic Sequences
Data Location Data Location Performance (Mops) • Large, shared data is often located on network drives • This adds a network hop for all disk I/O • Even for infrequent I/O, this can significantly affect performance 1.98x 1.35x 1.0x 1.0x • The std::vector sparse matrix had a slight benefit. • The mmap sparse matrix improved significantly with local data storage. High-Performance Direct Pairwise Comparison of Large Genomic Sequences
Traditional Manual Optimizations • Prefetch • G5 hardware prefetch is very good • Attempts to optimize had negative impact • Blocking • Slight negative impact due to burps in the stream • Unrolling • Complicated code very quickly • No measurable improvement High-Performance Direct Pairwise Comparison of Large Genomic Sequences
System Details • Apple Dual 2.0 GHz G5, 3.5 GB RAM • 100 Mbit network to file server • OS X 10.3.5 (Darwin Kernel Version 7.5.0) • g++ 3.3 (build 1620) • -O3 • -fast (different compiler, aggressive optimizations) • -altivec (limited optimizations) • Upgrade from 1614 to 1620 improved DOTTER’s performance by 30% • Libraries • Boost::thread • Data (from GenBank) • Mitochondrial genomes • E. Coli, Listeria bacterial genomes High-Performance Direct Pairwise Comparison of Large Genomic Sequences
Results Final Results (Mops) • Single Machine • Mitochondrial (~20 kbp) • DOTTER vs. Data-parallel • Bacterial (4.5 Mbp) • Data-parallel only • Cluster (16 dual processor 2.3 GHz G5s) • Bacterial Comparison • 92 min, 8 sec (1 node) • 5 min, 42 sec (16 nodes) 13.0x 7.0x 1.0x Scalability Scalability (time/nodes) High-Performance Direct Pairwise Comparison of Large Genomic Sequences
Visualization • Results rendered to PDF • Target Displays • 2x4, 6400x2400 tiled display wall • IBM T221, 3840x2400, 204 dpi display • Magnifying glass required • High resolution formats • 600 dpi laser printer • 1200 dpi ink jet printer • High resolution, no interactivity High-Performance Direct Pairwise Comparison of Large Genomic Sequences
Conclusions • Modern commodity hardware is close to providing the performance necessary for large direct genomic comparisons. • 5,000,000 base pair sequences are realistic (bacteria) • 50,000,000 base pair sequences are possible (small human chromosomes) • It is important to take a careful, experimental approach to implementation and to test all assumptions. High-Performance Direct Pairwise Comparison of Large Genomic Sequences
Acknowledgements • Jeremiah Willcock helped develop the initial prototype • Eric Wernert, Craig Jacobs, and Charlie Moad from the UITS Advanced Visualization Lab at Indiana University provided visualization support • This work was supported by a grant from the Lilly Endowment • References Apple Developer’s Connection, Velocity Engine and Xcode, from, Apple Developer Connection, Cupertino, CA, 2004. http://developer.apple.com/hardware/vehttp://developer.apple.com/tools/xcode A. J. Gibbs and G. A. McIntyre, The diagram, a method for comparing sequences. Its use with amino acid and nucleotide sequences, Eur J Biochem, 16 (1970), pp. 1-11. E. L. L. Sonnhammer and R. Durbin, A Dot-Matrix Program with Dynamic Threshold Control Suited for Genomic DNA and Protein-Sequence Analysis, Gene-Combis, 167 (1995), pp. 1-10. High-Performance Direct Pairwise Comparison of Large Genomic Sequences